 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPT-LLM: Exploiting Arbitrary-Precision Tensor Core Computing for LLM Acceleration
Aug 26, 2025Large language models (LLMs) have revolutionized AI applications, yet their enormous computational demands severely limit deployment and real-time performance. Quantization methods can help reduce computational costs, however, attaining the extreme efficiency associated with ultra-low-bit quantized LLMs at arbitrary precision presents challenges on GPUs. This is primarily due to the limited support for GPU Tensor Cores, inefficient memory management, and inflexible kernel optimizations. To tackle these challenges, we propose a comprehensive acceleration scheme for arbitrary precision LLMs, namely APT-LLM. Firstly, we introduce a novel data format, bipolar-INT, which allows for efficient and lossless conversion with signed INT, while also being more conducive to parallel computation. We also develop a matrix multiplication (MatMul) method allowing for arbitrary precision by dismantling and reassembling matrices at the bit level. This method provides flexible precision and optimizes the utilization of GPU Tensor Cores. In addition, we propose a memory management system focused on data recovery, which strategically employs fast shared memory to substantially increase kernel execution speed and reduce memory access latency. Finally, we develop a kernel mapping method that dynamically selects the optimal configurable hyperparameters of kernels for varying matrix sizes, enabling optimal performance across different LLM architectures and precision settings. In LLM inference, APT-LLM achieves up to a 3.99$\times$ speedup compared to FP16 baselines and a 2.16$\times$ speedup over NVIDIA CUTLASS INT4 acceleration on RTX 3090. On RTX 4090 and H800, APT-LLM achieves up to 2.44$\times$ speedup over FP16 and 1.65$\times$ speedup over CUTLASS integer baselines.
Enable Lightweight and Precision-Scalable Posit/IEEE-754 Arithmetic in RISC-V Cores for Transprecision Computing
May 25, 2025While posit format offers superior dynamic range and accuracy for transprecision computing, its adoption in RISC-V processors is hindered by the lack of a unified solution for lightweight, precision-scalable, and IEEE-754 arithmetic compatible hardware implementation. To address these challenges, we enhance RISC-V processors by 1) integrating dedicated posit codecs into the original FPU for lightweight implementation, 2) incorporating multi/mixed-precision support with dynamic exponent size for precision-scalability, and 3) reusing and customizing ISA extensions for IEEE-754 compatible posit operations. Our comprehensive evaluation spans the modified FPU, RISC-V core, and SoC levels. It demonstrates that our implementation achieves 47.9% LUTs and 57.4% FFs reduction compared to state-of-the-art posit-enabled RISC-V processors, while achieving up to 2.54$\times$ throughput improvement in various GEMM kernels.
FastMamba: A High-Speed and Efficient Mamba Accelerator on FPGA with Accurate Quantization
May 25, 2025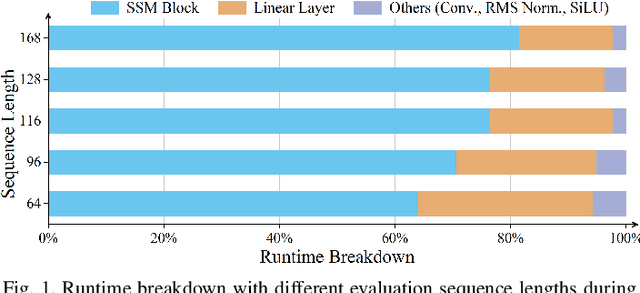
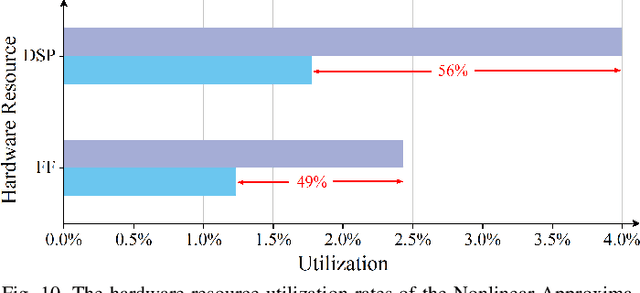
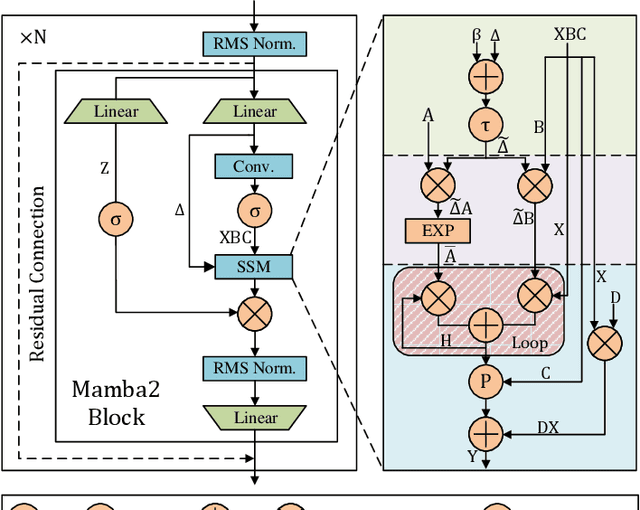
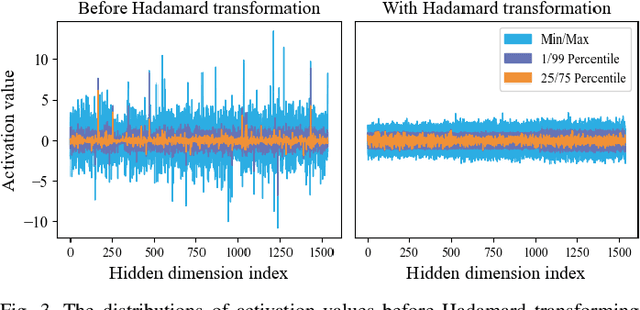
State Space Models (SSMs), like recent Mamba2, have achieved remarkable performance and received extensive attention. However, deploying Mamba2 on resource-constrained edge devices encounters many problems: severe outliers within the linear layer challenging the quantization, diverse and irregular element-wise tensor operations, and hardware-unfriendly nonlinear functions in the SSM block. To address these issues, this paper presents FastMamba, a dedicated accelerator on FPGA with hardware-algorithm co-design to promote the deployment efficiency of Mamba2. Specifically, we successfully achieve 8-bit quantization for linear layers through Hadamard transformation to eliminate outliers. Moreover, a hardware-friendly and fine-grained power-of-two quantization framework is presented for the SSM block and convolution layer, and a first-order linear approximation is developed to optimize the nonlinear functions. Based on the accurate algorithm quantization, we propose an accelerator that integrates parallel vector processing units, pipelined execution dataflow, and an efficient SSM Nonlinear Approximation Unit, which enhances computational efficiency and reduces hardware complexity. Finally, we evaluate FastMamba on Xilinx VC709 FPGA. For the input prefill task on Mamba2-130M, FastMamba achieves 68.80\times and 8.90\times speedup over Intel Xeon 4210R CPU and NVIDIA RTX 3090 GPU, respectively. In the output decode experiment with Mamba2-2.7B, FastMamba attains 6\times higher energy efficiency than RTX 3090 GPU.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025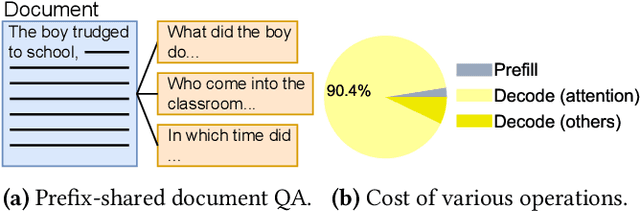
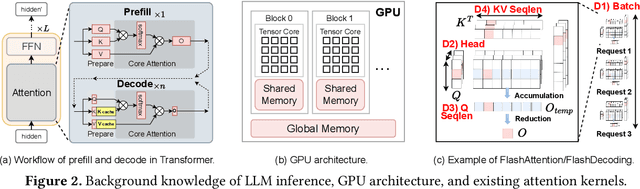
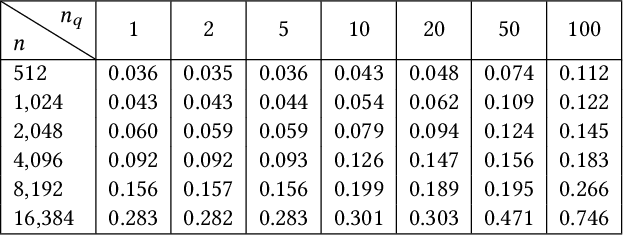
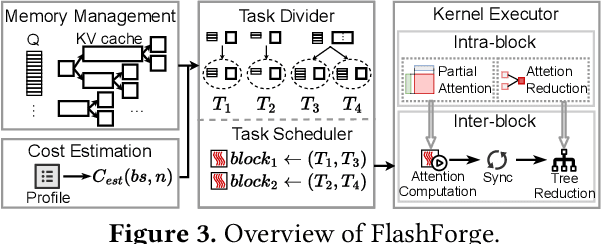
Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.
Block Circulant Adapter for Large Language Models
May 01, 2025Fine-tuning large language models (LLMs) is difficult due to their huge model size. Recent Fourier domain-based methods show potential for reducing fine-tuning costs. We propose a block circulant matrix-based fine-tuning method with a stable training heuristic to leverage the properties of circulant matrices and one-dimensional Fourier transforms to reduce storage and computation costs. Experiments show that our method uses $14\times$ less number of parameters than VeRA, $16\times$ smaller than LoRA and $32\times$ less FLOPs than FourierFT, while maintaining close or better task performance. Our approach presents a promising way in frequency domain to fine-tune large models on downstream tasks.
Parameter-Efficient Fine-Tuning with Circulant and Diagonal Vectors
May 01, 2025Foundation models have achieved tremendous success in different domains. However, their huge computation and storage complexity make these models difficult to fine-tune and also less applicable in practice. Recent study shows training in Fourier domain can be an effective fine-tuning method in terms of both model performance and number of training parameters. In this work, we propose to further reduce the complexity by the factorization through the product of interleaved circulant and diagonal matrices. In addition, we address the case of non-square fine-tuning weights by partitioning the circulant matrix into blocks. Our method avoids the construction of weight change matrix and utilizes 1D fast Fourier transform (FFT) instead of 2D FFT. Experimental results show that our method achieves similar or better performance across various tasks with much less floating-point operations (FLOPs) and the number of trainable parameters.
CDM-QTA: Quantized Training Acceleration for Efficient LoRA Fine-Tuning of Diffusion Model
Apr 08, 2025Fine-tuning large diffusion models for custom applications demands substantial power and time, which poses significant challenges for efficient implementation on mobile devices. In this paper, we develop a novel training accelerator specifically for Low-Rank Adaptation (LoRA) of diffusion models, aiming to streamline the process and reduce computational complexity. By leveraging a fully quantized training scheme for LoRA fine-tuning, we achieve substantial reductions in memory usage and power consumption while maintaining high model fidelity. The proposed accelerator features flexible dataflow, enabling high utilization for irregular and variable tensor shapes during the LoRA process. Experimental results show up to 1.81x training speedup and 5.50x energy efficiency improvements compared to the baseline, with minimal impact on image generation quality.
Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format
Nov 24, 2024The widely-used, weight-only quantized large language models (LLMs), which leverage low-bit integer (INT) weights and retain floating-point (FP) activations, reduce storage requirements while maintaining accuracy. However, this shifts the energy and latency bottlenecks towards the FP activations that are associated with costly memory accesses and computations. Existing LLM accelerators focus primarily on computation optimizations, overlooking the potential of jointly optimizing FP computations and data movement, particularly for the dominant FP-INT GeMM operations in LLM inference. To address these challenges, we investigate the sensitivity of activation precision across various LLM modules and its impact on overall model accuracy. Based on our findings, we first propose the Anda data type: an adaptive data format with group-shared exponent bits and dynamic mantissa bit allocation. Secondly, we develop an iterative post-training adaptive precision search algorithm that optimizes the bit-width for different LLM modules to balance model accuracy, energy efficiency, and inference speed. Lastly, a suite of hardware optimization techniques is proposed to maximally exploit the benefits of the Anda format. These include a bit-plane-based data organization scheme, Anda-enhanced processing units with bit-serial computation, and a runtime bit-plane Anda compressor to simultaneously optimize storage, computation, and memory footprints. Our evaluations on FPINT GeMM operations show that Anda achieves a 2.4x speedup, 4.0x area efficiency, and 3.1x energy efficiency improvement on average for popular LLMs including OPT, LLaMA, and LLaMA-2 series over the GPU-like FP-FP baseline. Anda demonstrates strong adaptability across various application scenarios, accuracy requirements, and system performance, enabling efficient LLM inference across a wide range of deployment scenarios.
TaQ-DiT: Time-aware Quantization for Diffusion Transformers
Nov 21, 2024Transformer-based diffusion models, dubbed Diffusion Transformers (DiTs), have achieved state-of-the-art performance in image and video generation tasks. However, their large model size and slow inference speed limit their practical applications, calling for model compression methods such as quantization. Unfortunately, existing DiT quantization methods overlook (1) the impact of reconstruction and (2) the varying quantization sensitivities across different layers, which hinder their achievable performance. To tackle these issues, we propose innovative time-aware quantization for DiTs (TaQ-DiT). Specifically, (1) we observe a non-convergence issue when reconstructing weights and activations separately during quantization and introduce a joint reconstruction method to resolve this problem. (2) We discover that Post-GELU activations are particularly sensitive to quantization due to their significant variability across different denoising steps as well as extreme asymmetries and variations within each step. To address this, we propose time-variance-aware transformations to facilitate more effective quantization. Experimental results show that when quantizing DiTs' weights to 4-bit and activations to 8-bit (W4A8), our method significantly surpasses previous quantization methods.
M$^2$-ViT: Accelerating Hybrid Vision Transformers with Two-Level Mixed Quantization
Oct 10, 2024



Although Vision Transformers (ViTs) have achieved significant success, their intensive computations and substantial memory overheads challenge their deployment on edge devices. To address this, efficient ViTs have emerged, typically featuring Convolution-Transformer hybrid architectures to enhance both accuracy and hardware efficiency. While prior work has explored quantization for efficient ViTs to marry the best of efficient hybrid ViT architectures and quantization, it focuses on uniform quantization and overlooks the potential advantages of mixed quantization. Meanwhile, although several works have studied mixed quantization for standard ViTs, they are not directly applicable to hybrid ViTs due to their distinct algorithmic and hardware characteristics. To bridge this gap, we present M$^2$-ViT to accelerate Convolution-Transformer hybrid efficient ViTs with two-level mixed quantization. Specifically, we introduce a hardware-friendly two-level mixed quantization (M$^2$Q) strategy, characterized by both mixed quantization precision and mixed quantization schemes (i.e., uniform and power-of-two), to exploit the architectural properties of efficient ViTs. We further build a dedicated accelerator with heterogeneous computing engines to transform our algorithmic benefits into real hardware improvements. Experimental results validate our effectiveness, showcasing an average of $80\%$ energy-delay product (EDP) saving with comparable quantization accuracy compared to the prior work.