 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrchANN: A Unified I/O Orchestration Framework for Skewed Out-of-Core Vector Search
Dec 28, 2025Approximate nearest neighbor search (ANNS) at billion scale is fundamentally an out-of-core problem: vectors and indexes live on SSD, so performance is dominated by I/O rather than compute. Under skewed semantic embeddings, existing out-of-core systems break down: a uniform local index mismatches cluster scales, static routing misguides queries and inflates the number of probed partitions, and pruning is incomplete at the cluster level and lossy at the vector level, triggering "fetch-to-discard" reranking on raw vectors. We present OrchANN, an out-of-core ANNS engine that uses an I/O orchestration model for unified I/O governance along the route-access-verify pipeline. OrchANN selects a heterogeneous local index per cluster via offline auto-profiling, maintains a query-aware in-memory navigation graph that adapts to skewed workloads, and applies multi-level pruning with geometric bounds to filter both clusters and vectors before issuing SSD reads. Across five standard datasets under strict out-of-core constraints, OrchANN outperforms four baselines including DiskANN, Starling, SPANN, and PipeANN in both QPS and latency while reducing SSD accesses. Furthermore, OrchANN delivers up to 17.2x higher QPS and 25.0x lower latency than competing systems without sacrificing accuracy.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025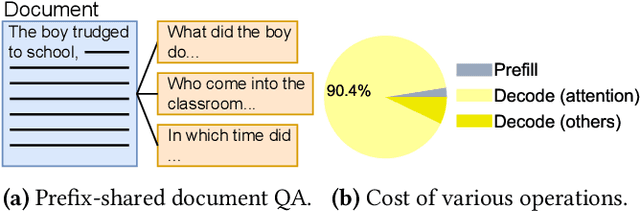
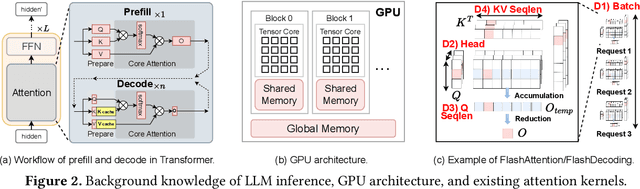
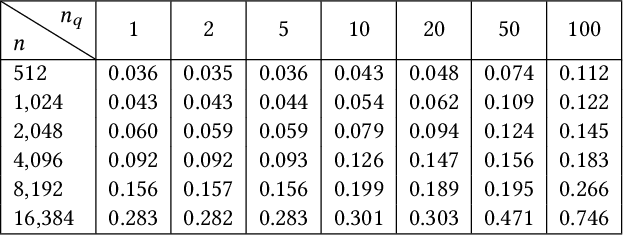
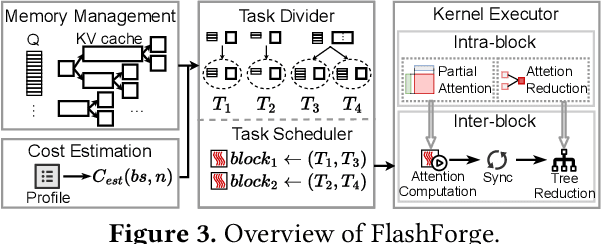
Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.
HyperKAN: Hypergraph Representation Learning with Kolmogorov-Arnold Networks
Mar 16, 2025Hypergraph representation learning has garnered increasing attention across various domains due to its capability to model high-order relationships. Traditional methods often rely on hypergraph neural networks (HNNs) employing message passing mechanisms to aggregate vertex and hyperedge features. However, these methods are constrained by their dependence on hypergraph topology, leading to the challenge of imbalanced information aggregation, where high-degree vertices tend to aggregate redundant features, while low-degree vertices often struggle to capture sufficient structural features. To overcome the above challenges, we introduce HyperKAN, a novel framework for hypergraph representation learning that transcends the limitations of message-passing techniques. HyperKAN begins by encoding features for each vertex and then leverages Kolmogorov-Arnold Networks (KANs) to capture complex nonlinear relationships. By adjusting structural features based on similarity, our approach generates refined vertex representations that effectively addresses the challenge of imbalanced information aggregation. Experiments conducted on the real-world datasets demonstrate that HyperKAN significantly outperforms state of-the-art HNN methods, achieving nearly a 9% performance improvement on the Senate dataset.
Tango: rethinking quantization for graph neural network training on GPUs
Aug 02, 2023



Graph Neural Networks (GNNs) are becoming increasingly popular due to their superior performance in critical graph-related tasks. While quantization is widely used to accelerate GNN computation, quantized training faces unprecedented challenges. Current quantized GNN training systems often have longer training times than their full-precision counterparts for two reasons: (i) addressing the accuracy challenge leads to excessive overhead, and (ii) the optimization potential exposed by quantization is not adequately leveraged. This paper introduces Tango which re-thinks quantization challenges and opportunities for graph neural network training on GPUs with three contributions: Firstly, we introduce efficient rules to maintain accuracy during quantized GNN training. Secondly, we design and implement quantization-aware primitives and inter-primitive optimizations that can speed up GNN training. Finally, we integrate Tango with the popular Deep Graph Library (DGL) system and demonstrate its superior performance over state-of-the-art approaches on various GNN models and datasets.