 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor-Compressed and Fully-Quantized Training of Neural PDE Solvers
Dec 10, 2025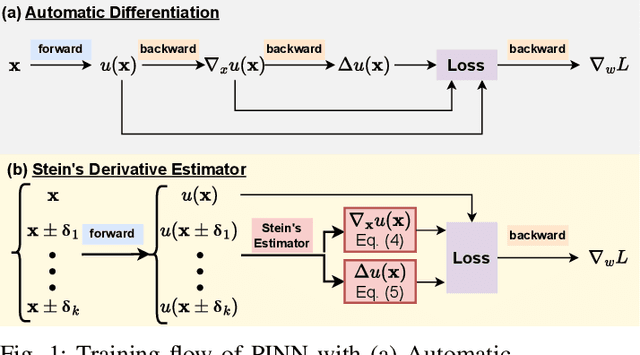
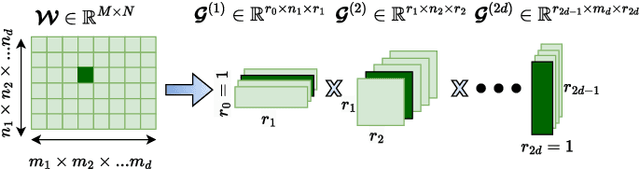
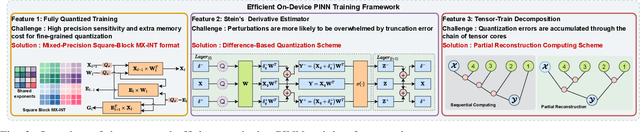
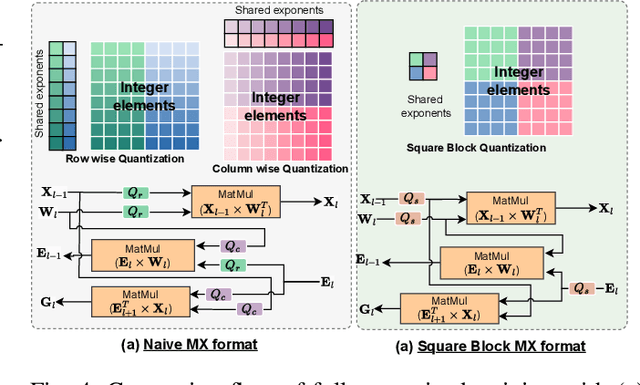
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.
FLAT-LLM: Fine-grained Low-rank Activation Space Transformation for Large Language Model Compression
May 29, 2025Large Language Models (LLMs) have enabled remarkable progress in natural language processing, yet their high computational and memory demands pose challenges for deployment in resource-constrained environments. Although recent low-rank decomposition methods offer a promising path for structural compression, they often suffer from accuracy degradation, expensive calibration procedures, and result in inefficient model architectures that hinder real-world inference speedups. In this paper, we propose FLAT-LLM, a fast and accurate, training-free structural compression method based on fine-grained low-rank transformations in the activation space. Specifically, we reduce the hidden dimension by transforming the weights using truncated eigenvectors computed via head-wise Principal Component Analysis (PCA), and employ an importance-based metric to adaptively allocate ranks across decoders. FLAT-LLM achieves efficient and effective weight compression without recovery fine-tuning, which could complete the calibration within a few minutes. Evaluated across 4 models and 11 datasets, FLAT-LLM outperforms structural pruning baselines in generalization and downstream performance, while delivering inference speedups over decomposition-based methods.
CDM-QTA: Quantized Training Acceleration for Efficient LoRA Fine-Tuning of Diffusion Model
Apr 08, 2025Fine-tuning large diffusion models for custom applications demands substantial power and time, which poses significant challenges for efficient implementation on mobile devices. In this paper, we develop a novel training accelerator specifically for Low-Rank Adaptation (LoRA) of diffusion models, aiming to streamline the process and reduce computational complexity. By leveraging a fully quantized training scheme for LoRA fine-tuning, we achieve substantial reductions in memory usage and power consumption while maintaining high model fidelity. The proposed accelerator features flexible dataflow, enabling high utilization for irregular and variable tensor shapes during the LoRA process. Experimental results show up to 1.81x training speedup and 5.50x energy efficiency improvements compared to the baseline, with minimal impact on image generation quality.
Ultra Memory-Efficient On-FPGA Training of Transformers via Tensor-Compressed Optimization
Jan 11, 2025Transformer models have achieved state-of-the-art performance across a wide range of machine learning tasks. There is growing interest in training transformers on resource-constrained edge devices due to considerations such as privacy, domain adaptation, and on-device scientific machine learning. However, the significant computational and memory demands required for transformer training often exceed the capabilities of an edge device. Leveraging low-rank tensor compression, this paper presents the first on-FPGA accelerator for end-to-end transformer training. On the algorithm side, we present a bi-directional contraction flow for tensorized transformer training, significantly reducing the computational FLOPS and intra-layer memory costs compared to existing tensor operations. On the hardware side, we store all highly compressed model parameters and gradient information on chip, creating an on-chip-memory-only framework for each stage in training. This reduces off-chip communication and minimizes latency and energy costs. Additionally, we implement custom computing kernels for each training stage and employ intra-layer parallelism and pipe-lining to further enhance run-time and memory efficiency. Through experiments on transformer models within $36.7$ to $93.5$ MB using FP-32 data formats on the ATIS dataset, our tensorized FPGA accelerator could conduct single-batch end-to-end training on the AMD Alevo U50 FPGA, with a memory budget of less than $6$-MB BRAM and $22.5$-MB URAM. Compared to uncompressed training on the NVIDIA RTX 3090 GPU, our on-FPGA training achieves a memory reduction of $30\times$ to $51\times$. Our FPGA accelerator also achieves up to $3.6\times$ less energy cost per epoch compared with tensor Transformer training on an NVIDIA RTX 3090 GPU.
Training Deep Neural Networks Using Posit Number System
Sep 06, 2019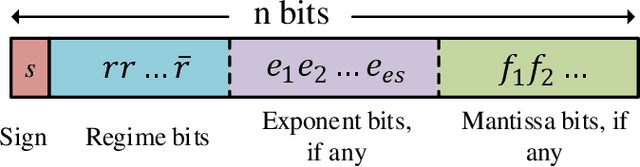
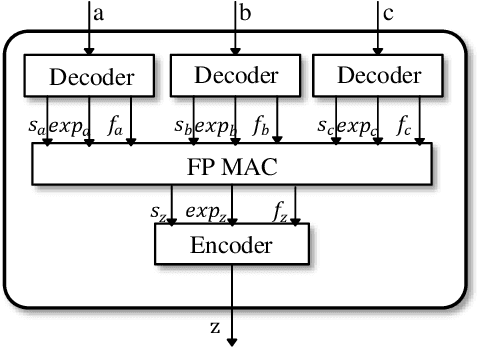
With the increasing size of Deep Neural Network (DNN) models, the high memory space requirements and computational complexity have become an obstacle for efficient DNN implementations. To ease this problem, using reduced-precision representations for DNN training and inference has attracted many interests from researchers. This paper first proposes a methodology for training DNNs with the posit arithmetic, a type- 3 universal number (Unum) format that is similar to the floating point(FP) but has reduced precision. A warm-up training strategy and layer-wise scaling factors are adopted to stabilize training and fit the dynamic range of DNN parameters. With the proposed training methodology, we demonstrate the first successful training of DNN models on ImageNet image classification task in 16 bits posit with no accuracy loss. Then, an efficient hardware architecture for the posit multiply-and-accumulate operation is also proposed, which can achieve significant improvement in energy efficiency than traditional floating-point implementations. The proposed design is helpful for future low-power DNN training accelerators.
A Hardware-Oriented and Memory-Efficient Method for CTC Decoding
May 08, 2019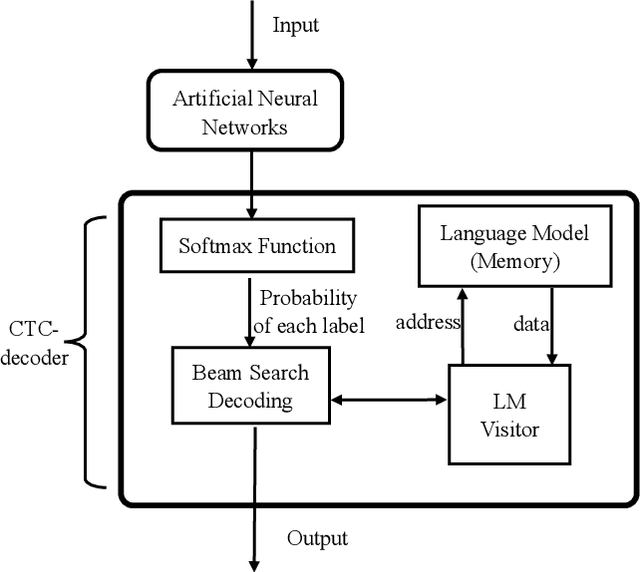
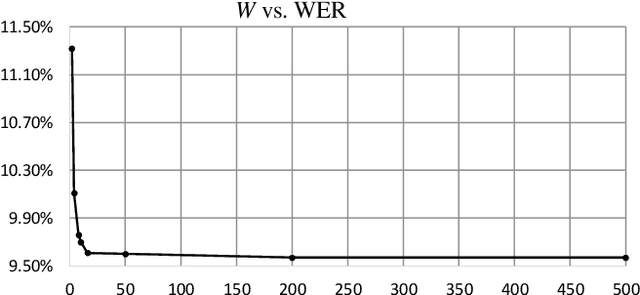
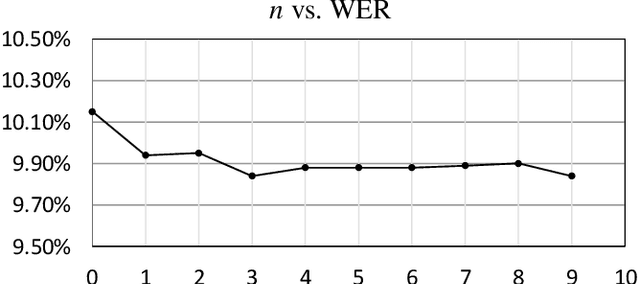
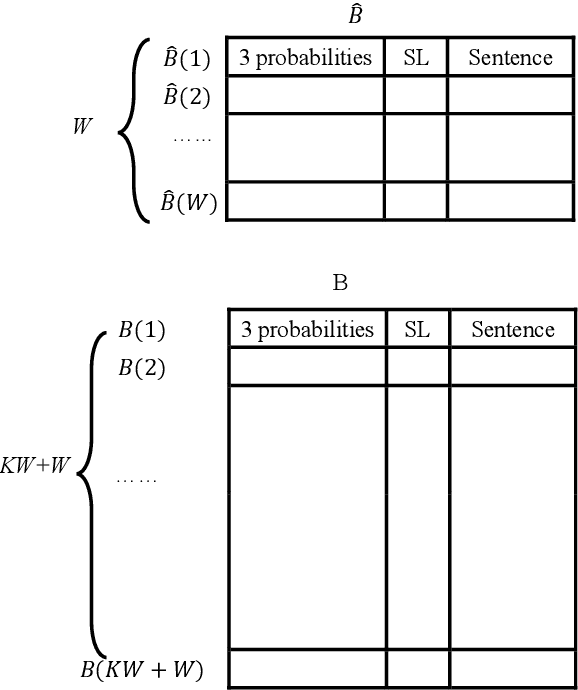
The Connectionist Temporal Classification (CTC) has achieved great success in sequence to sequence analysis tasks such as automatic speech recognition (ASR) and scene text recognition (STR). These applications can use the CTC objective function to train the recurrent neural networks (RNNs), and decode the outputs of RNNs during inference. While hardware architectures for RNNs have been studied, hardware-based CTCdecoders are desired for high-speed CTC-based inference systems. This paper, for the first time, provides a low-complexity and memory-efficient approach to build a CTC-decoder based on the beam search decoding. Firstly, we improve the beam search decoding algorithm to save the storage space. Secondly, we compress a dictionary (reduced from 26.02MB to 1.12MB) and use it as the language model. Meanwhile searching this dictionary is trivial. Finally, a fixed-point CTC-decoder for an English ASR and an STR task using the proposed method is implemented with C++ language. It is shown that the proposed method has little precision loss compared with its floating-point counterpart. Our experiments demonstrate the compression ratio of the storage required by the proposed beam search decoding algorithm are 29.49 (ASR) and 17.95 (STR).