 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSRAMIE: Multimodal Structured Reasoning Agent for Multi-instruction Image Editing
Mar 17, 2026Existing instruction-based image editing models perform well with simple, single-step instructions but degrade in realistic scenarios that involve multiple, lengthy, and interdependent directives. A main cause is the scarcity of training data with complex multi-instruction annotations. However, it is costly to collect such data and retrain these models. To address this challenge, we propose MSRAMIE, a training-free agent framework built on Multimodal Large Language Model (MLLM). MSRAMIE takes existing editing models as plug-in components and handle multi-instruction tasks via structured multimodal reasoning. It orchestrates iterative interactions between an MLLM-based Instructor and an image editing Actor, introducing a novel reasoning topology that comprises the proposed Tree-of-States and Graph-of-References. During inference, complex instructions are decomposed into multiple editing steps which enable state transitions, cross-step information aggregation, and original input recall, which enables systematic exploration of the image editing space and flexible progressive output refinement. The visualizable inference topology further provides interpretable and controllable decision pathways. Experiments show that as the instruction complexity increases, MSRAMIE can improve instruction following over 15% and increases the probability of finishing all modifications in a single run over 100%, while preserving perceptual quality and maintaining visual consistency.
Discovering Process-Outcome Credit in Multi-Step LLM Reasoning
Feb 01, 2026Reinforcement Learning (RL) serves as a potent paradigm for enhancing reasoning capabilities in Large Language Models (LLMs), yet standard outcome-based approaches often suffer from reward sparsity and inefficient credit assignment. In this paper, we propose a novel framework designed to provide continuous reward signals, which introduces a Step-wise Marginal Information Gain (MIG) mechanism that quantifies the intrinsic value of reasoning steps against a Monotonic Historical Watermark, effectively filtering out training noise. To ensure disentangled credit distribution, we implement a Decoupled Masking Strategy, applying process-oriented rewards specifically to the chain-of-thought (CoT) and outcome-oriented rewards to the full completion. Additionally, we incorporate a Dual-Gated SFT objective to stabilize training with high-quality structural and factual signals. Extensive experiments across textual and multi-modal benchmarks (e.g., MATH, Super-CLEVR) demonstrate that our approach consistently outperforms baselines such as GRPO in both sample efficiency and final accuracy. Furthermore, our model exhibits superior out-of-distribution robustness, demonstrating promising zero-shot transfer capabilities to unseen and challenging reasoning tasks.
Ultra Memory-Efficient On-FPGA Training of Transformers via Tensor-Compressed Optimization
Jan 11, 2025Transformer models have achieved state-of-the-art performance across a wide range of machine learning tasks. There is growing interest in training transformers on resource-constrained edge devices due to considerations such as privacy, domain adaptation, and on-device scientific machine learning. However, the significant computational and memory demands required for transformer training often exceed the capabilities of an edge device. Leveraging low-rank tensor compression, this paper presents the first on-FPGA accelerator for end-to-end transformer training. On the algorithm side, we present a bi-directional contraction flow for tensorized transformer training, significantly reducing the computational FLOPS and intra-layer memory costs compared to existing tensor operations. On the hardware side, we store all highly compressed model parameters and gradient information on chip, creating an on-chip-memory-only framework for each stage in training. This reduces off-chip communication and minimizes latency and energy costs. Additionally, we implement custom computing kernels for each training stage and employ intra-layer parallelism and pipe-lining to further enhance run-time and memory efficiency. Through experiments on transformer models within $36.7$ to $93.5$ MB using FP-32 data formats on the ATIS dataset, our tensorized FPGA accelerator could conduct single-batch end-to-end training on the AMD Alevo U50 FPGA, with a memory budget of less than $6$-MB BRAM and $22.5$-MB URAM. Compared to uncompressed training on the NVIDIA RTX 3090 GPU, our on-FPGA training achieves a memory reduction of $30\times$ to $51\times$. Our FPGA accelerator also achieves up to $3.6\times$ less energy cost per epoch compared with tensor Transformer training on an NVIDIA RTX 3090 GPU.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
TartanAir: A Dataset to Push the Limits of Visual SLAM
Mar 31, 2020



We present a challenging dataset, the TartanAir, for robot navigation task and more. The data is collected in photo-realistic simulation environments in the presence of various light conditions, weather and moving objects. By collecting data in simulation, we are able to obtain multi-modal sensor data and precise ground truth labels, including the stereo RGB image, depth image, segmentation, optical flow, camera poses, and LiDAR point cloud. We set up a large number of environments with various styles and scenes, covering challenging viewpoints and diverse motion patterns, which are difficult to achieve by using physical data collection platforms.
Novel View Synthesis for Large-scale Scene using Adversarial Loss
Feb 20, 2018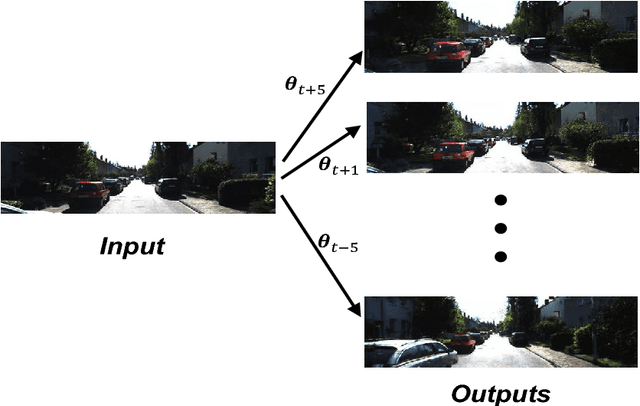

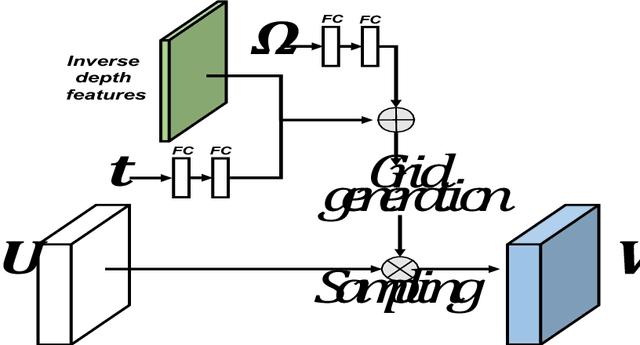

Novel view synthesis aims to synthesize new images from different viewpoints of given images. Most of previous works focus on generating novel views of certain objects with a fixed background. However, for some applications, such as virtual reality or robotic manipulations, large changes in background may occur due to the egomotion of the camera. Generated images of a large-scale environment from novel views may be distorted if the structure of the environment is not considered. In this work, we propose a novel fully convolutional network, that can take advantage of the structural information explicitly by incorporating the inverse depth features. The inverse depth features are obtained from CNNs trained with sparse labeled depth values. This framework can easily fuse multiple images from different viewpoints. To fill the missing textures in the generated image, adversarial loss is applied, which can also improve the overall image quality. Our method is evaluated on the KITTI dataset. The results show that our method can generate novel views of large-scale scene without distortion. The effectiveness of our approach is demonstrated through qualitative and quantitative evaluation.