 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Synthesis for Large-scale Scene using Adversarial Loss
Feb 20, 2018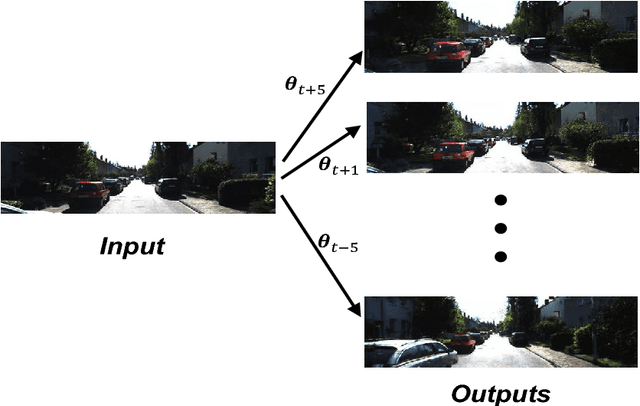

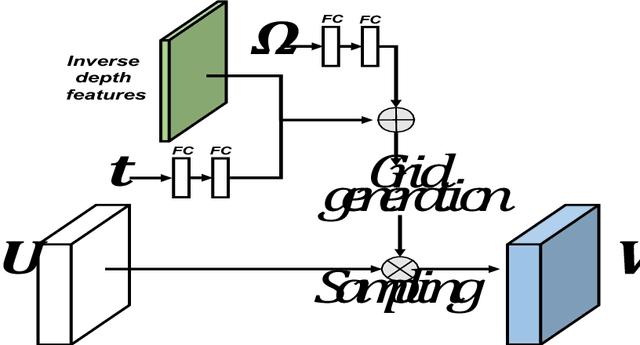

Novel view synthesis aims to synthesize new images from different viewpoints of given images. Most of previous works focus on generating novel views of certain objects with a fixed background. However, for some applications, such as virtual reality or robotic manipulations, large changes in background may occur due to the egomotion of the camera. Generated images of a large-scale environment from novel views may be distorted if the structure of the environment is not considered. In this work, we propose a novel fully convolutional network, that can take advantage of the structural information explicitly by incorporating the inverse depth features. The inverse depth features are obtained from CNNs trained with sparse labeled depth values. This framework can easily fuse multiple images from different viewpoints. To fill the missing textures in the generated image, adversarial loss is applied, which can also improve the overall image quality. Our method is evaluated on the KITTI dataset. The results show that our method can generate novel views of large-scale scene without distortion. The effectiveness of our approach is demonstrated through qualitative and quantitative evaluation.