 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2TE: Coordinated Constrained Task Execution Design for Ordering-Flexible Multi-Vehicle Platoon Merging
Jun 16, 2025In this paper, we propose a distributed coordinated constrained task execution (C2TE) algorithm that enables a team of vehicles from different lanes to cooperatively merge into an {\it ordering-flexible platoon} maneuvering on the desired lane. Therein, the platoon is flexible in the sense that no specific spatial ordering sequences of vehicles are predetermined. To attain such a flexible platoon, we first separate the multi-vehicle platoon (MVP) merging mission into two stages, namely, pre-merging regulation and {\it ordering-flexible platoon} merging, and then formulate them into distributed constraint-based optimization problems. Particularly, by encoding longitudinal-distance regulation and same-lane collision avoidance subtasks into the corresponding control barrier function (CBF) constraints, the proposed algorithm in Stage 1 can safely enlarge sufficient longitudinal distances among adjacent vehicles. Then, by encoding lateral convergence, longitudinal-target attraction, and neighboring collision avoidance subtasks into CBF constraints, the proposed algorithm in Stage~2 can efficiently achieve the {\it ordering-flexible platoon}. Note that the {\it ordering-flexible platoon} is realized through the interaction of the longitudinal-target attraction and time-varying neighboring collision avoidance constraints simultaneously. Feasibility guarantee and rigorous convergence analysis are both provided under strong nonlinear couplings induced by flexible orderings. Finally, experiments using three autonomous mobile vehicles (AMVs) are conducted to verify the effectiveness and flexibility of the proposed algorithm, and extensive simulations are performed to demonstrate its robustness, adaptability, and scalability when tackling vehicles' sudden breakdown, new appearing, different number of lanes, mixed autonomy, and large-scale scenarios, respectively.
Concurrent-Allocation Task Execution for Multi-Robot Path-Crossing-Minimal Navigation in Obstacle Environments
Apr 12, 2025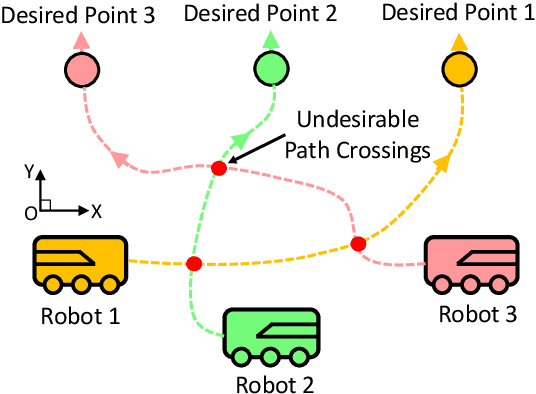
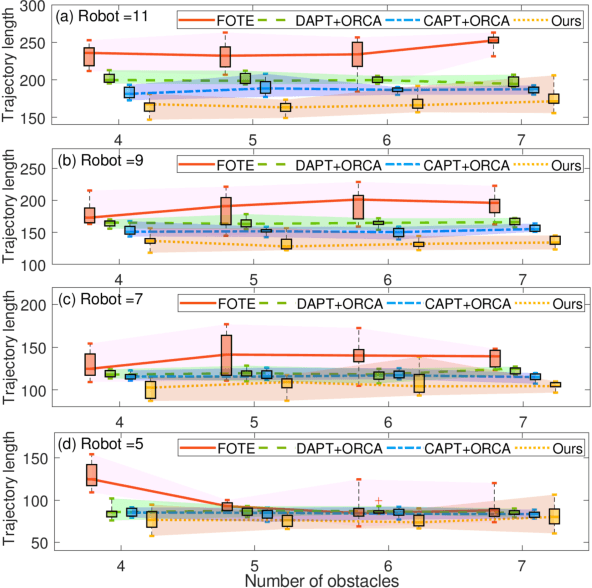
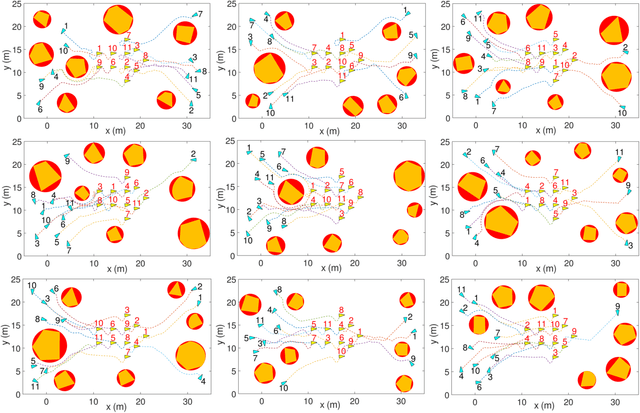
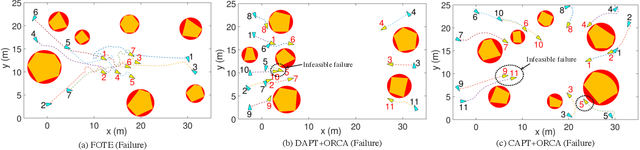
Reducing undesirable path crossings among trajectories of different robots is vital in multi-robot navigation missions, which not only reduces detours and conflict scenarios, but also enhances navigation efficiency and boosts productivity. Despite recent progress in multi-robot path-crossing-minimal (MPCM) navigation, the majority of approaches depend on the minimal squared-distance reassignment of suitable desired points to robots directly. However, if obstacles occupy the passing space, calculating the actual robot-point distances becomes complex or intractable, which may render the MPCM navigation in obstacle environments inefficient or even infeasible. In this paper, the concurrent-allocation task execution (CATE) algorithm is presented to address this problem (i.e., MPCM navigation in obstacle environments). First, the path-crossing-related elements in terms of (i) robot allocation, (ii) desired-point convergence, and (iii) collision and obstacle avoidance are encoded into integer and control barrier function (CBF) constraints. Then, the proposed constraints are used in an online constrained optimization framework, which implicitly yet effectively minimizes the possible path crossings and trajectory length in obstacle environments by minimizing the desired point allocation cost and slack variables in CBF constraints simultaneously. In this way, the MPCM navigation in obstacle environments can be achieved with flexible spatial orderings. Note that the feasibility of solutions and the asymptotic convergence property of the proposed CATE algorithm in obstacle environments are both guaranteed, and the calculation burden is also reduced by concurrently calculating the optimal allocation and the control input directly without the path planning process.
Ordering-Flexible Multi-Robot Coordination for MovingTarget Convoying Using Long-TermTask Execution
Jan 12, 2024
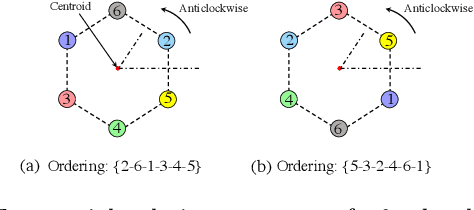
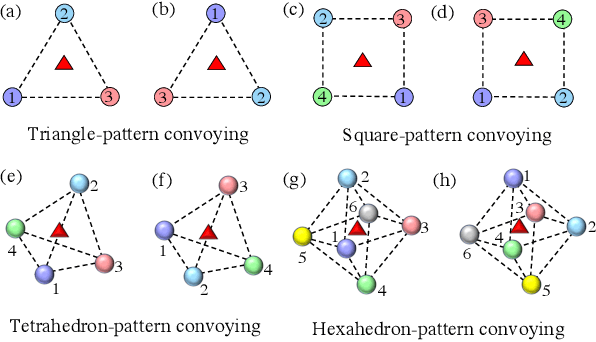
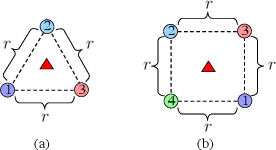
In this paper, we propose a cooperative long-term task execution (LTTE) algorithm for protecting a moving target into the interior of an ordering-flexible convex hull by a team of robots resiliently in the changing environments. Particularly, by designing target-approaching and sensing-neighbor collision-free subtasks, and incorporating these subtasks into the constraints rather than the traditional cost function in an online constraint-based optimization framework, the proposed LTTE can systematically guarantee long-term target convoying under changing environments in the n-dimensional Euclidean space. Then, the introduction of slack variables allow for the constraint violation of different subtasks; i.e., the attraction from target-approaching constraints and the repulsion from time-varying collision-avoidance constraints, which results in the desired formation with arbitrary spatial ordering sequences. Rigorous analysis is provided to guarantee asymptotical convergence with challenging nonlinear couplings induced by time-varying collision-free constraints. Finally, 2D experiments using three autonomous mobile robots (AMRs) are conducted to validate the effectiveness of the proposed algorithm, and 3D simulations tackling changing environmental elements, such as different initial positions, some robots suddenly breakdown and static obstacles are presented to demonstrate the multi-dimensional adaptability, robustness and the ability of obstacle avoidance of the proposed method.
Novel Video Prediction for Large-scale Scene using Optical Flow
May 30, 2018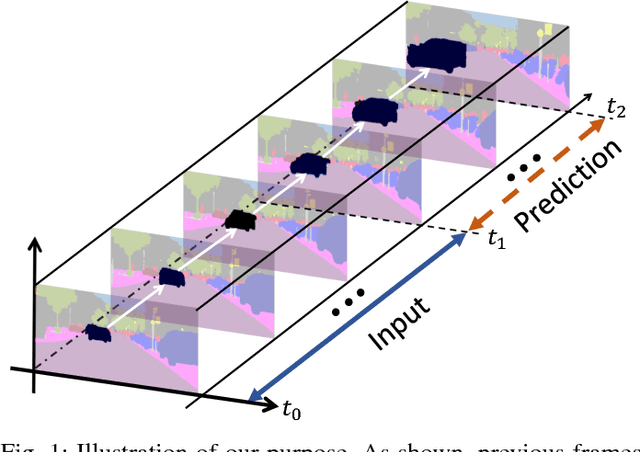
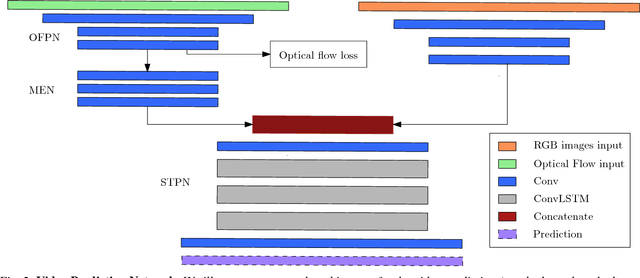
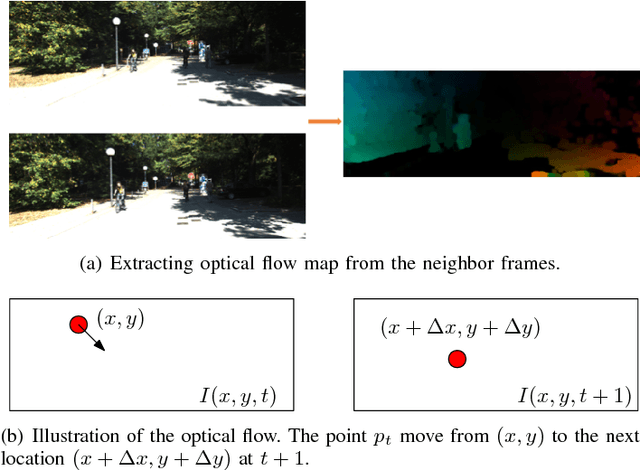

Making predictions of future frames is a critical challenge in autonomous driving research. Most of the existing methods for video prediction attempt to generate future frames in simple and fixed scenes. In this paper, we propose a novel and effective optical flow conditioned method for the task of video prediction with an application to complex urban scenes. In contrast with previous work, the prediction model only requires video sequences and optical flow sequences for training and testing. Our method uses the rich spatial-temporal features in video sequences. The method takes advantage of the motion information extracting from optical flow maps between neighbor images as well as previous images. Empirical evaluations on the KITTI dataset and the Cityscapes dataset demonstrate the effectiveness of our method.
Novel View Synthesis for Large-scale Scene using Adversarial Loss
Feb 20, 2018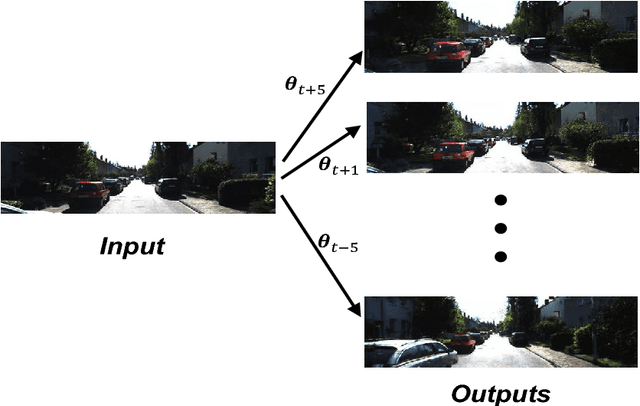

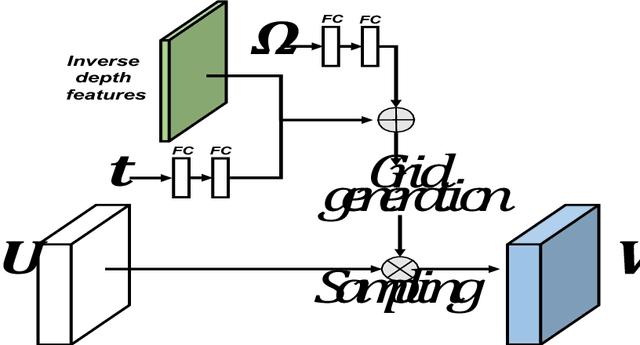

Novel view synthesis aims to synthesize new images from different viewpoints of given images. Most of previous works focus on generating novel views of certain objects with a fixed background. However, for some applications, such as virtual reality or robotic manipulations, large changes in background may occur due to the egomotion of the camera. Generated images of a large-scale environment from novel views may be distorted if the structure of the environment is not considered. In this work, we propose a novel fully convolutional network, that can take advantage of the structural information explicitly by incorporating the inverse depth features. The inverse depth features are obtained from CNNs trained with sparse labeled depth values. This framework can easily fuse multiple images from different viewpoints. To fill the missing textures in the generated image, adversarial loss is applied, which can also improve the overall image quality. Our method is evaluated on the KITTI dataset. The results show that our method can generate novel views of large-scale scene without distortion. The effectiveness of our approach is demonstrated through qualitative and quantitative evaluation.