 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Video Prediction for Large-scale Scene using Optical Flow
Paper and Code
May 30, 2018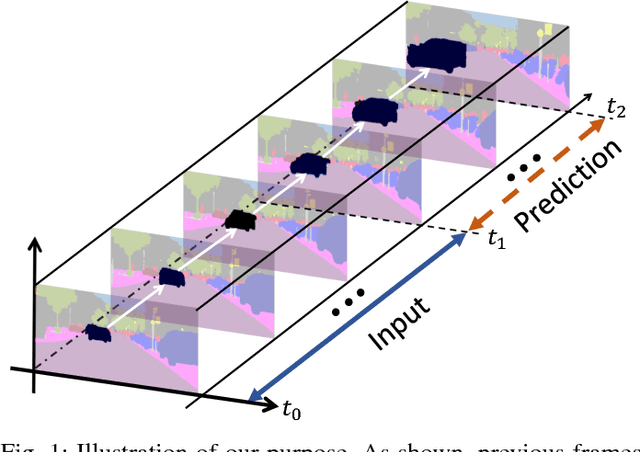
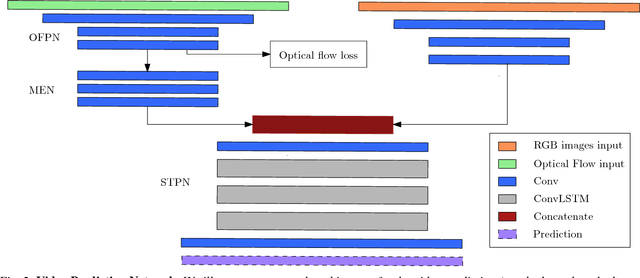
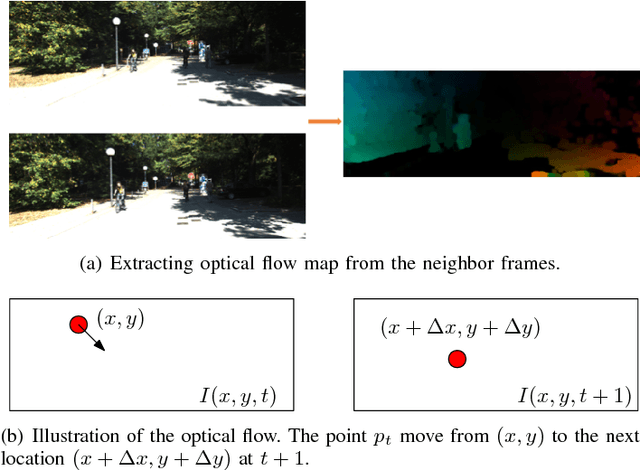

Making predictions of future frames is a critical challenge in autonomous driving research. Most of the existing methods for video prediction attempt to generate future frames in simple and fixed scenes. In this paper, we propose a novel and effective optical flow conditioned method for the task of video prediction with an application to complex urban scenes. In contrast with previous work, the prediction model only requires video sequences and optical flow sequences for training and testing. Our method uses the rich spatial-temporal features in video sequences. The method takes advantage of the motion information extracting from optical flow maps between neighbor images as well as previous images. Empirical evaluations on the KITTI dataset and the Cityscapes dataset demonstrate the effectiveness of our method.