 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Neural Edge Reconstruction
May 29, 2024Real-world objects and environments are predominantly composed of edge features, including straight lines and curves. Such edges are crucial elements for various applications, such as CAD modeling, surface meshing, lane mapping, etc. However, existing traditional methods only prioritize lines over curves for simplicity in geometric modeling. To this end, we introduce EMAP, a new method for learning 3D edge representations with a focus on both lines and curves. Our method implicitly encodes 3D edge distance and direction in Unsigned Distance Functions (UDF) from multi-view edge maps. On top of this neural representation, we propose an edge extraction algorithm that robustly abstracts parametric 3D edges from the inferred edge points and their directions. Comprehensive evaluations demonstrate that our method achieves better 3D edge reconstruction on multiple challenging datasets. We further show that our learned UDF field enhances neural surface reconstruction by capturing more details.
Unsupervised Learning of Depth and Deep Representation for Visual Odometry from Monocular Videos in a Metric Space
Aug 04, 2019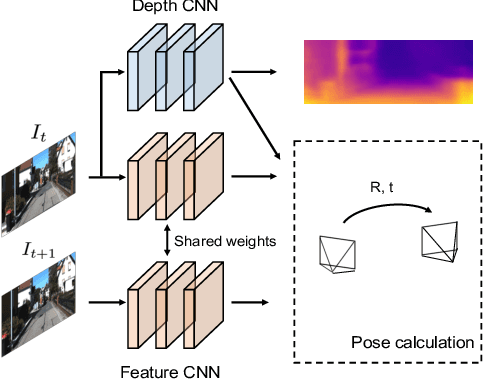
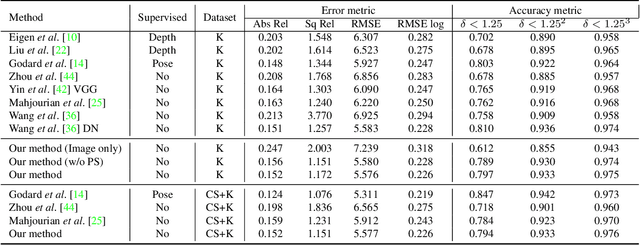
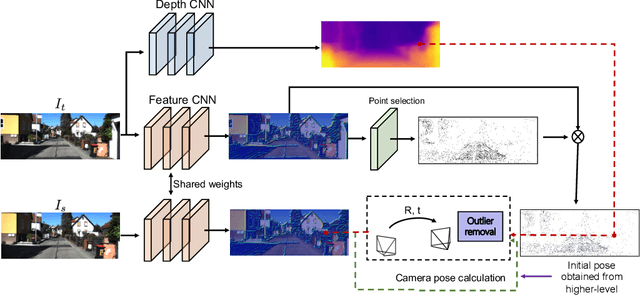
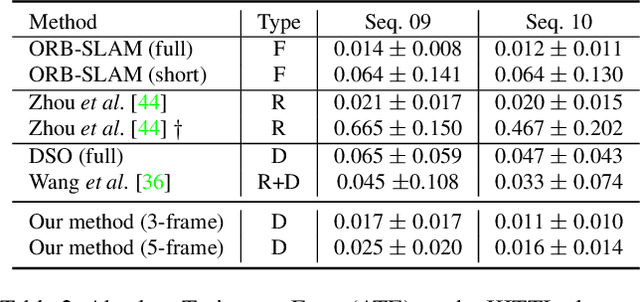
For ego-motion estimation, the feature representation of the scenes is crucial. Previous methods indicate that both the low-level and semantic feature-based methods can achieve promising results. Therefore, the incorporation of hierarchical feature representation may benefit from both methods. From this perspective, we propose a novel direct feature odometry framework, named DFO, for depth estimation and hierarchical feature representation learning from monocular videos. By exploiting the metric distance, our framework is able to learn the hierarchical feature representation without supervision. The pose is obtained with a coarse-to-fine approach from high-level to low-level features in enlarged feature maps. The pixel-level attention mask can be self-learned to provide the prior information. In contrast to the previous methods, our proposed method calculates the camera motion with a direct method rather than regressing the ego-motion from the pose network. With this approach, the consistency of the scale factor of translation can be constrained. Additionally, the proposed method is thus compatible with the traditional SLAM pipeline. Experiments on the KITTI dataset demonstrate the effectiveness of our method.
Novel Video Prediction for Large-scale Scene using Optical Flow
May 30, 2018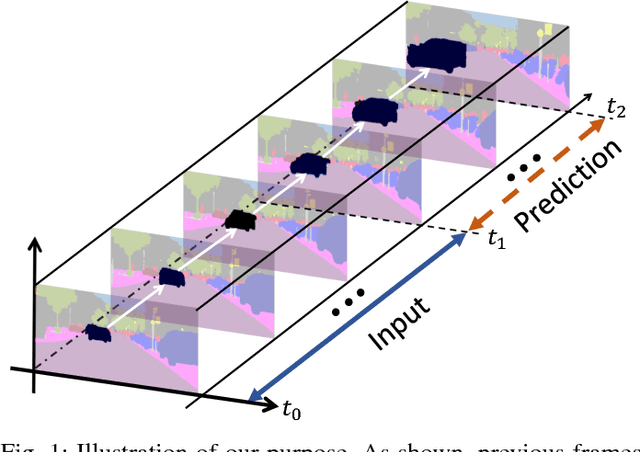
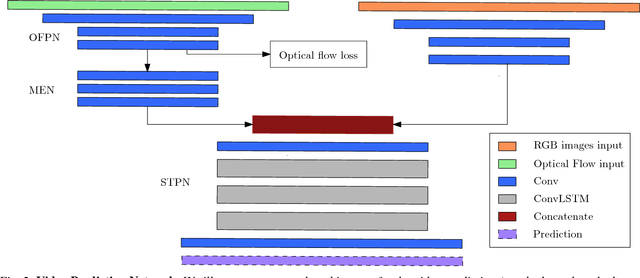
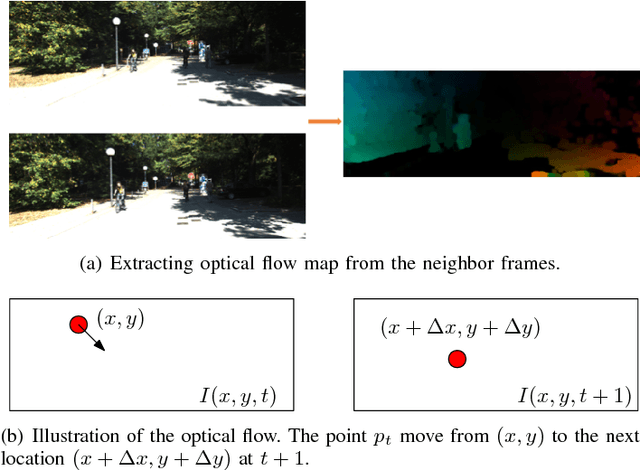

Making predictions of future frames is a critical challenge in autonomous driving research. Most of the existing methods for video prediction attempt to generate future frames in simple and fixed scenes. In this paper, we propose a novel and effective optical flow conditioned method for the task of video prediction with an application to complex urban scenes. In contrast with previous work, the prediction model only requires video sequences and optical flow sequences for training and testing. Our method uses the rich spatial-temporal features in video sequences. The method takes advantage of the motion information extracting from optical flow maps between neighbor images as well as previous images. Empirical evaluations on the KITTI dataset and the Cityscapes dataset demonstrate the effectiveness of our method.
Novel View Synthesis for Large-scale Scene using Adversarial Loss
Feb 20, 2018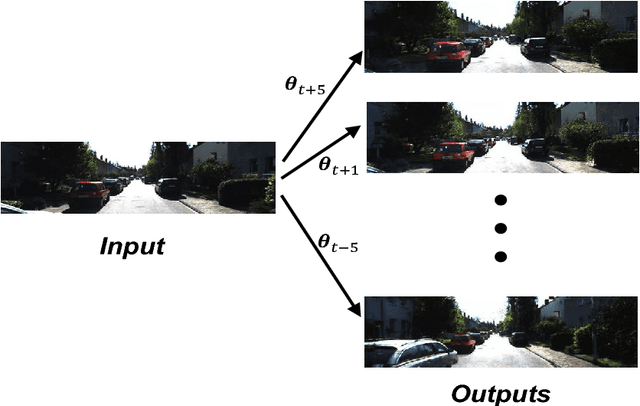

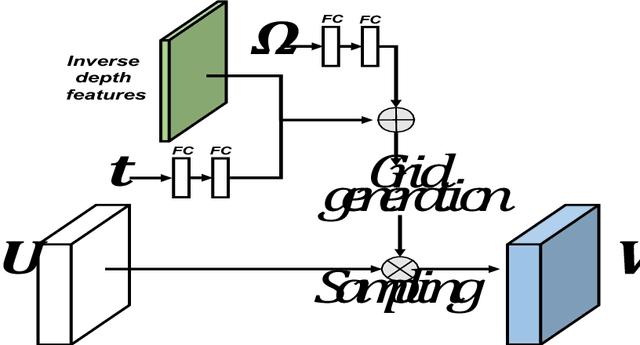

Novel view synthesis aims to synthesize new images from different viewpoints of given images. Most of previous works focus on generating novel views of certain objects with a fixed background. However, for some applications, such as virtual reality or robotic manipulations, large changes in background may occur due to the egomotion of the camera. Generated images of a large-scale environment from novel views may be distorted if the structure of the environment is not considered. In this work, we propose a novel fully convolutional network, that can take advantage of the structural information explicitly by incorporating the inverse depth features. The inverse depth features are obtained from CNNs trained with sparse labeled depth values. This framework can easily fuse multiple images from different viewpoints. To fill the missing textures in the generated image, adversarial loss is applied, which can also improve the overall image quality. Our method is evaluated on the KITTI dataset. The results show that our method can generate novel views of large-scale scene without distortion. The effectiveness of our approach is demonstrated through qualitative and quantitative evaluation.