 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree360: Layered Gaussian Splatting for Unbounded 360-Degree View Synthesis from Extremely Sparse and Unposed Views
Mar 31, 2025

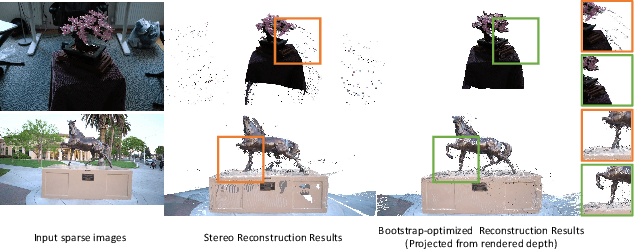

Neural rendering has demonstrated remarkable success in high-quality 3D neural reconstruction and novel view synthesis with dense input views and accurate poses. However, applying it to extremely sparse, unposed views in unbounded 360{\deg} scenes remains a challenging problem. In this paper, we propose a novel neural rendering framework to accomplish the unposed and extremely sparse-view 3D reconstruction in unbounded 360{\deg} scenes. To resolve the spatial ambiguity inherent in unbounded scenes with sparse input views, we propose a layered Gaussian-based representation to effectively model the scene with distinct spatial layers. By employing a dense stereo reconstruction model to recover coarse geometry, we introduce a layer-specific bootstrap optimization to refine the noise and fill occluded regions in the reconstruction. Furthermore, we propose an iterative fusion of reconstruction and generation alongside an uncertainty-aware training approach to facilitate mutual conditioning and enhancement between these two processes. Comprehensive experiments show that our approach outperforms existing state-of-the-art methods in terms of rendering quality and surface reconstruction accuracy. Project page: https://zju3dv.github.io/free360/
3D Neural Edge Reconstruction
May 29, 2024Real-world objects and environments are predominantly composed of edge features, including straight lines and curves. Such edges are crucial elements for various applications, such as CAD modeling, surface meshing, lane mapping, etc. However, existing traditional methods only prioritize lines over curves for simplicity in geometric modeling. To this end, we introduce EMAP, a new method for learning 3D edge representations with a focus on both lines and curves. Our method implicitly encodes 3D edge distance and direction in Unsigned Distance Functions (UDF) from multi-view edge maps. On top of this neural representation, we propose an edge extraction algorithm that robustly abstracts parametric 3D edges from the inferred edge points and their directions. Comprehensive evaluations demonstrate that our method achieves better 3D edge reconstruction on multiple challenging datasets. We further show that our learned UDF field enhances neural surface reconstruction by capturing more details.
Efficient End-to-End Detection of 6-DoF Grasps for Robotic Bin Picking
May 10, 2024



Bin picking is an important building block for many robotic systems, in logistics, production or in household use-cases. In recent years, machine learning methods for the prediction of 6-DoF grasps on diverse and unknown objects have shown promising progress. However, existing approaches only consider a single ground truth grasp orientation at a grasp location during training and therefore can only predict limited grasp orientations which leads to a reduced number of feasible grasps in bin picking with restricted reachability. In this paper, we propose a novel approach for learning dense and diverse 6-DoF grasps for parallel-jaw grippers in robotic bin picking. We introduce a parameterized grasp distribution model based on Power-Spherical distributions that enables a training based on all possible ground truth samples. Thereby, we also consider the grasp uncertainty enhancing the model's robustness to noisy inputs. As a result, given a single top-down view depth image, our model can generate diverse grasps with multiple collision-free grasp orientations. Experimental evaluations in simulation and on a real robotic bin picking setup demonstrate the model's ability to generalize across various object categories achieving an object clearing rate of around $90 \%$ in simulation and real-world experiments. We also outperform state of the art approaches. Moreover, the proposed approach exhibits its usability in real robot experiments without any refinement steps, even when only trained on a synthetic dataset, due to the probabilistic grasp distribution modeling.
Gaussian Opacity Fields: Efficient and Compact Surface Reconstruction in Unbounded Scenes
Apr 16, 2024Recently, 3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis results, while allowing the rendering of high-resolution images in real-time. However, leveraging 3D Gaussians for surface reconstruction poses significant challenges due to the explicit and disconnected nature of 3D Gaussians. In this work, we present Gaussian Opacity Fields (GOF), a novel approach for efficient, high-quality, and compact surface reconstruction in unbounded scenes. Our GOF is derived from ray-tracing-based volume rendering of 3D Gaussians, enabling direct geometry extraction from 3D Gaussians by identifying its levelset, without resorting to Poisson reconstruction or TSDF fusion as in previous work. We approximate the surface normal of Gaussians as the normal of the ray-Gaussian intersection plane, enabling the application of regularization that significantly enhances geometry. Furthermore, we develop an efficient geometry extraction method utilizing marching tetrahedra, where the tetrahedral grids are induced from 3D Gaussians and thus adapt to the scene's complexity. Our evaluations reveal that GOF surpasses existing 3DGS-based methods in surface reconstruction and novel view synthesis. Further, it compares favorably to, or even outperforms, neural implicit methods in both quality and speed.
2D Gaussian Splatting for Geometrically Accurate Radiance Fields
Mar 26, 2024



3D Gaussian Splatting (3DGS) has recently revolutionized radiance field reconstruction, achieving high quality novel view synthesis and fast rendering speed without baking. However, 3DGS fails to accurately represent surfaces due to the multi-view inconsistent nature of 3D Gaussians. We present 2D Gaussian Splatting (2DGS), a novel approach to model and reconstruct geometrically accurate radiance fields from multi-view images. Our key idea is to collapse the 3D volume into a set of 2D oriented planar Gaussian disks. Unlike 3D Gaussians, 2D Gaussians provide view-consistent geometry while modeling surfaces intrinsically. To accurately recover thin surfaces and achieve stable optimization, we introduce a perspective-accurate 2D splatting process utilizing ray-splat intersection and rasterization. Additionally, we incorporate depth distortion and normal consistency terms to further enhance the quality of the reconstructions. We demonstrate that our differentiable renderer allows for noise-free and detailed geometry reconstruction while maintaining competitive appearance quality, fast training speed, and real-time rendering. Our code will be made publicly available.
Improving Generalizability of Extracting Social Determinants of Health Using Large Language Models through Prompt-tuning
Mar 19, 2024


The progress in natural language processing (NLP) using large language models (LLMs) has greatly improved patient information extraction from clinical narratives. However, most methods based on the fine-tuning strategy have limited transfer learning ability for cross-domain applications. This study proposed a novel approach that employs a soft prompt-based learning architecture, which introduces trainable prompts to guide LLMs toward desired outputs. We examined two types of LLM architectures, including encoder-only GatorTron and decoder-only GatorTronGPT, and evaluated their performance for the extraction of social determinants of health (SDoH) using a cross-institution dataset from the 2022 n2c2 challenge and a cross-disease dataset from the University of Florida (UF) Health. The results show that decoder-only LLMs with prompt tuning achieved better performance in cross-domain applications. GatorTronGPT achieved the best F1 scores for both datasets, outperforming traditional fine-tuned GatorTron by 8.9% and 21.8% in a cross-institution setting, and 5.5% and 14.5% in a cross-disease setting.
Generative Large Language Models Are All-purpose Text Analytics Engines: Text-to-text Learning Is All Your Need
Dec 11, 2023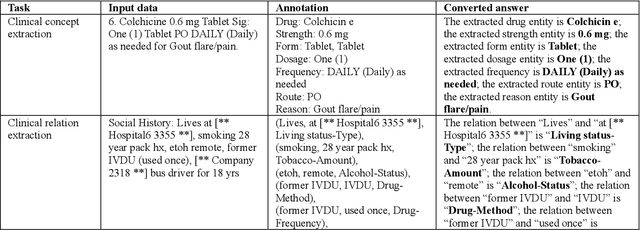
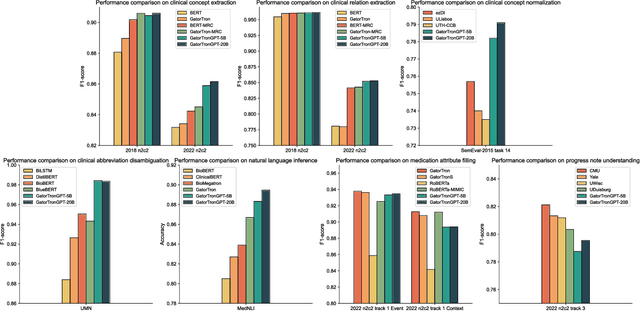
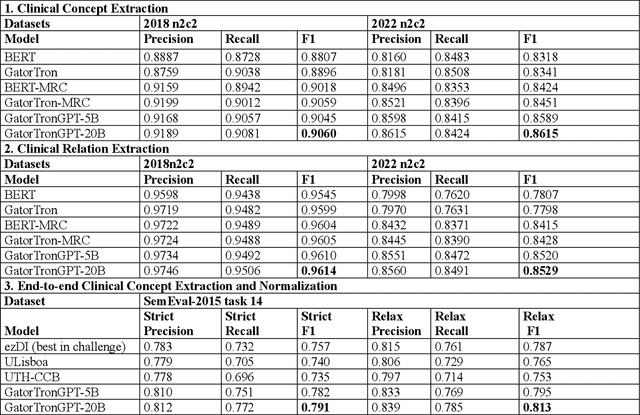

Objective To solve major clinical natural language processing (NLP) tasks using a unified text-to-text learning architecture based on a generative large language model (LLM) via prompt tuning. Methods We formulated 7 key clinical NLP tasks as text-to-text learning and solved them using one unified generative clinical LLM, GatorTronGPT, developed using GPT-3 architecture and trained with up to 20 billion parameters. We adopted soft prompts (i.e., trainable vectors) with frozen LLM, where the LLM parameters were not updated (i.e., frozen) and only the vectors of soft prompts were updated, known as prompt tuning. We added additional soft prompts as a prefix to the input layer, which were optimized during the prompt tuning. We evaluated the proposed method using 7 clinical NLP tasks and compared them with previous task-specific solutions based on Transformer models. Results and Conclusion The proposed approach achieved state-of-the-art performance for 5 out of 7 major clinical NLP tasks using one unified generative LLM. Our approach outperformed previous task-specific transformer models by ~3% for concept extraction and 7% for relation extraction applied to social determinants of health, 3.4% for clinical concept normalization, 3.4~10% for clinical abbreviation disambiguation, and 5.5~9% for natural language inference. Our approach also outperformed a previously developed prompt-based machine reading comprehension (MRC) model, GatorTron-MRC, for clinical concept and relation extraction. The proposed approach can deliver the ``one model for all`` promise from training to deployment using a unified generative LLM.
Mip-Splatting: Alias-free 3D Gaussian Splatting
Nov 27, 2023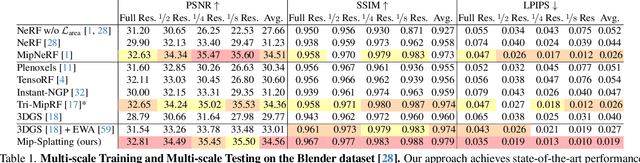

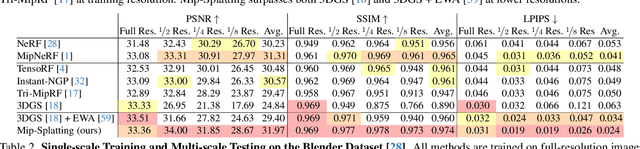
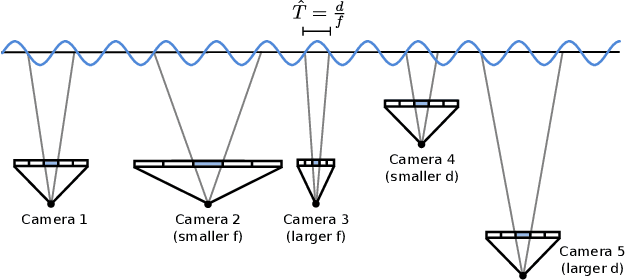
Recently, 3D Gaussian Splatting has demonstrated impressive novel view synthesis results, reaching high fidelity and efficiency. However, strong artifacts can be observed when changing the sampling rate, \eg, by changing focal length or camera distance. We find that the source for this phenomenon can be attributed to the lack of 3D frequency constraints and the usage of a 2D dilation filter. To address this problem, we introduce a 3D smoothing filter which constrains the size of the 3D Gaussian primitives based on the maximal sampling frequency induced by the input views, eliminating high-frequency artifacts when zooming in. Moreover, replacing 2D dilation with a 2D Mip filter, which simulates a 2D box filter, effectively mitigates aliasing and dilation issues. Our evaluation, including scenarios such a training on single-scale images and testing on multiple scales, validates the effectiveness of our approach.
Model Tuning or Prompt Tuning? A Study of Large Language Models for Clinical Concept and Relation Extraction
Oct 10, 2023
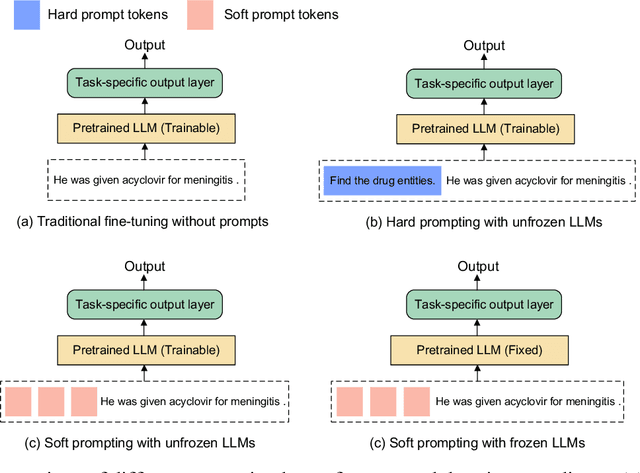
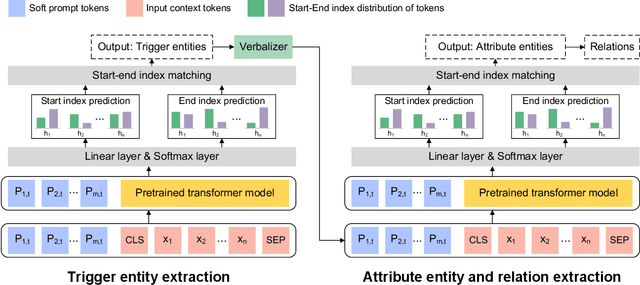
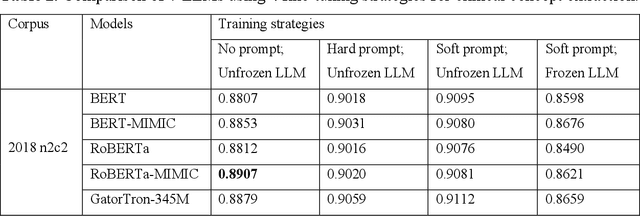
Objective To develop soft prompt-based learning algorithms for large language models (LLMs), examine the shape of prompts, prompt-tuning using frozen/unfrozen LLMs, transfer learning, and few-shot learning abilities. Methods We developed a soft prompt-based LLM model and compared 4 training strategies including (1) fine-tuning without prompts; (2) hard-prompt with unfrozen LLMs; (3) soft-prompt with unfrozen LLMs; and (4) soft-prompt with frozen LLMs. We evaluated 7 pretrained LLMs using the 4 training strategies for clinical concept and relation extraction on two benchmark datasets. We evaluated the transfer learning ability of the prompt-based learning algorithms in a cross-institution setting. We also assessed the few-shot learning ability. Results and Conclusion When LLMs are unfrozen, GatorTron-3.9B with soft prompting achieves the best strict F1-scores of 0.9118 and 0.8604 for concept extraction, outperforming the traditional fine-tuning and hard prompt-based models by 0.6~3.1% and 1.2~2.9%, respectively; GatorTron-345M with soft prompting achieves the best F1-scores of 0.8332 and 0.7488 for end-to-end relation extraction, outperforming the other two models by 0.2~2% and 0.6~11.7%, respectively. When LLMs are frozen, small (i.e., 345 million parameters) LLMs have a big gap to be competitive with unfrozen models; scaling LLMs up to billions of parameters makes frozen LLMs competitive with unfrozen LLMs. For cross-institute evaluation, soft prompting with a frozen GatorTron-8.9B model achieved the best performance. This study demonstrates that (1) machines can learn soft prompts better than humans, (2) frozen LLMs have better few-shot learning ability and transfer learning ability to facilitate muti-institution applications, and (3) frozen LLMs require large models.
DebSDF: Delving into the Details and Bias of Neural Indoor Scene Reconstruction
Sep 03, 2023
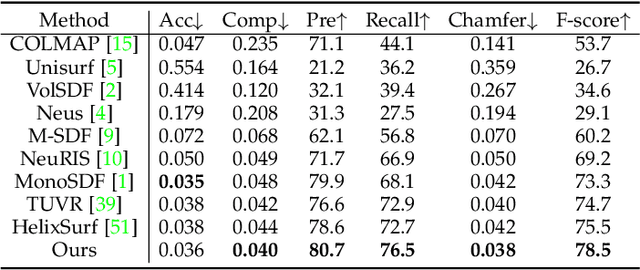


In recent years, the neural implicit surface has emerged as a powerful representation for multi-view surface reconstruction due to its simplicity and state-of-the-art performance. However, reconstructing smooth and detailed surfaces in indoor scenes from multi-view images presents unique challenges. Indoor scenes typically contain large texture-less regions, making the photometric loss unreliable for optimizing the implicit surface. Previous work utilizes monocular geometry priors to improve the reconstruction in indoor scenes. However, monocular priors often contain substantial errors in thin structure regions due to domain gaps and the inherent inconsistencies when derived independently from different views. This paper presents \textbf{DebSDF} to address these challenges, focusing on the utilization of uncertainty in monocular priors and the bias in SDF-based volume rendering. We propose an uncertainty modeling technique that associates larger uncertainties with larger errors in the monocular priors. High-uncertainty priors are then excluded from optimization to prevent bias. This uncertainty measure also informs an importance-guided ray sampling and adaptive smoothness regularization, enhancing the learning of fine structures. We further introduce a bias-aware signed distance function to density transformation that takes into account the curvature and the angle between the view direction and the SDF normals to reconstruct fine details better. Our approach has been validated through extensive experiments on several challenging datasets, demonstrating improved qualitative and quantitative results in reconstructing thin structures in indoor scenes, thereby outperforming previous work.