 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELA-ZSON: Efficient Layout-Aware Zero-Shot Object Navigation Agent with Hierarchical Planning
May 09, 2025We introduce ELA-ZSON, an efficient layout-aware zero-shot object navigation (ZSON) approach designed for complex multi-room indoor environments. By planning hierarchically leveraging a global topologigal map with layout information and local imperative approach with detailed scene representation memory, ELA-ZSON achieves both efficient and effective navigation. The process is managed by an LLM-powered agent, ensuring seamless effective planning and navigation, without the need for human interaction, complex rewards, or costly training. Our experimental results on the MP3D benchmark achieves 85\% object navigation success rate (SR) and 79\% success rate weighted by path length (SPL) (over 40\% point improvement in SR and 60\% improvement in SPL compared to exsisting methods). Furthermore, we validate the robustness of our approach through virtual agent and real-world robotic deployment, showcasing its capability in practical scenarios. See https://anonymous.4open.science/r/ELA-ZSON-C67E/ for details.
Compensate Quantization Errors: Make Weights Hierarchical to Compensate Each Other
Jun 24, 2024Emergent Large Language Models (LLMs) use their extraordinary performance and powerful deduction capacity to discern from traditional language models. However, the expenses of computational resources and storage for these LLMs are stunning, quantization then arises as a trending conversation. To address accuracy decay caused by quantization, two streams of works in post-training quantization methods stand out. One uses other weights to compensate existing quantization error, while the other transfers the quantization difficulty to other parts in the model. Combining both merits, we introduce Learnable Singular value Increment (LSI) as an advanced solution. LSI uses Singular Value Decomposition to extract singular values of the weights and make them learnable to help weights compensate each other conditioned on activation. Incorporating LSI with existing techniques, we achieve state-of-the-art performance in diverse quantization settings, no matter in weight-only, weight-activation or extremely low bit scenarios. By unleashing the potential of LSI, efficient finetuning on quantized model is no longer a prohibitive problem.
Bridging 3D Gaussian and Mesh for Freeview Video Rendering
Mar 18, 2024This is only a preview version of GauMesh. Recently, primitive-based rendering has been proven to achieve convincing results in solving the problem of modeling and rendering the 3D dynamic scene from 2D images. Despite this, in the context of novel view synthesis, each type of primitive has its inherent defects in terms of representation ability. It is difficult to exploit the mesh to depict the fuzzy geometry. Meanwhile, the point-based splatting (e.g. the 3D Gaussian Splatting) method usually produces artifacts or blurry pixels in the area with smooth geometry and sharp textures. As a result, it is difficult, even not impossible, to represent the complex and dynamic scene with a single type of primitive. To this end, we propose a novel approach, GauMesh, to bridge the 3D Gaussian and Mesh for modeling and rendering the dynamic scenes. Given a sequence of tracked mesh as initialization, our goal is to simultaneously optimize the mesh geometry, color texture, opacity maps, a set of 3D Gaussians, and the deformation field. At a specific time, we perform $\alpha$-blending on the RGB and opacity values based on the merged and re-ordered z-buffers from mesh and 3D Gaussian rasterizations. This produces the final rendering, which is supervised by the ground-truth image. Experiments demonstrate that our approach adapts the appropriate type of primitives to represent the different parts of the dynamic scene and outperforms all the baseline methods in both quantitative and qualitative comparisons without losing render speed.
DebSDF: Delving into the Details and Bias of Neural Indoor Scene Reconstruction
Sep 03, 2023


In recent years, the neural implicit surface has emerged as a powerful representation for multi-view surface reconstruction due to its simplicity and state-of-the-art performance. However, reconstructing smooth and detailed surfaces in indoor scenes from multi-view images presents unique challenges. Indoor scenes typically contain large texture-less regions, making the photometric loss unreliable for optimizing the implicit surface. Previous work utilizes monocular geometry priors to improve the reconstruction in indoor scenes. However, monocular priors often contain substantial errors in thin structure regions due to domain gaps and the inherent inconsistencies when derived independently from different views. This paper presents \textbf{DebSDF} to address these challenges, focusing on the utilization of uncertainty in monocular priors and the bias in SDF-based volume rendering. We propose an uncertainty modeling technique that associates larger uncertainties with larger errors in the monocular priors. High-uncertainty priors are then excluded from optimization to prevent bias. This uncertainty measure also informs an importance-guided ray sampling and adaptive smoothness regularization, enhancing the learning of fine structures. We further introduce a bias-aware signed distance function to density transformation that takes into account the curvature and the angle between the view direction and the SDF normals to reconstruct fine details better. Our approach has been validated through extensive experiments on several challenging datasets, demonstrating improved qualitative and quantitative results in reconstructing thin structures in indoor scenes, thereby outperforming previous work.
ResNeRF: Geometry-Guided Residual Neural Radiance Field for Indoor Scene Novel View Synthesis
Dec 01, 2022



We represent the ResNeRF, a novel geometry-guided two-stage framework for indoor scene novel view synthesis. Be aware of that a good geometry would greatly boost the performance of novel view synthesis, and to avoid the geometry ambiguity issue, we propose to characterize the density distribution of the scene based on a base density estimated from scene geometry and a residual density parameterized by the geometry. In the first stage, we focus on geometry reconstruction based on SDF representation, which would lead to a good geometry surface of the scene and also a sharp density. In the second stage, the residual density is learned based on the SDF learned in the first stage for encoding more details about the appearance. In this way, our method can better learn the density distribution with the geometry prior for high-fidelity novel view synthesis while preserving the 3D structures. Experiments on large-scale indoor scenes with many less-observed and textureless areas show that with the good 3D surface, our method achieves state-of-the-art performance for novel view synthesis.
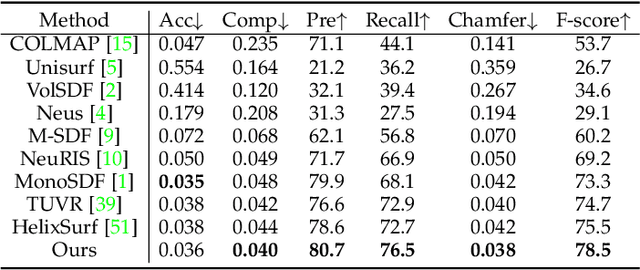
TaylorImNet for Fast 3D Shape Reconstruction Based on Implicit Surface Function
Jan 18, 2022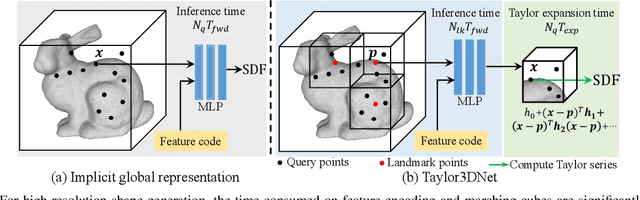

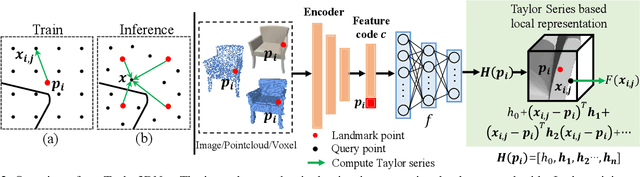
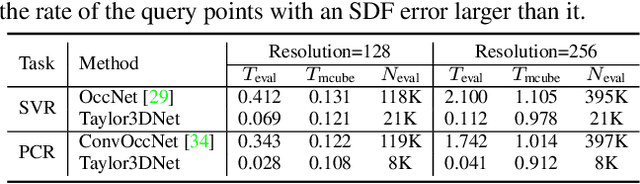
Benefiting from the contiguous representation ability, deep implicit functions can extract the iso-surface of a shape at arbitrary resolution. However, utilizing the neural network with a large number of parameters as the implicit function prevents the generation speed of high-resolution topology because it needs to forward a large number of query points into the network. In this work, we propose TaylorImNet inspired by the Taylor series for implicit 3D shape representation. TaylorImNet exploits a set of discrete expansion points and corresponding Taylor series to model a contiguous implicit shape field. After the expansion points and corresponding coefficients are obtained, our model only needs to calculate the Taylor series to evaluate each point and the number of expansion points is independent of the generating resolution. Based on this representation, our TaylorImNet can achieve a significantly faster generation speed than other baselines. We evaluate our approach on reconstruction tasks from various types of input, and the experimental results demonstrate that our approach can get slightly better performance than existing state-of-the-art baselines while improving the inference speed with a large margin.
Amodal Segmentation Based on Visible Region Segmentation and Shape Prior
Dec 19, 2020

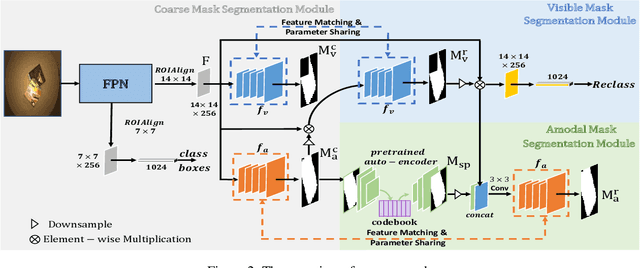

Almost all existing amodal segmentation methods make the inferences of occluded regions by using features corresponding to the whole image. This is against the human's amodal perception, where human uses the visible part and the shape prior knowledge of the target to infer the occluded region. To mimic the behavior of human and solve the ambiguity in the learning, we propose a framework, it firstly estimates a coarse visible mask and a coarse amodal mask. Then based on the coarse prediction, our model infers the amodal mask by concentrating on the visible region and utilizing the shape prior in the memory. In this way, features corresponding to background and occlusion can be suppressed for amodal mask estimation. Consequently, the amodal mask would not be affected by what the occlusion is given the same visible regions. The leverage of shape prior makes the amodal mask estimation more robust and reasonable. Our proposed model is evaluated on three datasets. Experiments show that our proposed model outperforms existing state-of-the-art methods. The visualization of shape prior indicates that the category-specific feature in the codebook has certain interpretability.
Encoding Structure-Texture Relation with P-Net for Anomaly Detection in Retinal Images
Aug 09, 2020Anomaly detection in retinal image refers to the identification of abnormality caused by various retinal diseases/lesions, by only leveraging normal images in training phase. Normal images from healthy subjects often have regular structures (e.g., the structured blood vessels in the fundus image, or structured anatomy in optical coherence tomography image). On the contrary, the diseases and lesions often destroy these structures. Motivated by this, we propose to leverage the relation between the image texture and structure to design a deep neural network for anomaly detection. Specifically, we first extract the structure of the retinal images, then we combine both the structure features and the last layer features extracted from original health image to reconstruct the original input healthy image. The image feature provides the texture information and guarantees the uniqueness of the image recovered from the structure. In the end, we further utilize the reconstructed image to extract the structure and measure the difference between structure extracted from original and the reconstructed image. On the one hand, minimizing the reconstruction difference behaves like a regularizer to guarantee that the image is corrected reconstructed. On the other hand, such structure difference can also be used as a metric for normality measurement. The whole network is termed as P-Net because it has a ``P'' shape. Extensive experiments on RESC dataset and iSee dataset validate the effectiveness of our approach for anomaly detection in retinal images. Further, our method also generalizes well to novel class discovery in retinal images and anomaly detection in real-world images.
SkrGAN: Sketching-rendering Unconditional Generative Adversarial Networks for Medical Image Synthesis
Aug 06, 2019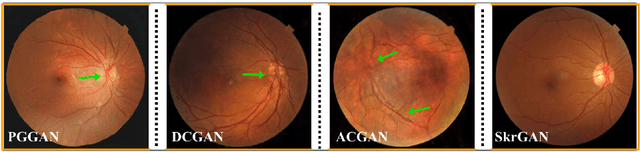
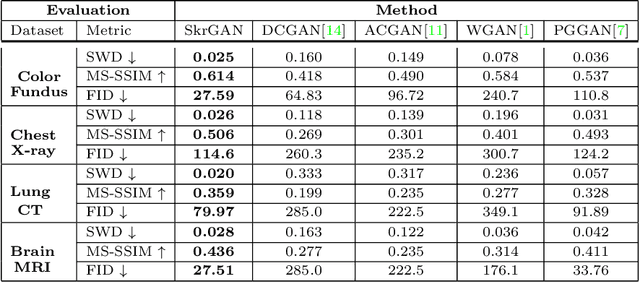
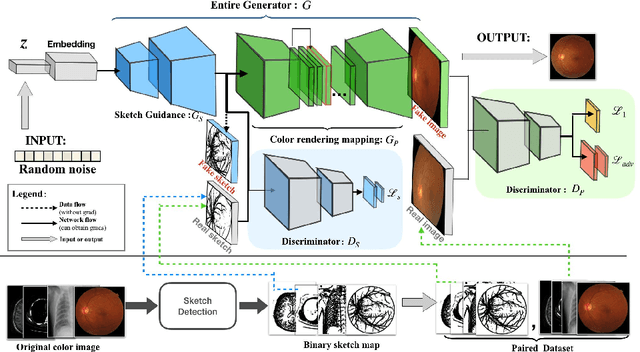
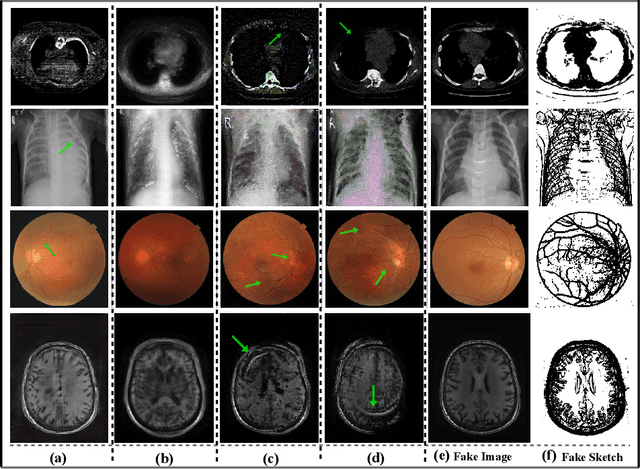
Generative Adversarial Networks (GANs) have the capability of synthesizing images, which have been successfully applied to medical image synthesis tasks. However, most of existing methods merely consider the global contextual information and ignore the fine foreground structures, e.g., vessel, skeleton, which may contain diagnostic indicators for medical image analysis. Inspired by human painting procedure, which is composed of stroking and color rendering steps, we propose a Sketching-rendering Unconditional Generative Adversarial Network (SkrGAN) to introduce a sketch prior constraint to guide the medical image generation. In our SkrGAN, a sketch guidance module is utilized to generate a high quality structural sketch from random noise, then a color render mapping is used to embed the sketch-based representations and resemble the background appearances. Experimental results show that the proposed SkrGAN achieves the state-of-the-art results in synthesizing images for various image modalities, including retinal color fundus, X-Ray, Computed Tomography (CT) and Magnetic Resonance Imaging (MRI). In addition, we also show that the performances of medical image segmentation method have been improved by using our synthesized images as data augmentation.