 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceTrans: Translation and Spatial Tracing for Surgical Prediction
Oct 25, 2025Image-to-image translation models have achieved notable success in converting images across visual domains and are increasingly used for medical tasks such as predicting post-operative outcomes and modeling disease progression. However, most existing methods primarily aim to match the target distribution and often neglect spatial correspondences between the source and translated images. This limitation can lead to structural inconsistencies and hallucinations, undermining the reliability and interpretability of the predictions. These challenges are accentuated in clinical applications by the stringent requirement for anatomical accuracy. In this work, we present TraceTrans, a novel deformable image translation model designed for post-operative prediction that generates images aligned with the target distribution while explicitly revealing spatial correspondences with the pre-operative input. The framework employs an encoder for feature extraction and dual decoders for predicting spatial deformations and synthesizing the translated image. The predicted deformation field imposes spatial constraints on the generated output, ensuring anatomical consistency with the source. Extensive experiments on medical cosmetology and brain MRI datasets demonstrate that TraceTrans delivers accurate and interpretable post-operative predictions, highlighting its potential for reliable clinical deployment.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025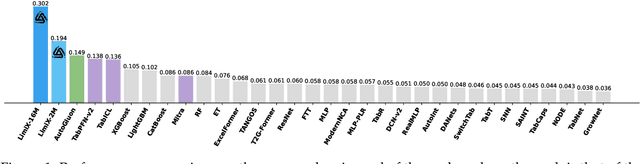
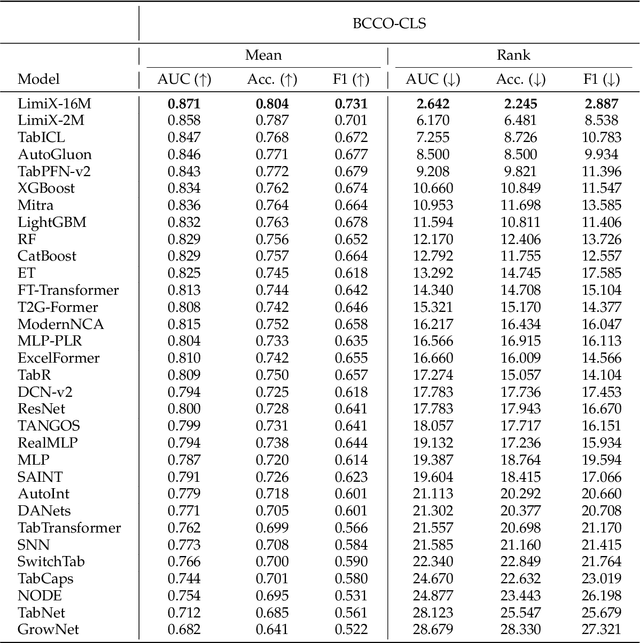
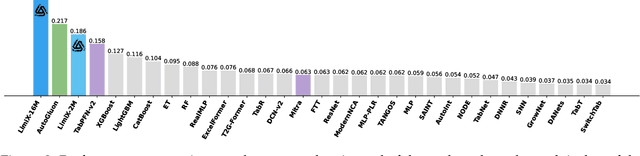
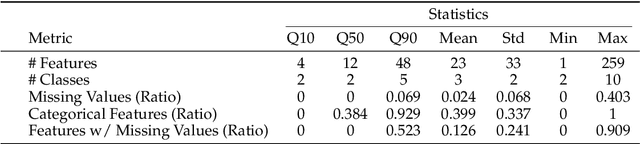
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
AdaFusion: Prompt-Guided Inference with Adaptive Fusion of Pathology Foundation Models
Aug 07, 2025Pathology foundation models (PFMs) have demonstrated strong representational capabilities through self-supervised pre-training on large-scale, unannotated histopathology image datasets. However, their diverse yet opaque pretraining contexts, shaped by both data-related and structural/training factors, introduce latent biases that hinder generalisability and transparency in downstream applications. In this paper, we propose AdaFusion, a novel prompt-guided inference framework that, to our knowledge, is among the very first to dynamically integrate complementary knowledge from multiple PFMs. Our method compresses and aligns tile-level features from diverse models and employs a lightweight attention mechanism to adaptively fuse them based on tissue phenotype context. We evaluate AdaFusion on three real-world benchmarks spanning treatment response prediction, tumour grading, and spatial gene expression inference. Our approach consistently surpasses individual PFMs across both classification and regression tasks, while offering interpretable insights into each model's biosemantic specialisation. These results highlight AdaFusion's ability to bridge heterogeneous PFMs, achieving both enhanced performance and interpretability of model-specific inductive biases.
ACMamba: Fast Unsupervised Anomaly Detection via An Asymmetrical Consensus State Space Model
Apr 16, 2025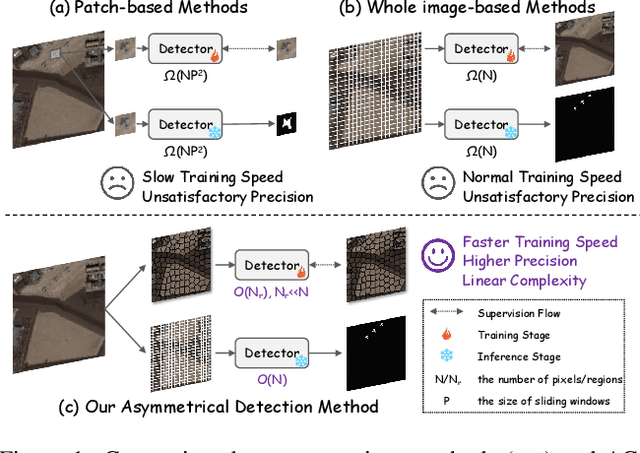
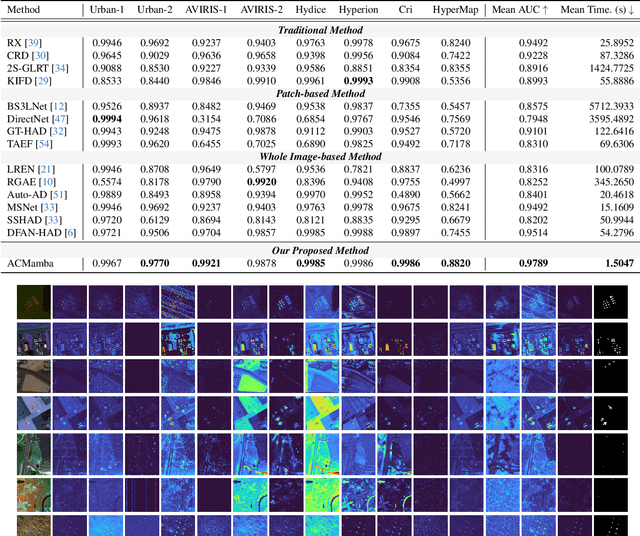
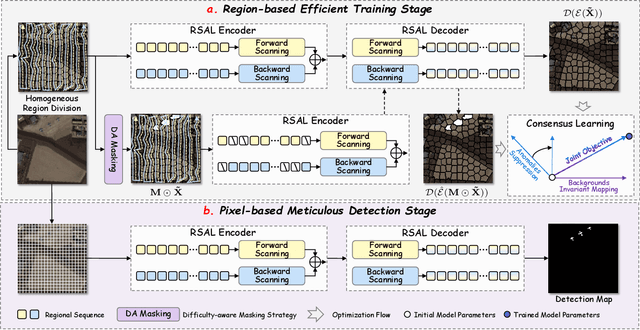
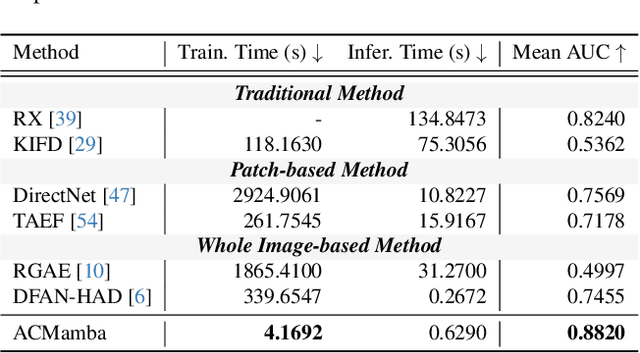
Unsupervised anomaly detection in hyperspectral images (HSI), aiming to detect unknown targets from backgrounds, is challenging for earth surface monitoring. However, current studies are hindered by steep computational costs due to the high-dimensional property of HSI and dense sampling-based training paradigm, constraining their rapid deployment. Our key observation is that, during training, not all samples within the same homogeneous area are indispensable, whereas ingenious sampling can provide a powerful substitute for reducing costs. Motivated by this, we propose an Asymmetrical Consensus State Space Model (ACMamba) to significantly reduce computational costs without compromising accuracy. Specifically, we design an asymmetrical anomaly detection paradigm that utilizes region-level instances as an efficient alternative to dense pixel-level samples. In this paradigm, a low-cost Mamba-based module is introduced to discover global contextual attributes of regions that are essential for HSI reconstruction. Additionally, we develop a consensus learning strategy from the optimization perspective to simultaneously facilitate background reconstruction and anomaly compression, further alleviating the negative impact of anomaly reconstruction. Theoretical analysis and extensive experiments across eight benchmarks verify the superiority of ACMamba, demonstrating a faster speed and stronger performance over the state-of-the-art.
DiffMOD: Progressive Diffusion Point Denoising for Moving Object Detection in Remote Sensing
Apr 14, 2025
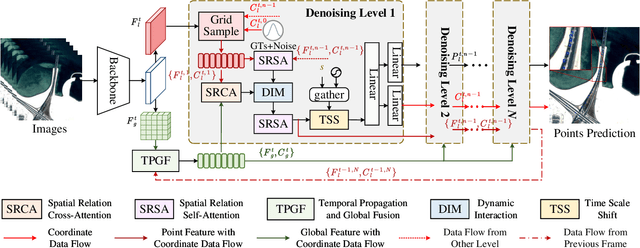
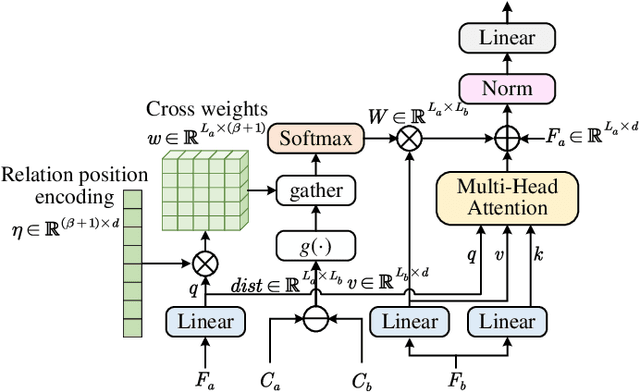
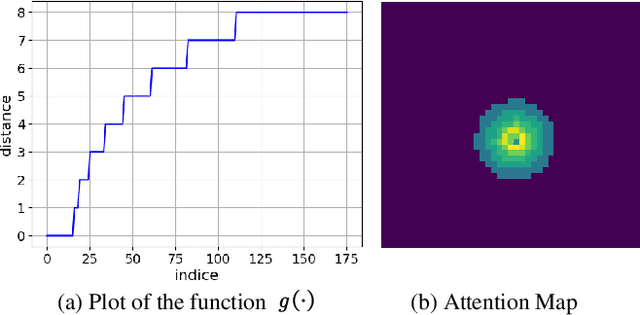
Moving object detection (MOD) in remote sensing is significantly challenged by low resolution, extremely small object sizes, and complex noise interference. Current deep learning-based MOD methods rely on probability density estimation, which restricts flexible information interaction between objects and across temporal frames. To flexibly capture high-order inter-object and temporal relationships, we propose a point-based MOD in remote sensing. Inspired by diffusion models, the network optimization is formulated as a progressive denoising process that iteratively recovers moving object centers from sparse noisy points. Specifically, we sample scattered features from the backbone outputs as atomic units for subsequent processing, while global feature embeddings are aggregated to compensate for the limited coverage of sparse point features. By modeling spatial relative positions and semantic affinities, Spatial Relation Aggregation Attention is designed to enable high-order interactions among point-level features for enhanced object representation. To enhance temporal consistency, the Temporal Propagation and Global Fusion module is designed, which leverages an implicit memory reasoning mechanism for robust cross-frame feature integration. To align with the progressive denoising process, we propose a progressive MinK optimal transport assignment strategy that establishes specialized learning objectives at each denoising level. Additionally, we introduce a missing loss function to counteract the clustering tendency of denoised points around salient objects. Experiments on the RsData remote sensing MOD dataset show that our MOD method based on scattered point denoising can more effectively explore potential relationships between sparse moving objects and improve the detection capability and temporal consistency.
SACB-Net: Spatial-awareness Convolutions for Medical Image Registration
Mar 25, 2025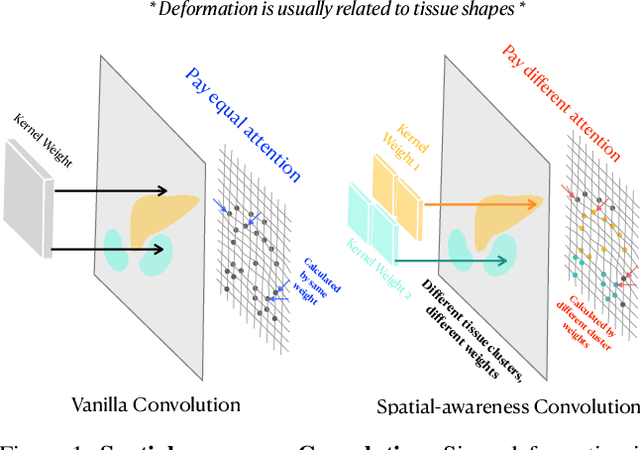
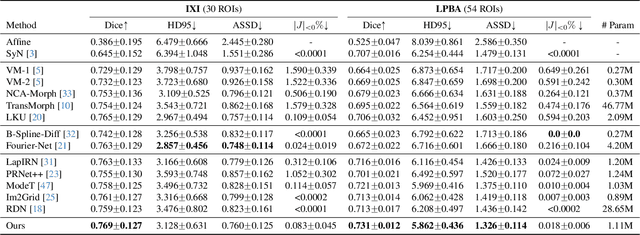
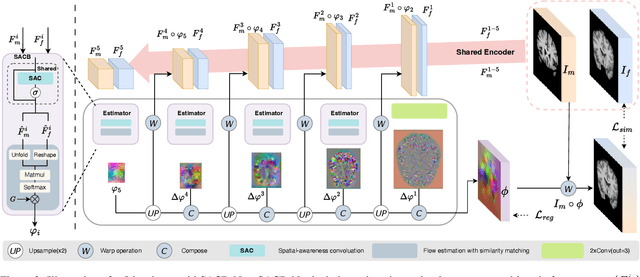
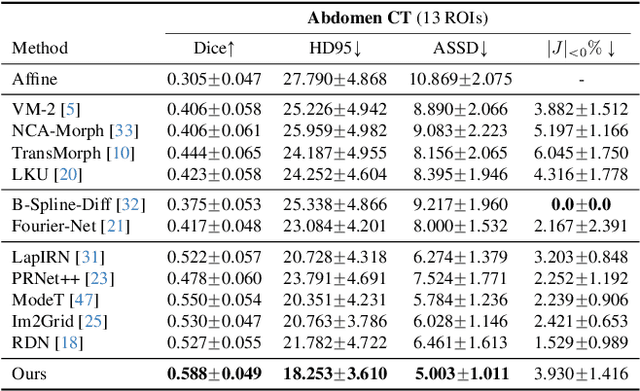
Deep learning-based image registration methods have shown state-of-the-art performance and rapid inference speeds. Despite these advances, many existing approaches fall short in capturing spatially varying information in non-local regions of feature maps due to the reliance on spatially-shared convolution kernels. This limitation leads to suboptimal estimation of deformation fields. In this paper, we propose a 3D Spatial-Awareness Convolution Block (SACB) to enhance the spatial information within feature representations. Our SACB estimates the spatial clusters within feature maps by leveraging feature similarity and subsequently parameterizes the adaptive convolution kernels across diverse regions. This adaptive mechanism generates the convolution kernels (weights and biases) tailored to spatial variations, thereby enabling the network to effectively capture spatially varying information. Building on SACB, we introduce a pyramid flow estimator (named SACB-Net) that integrates SACBs to facilitate multi-scale flow composition, particularly addressing large deformations. Experimental results on the brain IXI and LPBA datasets as well as Abdomen CT datasets demonstrate the effectiveness of SACB and the superiority of SACB-Net over the state-of-the-art learning-based registration methods. The code is available at https://github.com/x-xc/SACB_Net .
MathMistake Checker: A Comprehensive Demonstration for Step-by-Step Math Problem Mistake Finding by Prompt-Guided LLMs
Mar 06, 2025We propose a novel system, MathMistake Checker, designed to automate step-by-step mistake finding in mathematical problems with lengthy answers through a two-stage process. The system aims to simplify grading, increase efficiency, and enhance learning experiences from a pedagogical perspective. It integrates advanced technologies, including computer vision and the chain-of-thought capabilities of the latest large language models (LLMs). Our system supports open-ended grading without reference answers and promotes personalized learning by providing targeted feedback. We demonstrate its effectiveness across various types of math problems, such as calculation and word problems.
RAG4ITOps: A Supervised Fine-Tunable and Comprehensive RAG Framework for IT Operations and Maintenance
Oct 21, 2024With the ever-increasing demands on Question Answering (QA) systems for IT operations and maintenance, an efficient and supervised fine-tunable framework is necessary to ensure the data security, private deployment and continuous upgrading. Although Large Language Models (LLMs) have notably improved the open-domain QA's performance, how to efficiently handle enterprise-exclusive corpora and build domain-specific QA systems are still less-studied for industrial applications. In this paper, we propose a general and comprehensive framework based on Retrieval Augmented Generation (RAG) and facilitate the whole business process of establishing QA systems for IT operations and maintenance. In accordance with the prevailing RAG method, our proposed framework, named with RAG4ITOps, composes of two major stages: (1) Models Fine-tuning \& Data Vectorization, and (2) Online QA System Process. At the Stage 1, we leverage a contrastive learning method with two negative sampling strategies to fine-tune the embedding model, and design the instruction templates to fine-tune the LLM with a Retrieval Augmented Fine-Tuning method. At the Stage 2, an efficient process of QA system is built for serving. We collect enterprise-exclusive corpora from the domain of cloud computing, and the extensive experiments show that our method achieves superior results than counterparts on two kinds of QA tasks. Our experiment also provide a case for applying the RAG4ITOps to real-world enterprise-level applications.
S$^2$Mamba: A Spatial-spectral State Space Model for Hyperspectral Image Classification
Apr 28, 2024



Land cover analysis using hyperspectral images (HSI) remains an open problem due to their low spatial resolution and complex spectral information. Recent studies are primarily dedicated to designing Transformer-based architectures for spatial-spectral long-range dependencies modeling, which is computationally expensive with quadratic complexity. Selective structured state space model (Mamba), which is efficient for modeling long-range dependencies with linear complexity, has recently shown promising progress. However, its potential in hyperspectral image processing that requires handling numerous spectral bands has not yet been explored. In this paper, we innovatively propose S$^2$Mamba, a spatial-spectral state space model for hyperspectral image classification, to excavate spatial-spectral contextual features, resulting in more efficient and accurate land cover analysis. In S$^2$Mamba, two selective structured state space models through different dimensions are designed for feature extraction, one for spatial, and the other for spectral, along with a spatial-spectral mixture gate for optimal fusion. More specifically, S$^2$Mamba first captures spatial contextual relations by interacting each pixel with its adjacent through a Patch Cross Scanning module and then explores semantic information from continuous spectral bands through a Bi-directional Spectral Scanning module. Considering the distinct expertise of the two attributes in homogenous and complicated texture scenes, we realize the Spatial-spectral Mixture Gate by a group of learnable matrices, allowing for the adaptive incorporation of representations learned across different dimensions. Extensive experiments conducted on HSI classification benchmarks demonstrate the superiority and prospect of S$^2$Mamba. The code will be available at: https://github.com/PURE-melo/S2Mamba.
Remote Sensing Object Detection Meets Deep Learning: A Meta-review of Challenges and Advances
Sep 13, 2023



Remote sensing object detection (RSOD), one of the most fundamental and challenging tasks in the remote sensing field, has received longstanding attention. In recent years, deep learning techniques have demonstrated robust feature representation capabilities and led to a big leap in the development of RSOD techniques. In this era of rapid technical evolution, this review aims to present a comprehensive review of the recent achievements in deep learning based RSOD methods. More than 300 papers are covered in this review. We identify five main challenges in RSOD, including multi-scale object detection, rotated object detection, weak object detection, tiny object detection, and object detection with limited supervision, and systematically review the corresponding methods developed in a hierarchical division manner. We also review the widely used benchmark datasets and evaluation metrics within the field of RSOD, as well as the application scenarios for RSOD. Future research directions are provided for further promoting the research in RSOD.