 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-driven pulmonary arteries and veins segmentation reveals demography-associated pulmonary vasculature anatomy
Apr 11, 2024Pulmonary artery-vein segmentation is crucial for diagnosing pulmonary diseases and surgical planning, and is traditionally achieved by Computed Tomography Pulmonary Angiography (CTPA). However, concerns regarding adverse health effects from contrast agents used in CTPA have constrained its clinical utility. In contrast, identifying arteries and veins using non-contrast CT, a conventional and low-cost clinical examination routine, has long been considered impossible. Here we propose a High-abundant Pulmonary Artery-vein Segmentation (HiPaS) framework achieving accurate artery-vein segmentation on both non-contrast CT and CTPA across various spatial resolutions. HiPaS first performs spatial normalization on raw CT scans via a super-resolution module, and then iteratively achieves segmentation results at different branch levels by utilizing the low-level vessel segmentation as a prior for high-level vessel segmentation. We trained and validated HiPaS on our established multi-centric dataset comprising 1,073 CT volumes with meticulous manual annotation. Both quantitative experiments and clinical evaluation demonstrated the superior performance of HiPaS, achieving a dice score of 91.8% and a sensitivity of 98.0%. Further experiments demonstrated the non-inferiority of HiPaS segmentation on non-contrast CT compared to segmentation on CTPA. Employing HiPaS, we have conducted an anatomical study of pulmonary vasculature on 10,613 participants in China (five sites), discovering a new association between pulmonary vessel abundance and sex and age: vessel abundance is significantly higher in females than in males, and slightly decreases with age, under the controlling of lung volumes (p < 0.0001). HiPaS realizing accurate artery-vein segmentation delineates a promising avenue for clinical diagnosis and understanding pulmonary physiology in a non-invasive manner.
Efficient automatic segmentation for multi-level pulmonary arteries: The PARSE challenge
Apr 07, 2023



Efficient automatic segmentation of multi-level (i.e. main and branch) pulmonary arteries (PA) in CTPA images plays a significant role in clinical applications. However, most existing methods concentrate only on main PA or branch PA segmentation separately and ignore segmentation efficiency. Besides, there is no public large-scale dataset focused on PA segmentation, which makes it highly challenging to compare the different methods. To benchmark multi-level PA segmentation algorithms, we organized the first \textbf{P}ulmonary \textbf{AR}tery \textbf{SE}gmentation (PARSE) challenge. On the one hand, we focus on both the main PA and the branch PA segmentation. On the other hand, for better clinical application, we assign the same score weight to segmentation efficiency (mainly running time and GPU memory consumption during inference) while ensuring PA segmentation accuracy. We present a summary of the top algorithms and offer some suggestions for efficient and accurate multi-level PA automatic segmentation. We provide the PARSE challenge as open-access for the community to benchmark future algorithm developments at \url{https://parse2022.grand-challenge.org/Parse2022/}.
Fourier-Net: Fast Image Registration with Band-limited Deformation
Nov 29, 2022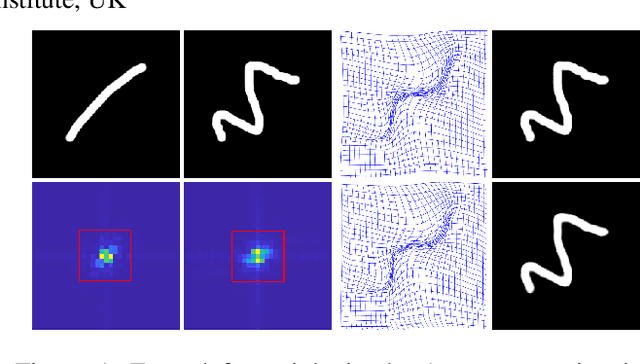
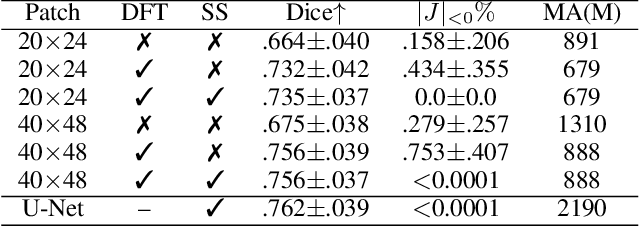
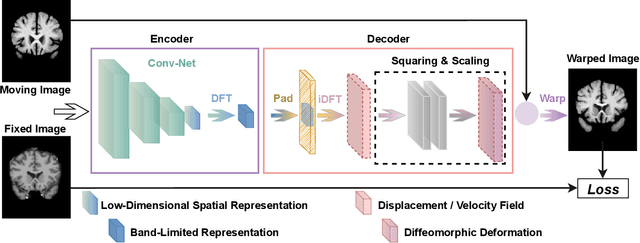
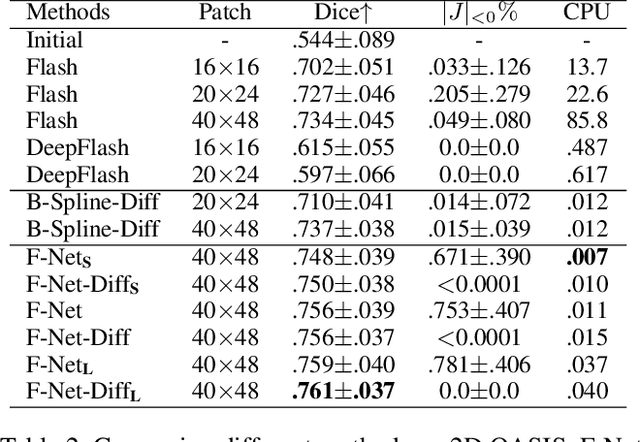
Unsupervised image registration commonly adopts U-Net style networks to predict dense displacement fields in the full-resolution spatial domain. For high-resolution volumetric image data, this process is however resource intensive and time-consuming. To tackle this problem, we propose the Fourier-Net, replacing the expansive path in a U-Net style network with a parameter-free model-driven decoder. Specifically, instead of our Fourier-Net learning to output a full-resolution displacement field in the spatial domain, we learn its low-dimensional representation in a band-limited Fourier domain. This representation is then decoded by our devised model-driven decoder (consisting of a zero padding layer and an inverse discrete Fourier transform layer) to the dense, full-resolution displacement field in the spatial domain. These changes allow our unsupervised Fourier-Net to contain fewer parameters and computational operations, resulting in faster inference speeds. Fourier-Net is then evaluated on two public 3D brain datasets against various state-of-the-art approaches. For example, when compared to a recent transformer-based method, i.e., TransMorph, our Fourier-Net, only using 0.22$\%$ of its parameters and 6.66$\%$ of the mult-adds, achieves a 0.6\% higher Dice score and an 11.48$\times$ faster inference speed. Code is available at \url{https://github.com/xi-jia/Fourier-Net}.
U-Net vs Transformer: Is U-Net Outdated in Medical Image Registration?
Aug 13, 2022
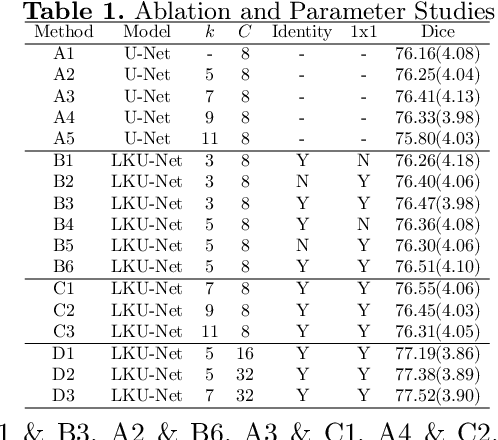
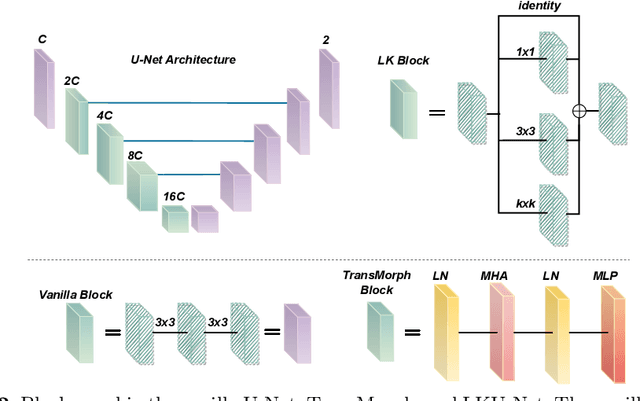
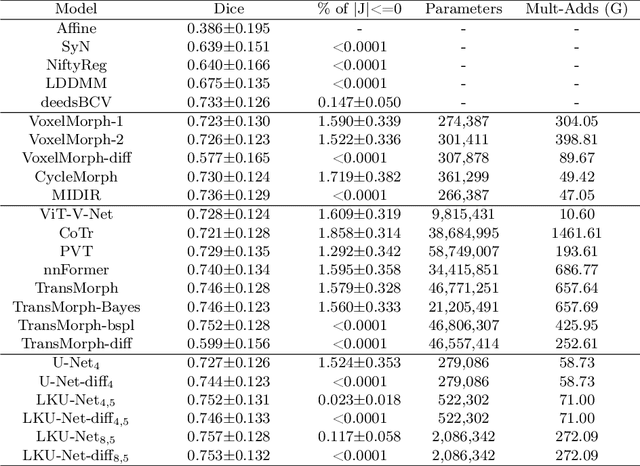
Due to their extreme long-range modeling capability, vision transformer-based networks have become increasingly popular in deformable image registration. We believe, however, that the receptive field of a 5-layer convolutional U-Net is sufficient to capture accurate deformations without needing long-range dependencies. The purpose of this study is therefore to investigate whether U-Net-based methods are outdated compared to modern transformer-based approaches when applied to medical image registration. For this, we propose a large kernel U-Net (LKU-Net) by embedding a parallel convolutional block to a vanilla U-Net in order to enhance the effective receptive field. On the public 3D IXI brain dataset for atlas-based registration, we show that the performance of the vanilla U-Net is already comparable with that of state-of-the-art transformer-based networks (such as TransMorph), and that the proposed LKU-Net outperforms TransMorph by using only 1.12% of its parameters and 10.8% of its mult-adds operations. We further evaluate LKU-Net on a MICCAI Learn2Reg 2021 challenge dataset for inter-subject registration, our LKU-Net also outperforms TransMorph on this dataset and ranks first on the public leaderboard as of the submission of this work. With only modest modifications to the vanilla U-Net, we show that U-Net can outperform transformer-based architectures on inter-subject and atlas-based 3D medical image registration. Code is available at https://github.com/xi-jia/LKU-Net.
Structure Unbiased Adversarial Model for Medical Image Segmentation
May 26, 2022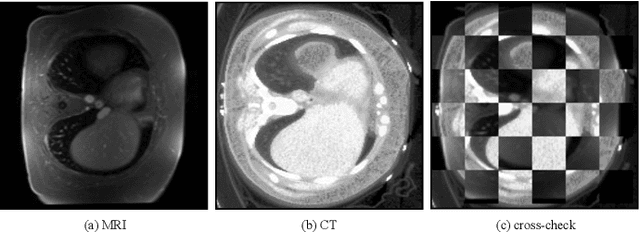
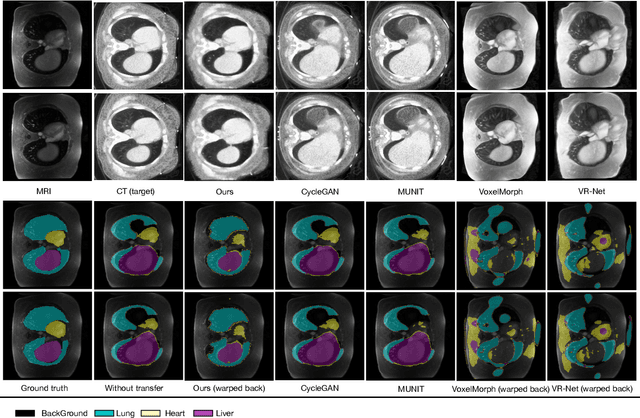
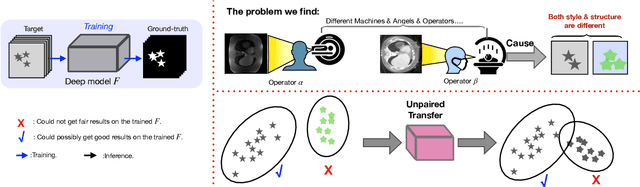
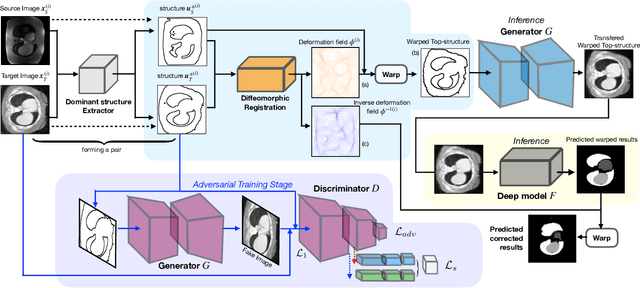
Generative models have been widely proposed in image recognition to generate more images where the distribution is similar to that of the real images. It often introduces a discriminator network to discriminate original real data and generated data. However, such discriminator often considers the distribution of the data and did not pay enough attention to the intrinsic gap due to structure. In this paper, we reformulate a new image to image translation problem to reduce structural gap, in addition to the typical intensity distribution gap. We further propose a simple yet important Structure Unbiased Adversarial Model for Medical Image Segmentation (SUAM) with learnable inverse structural deformation for medical image segmentation. It consists of a structure extractor, an attention diffeomorphic registration and a structure \& intensity distribution rendering module. The structure extractor aims to extract the dominant structure of the input image. The attention diffeomorphic registration is proposed to reduce the structure gap with an inverse deformation field to warp the prediction masks back to their original form. The structure rendering module is to render the deformed structure to an image with targeted intensity distribution. We apply the proposed SUAM on both optical coherence tomography (OCT), magnetic resonance imaging (MRI) and computerized tomography (CT) data. Experimental results show that the proposed method has the capability to transfer both intensity and structure distributions.