 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinGPT-R1: Adapter-Only Dual Distillation for Efficient Dermatology Reasoning
Nov 19, 2025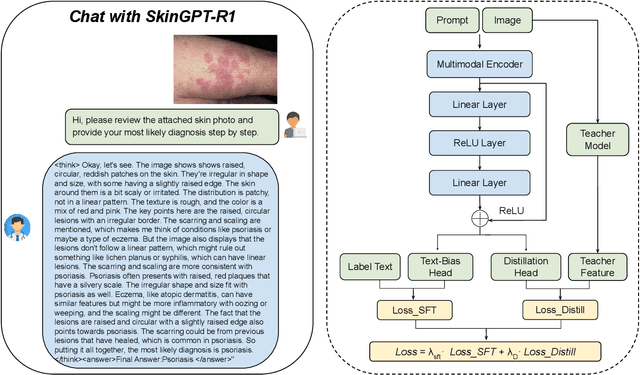



We present SkinGPT-R1, a dermatology focused vision language model that makes diagnostic chain of thought reasoning explicit, step by step, and verifiable. To support skin specific reasoning, we build DermCoT, a corpus of standardized dermatologic chain of thought narratives that combines 10,000 DermEval filtered training cases with 3,000 dermatologist scored certified cases, and we define DermEval as a physician aligned six dimensional evaluator and DermBench as the corresponding benchmark for dermatologic chain of thought quality. On DermBench, across 14 general, reasoning, and medical vision language models, SkinGPT-R1 achieves an average score of 4.031 out of 5 over the six clinician defined dimensions, ranks 1st among all systems, and improves the average score over Vision-R1 by about 41%. On three dermatology classification benchmarks, SkinGPT-R1 delivers stable accuracy gains over Vision-R1 and remains competitive among strong vision language models. Ablation results further show that DermCoT based chain of thought supervision provides substantial improvements over the base model and that adding dermatology aware visual distillation yields consistent additional gains in both narrative quality and recognition.
CoTBox-TTT: Grounding Medical VQA with Visual Chain-of-Thought Boxes During Test-time Training
Nov 16, 2025Medical visual question answering could support clinical decision making, yet current systems often fail under domain shift and produce answers that are weakly grounded in image evidence. This reliability gap arises when models attend to spurious regions and when retraining or additional labels are impractical at deployment time. We address this setting with CoTBox-TTT, an evidence-first test-time training approach that adapts a vision-language model at inference while keeping all backbones frozen. The method updates only a small set of continuous soft prompts. It identifies question-relevant regions through a visual chain-of-thought signal and encourages answer consistency across the original image and a localized crop. The procedure is label free, and plug and play with diverse backbones. Experiments on medical VQA show that the approach is practical for real deployments. For instance, adding CoTBox-TTT to LLaVA increases closed-ended accuracy by 12.3% on pathVQA.
Towards Trustworthy Dermatology MLLMs: A Benchmark and Multimodal Evaluator for Diagnostic Narratives
Nov 12, 2025Multimodal large language models (LLMs) are increasingly used to generate dermatology diagnostic narratives directly from images. However, reliable evaluation remains the primary bottleneck for responsible clinical deployment. We introduce a novel evaluation framework that combines DermBench, a meticulously curated benchmark, with DermEval, a robust automatic evaluator, to enable clinically meaningful, reproducible, and scalable assessment. We build DermBench, which pairs 4,000 real-world dermatology images with expert-certified diagnostic narratives and uses an LLM-based judge to score candidate narratives across clinically grounded dimensions, enabling consistent and comprehensive evaluation of multimodal models. For individual case assessment, we train DermEval, a reference-free multimodal evaluator. Given an image and a generated narrative, DermEval produces a structured critique along with an overall score and per-dimension ratings. This capability enables fine-grained, per-case analysis, which is critical for identifying model limitations and biases. Experiments on a diverse dataset of 4,500 cases demonstrate that DermBench and DermEval achieve close alignment with expert ratings, with mean deviations of 0.251 and 0.117 (out of 5), respectively, providing reliable measurement of diagnostic ability and trustworthiness across different multimodal LLMs.
BioinfoMCP: A Unified Platform Enabling MCP Interfaces in Agentic Bioinformatics
Oct 02, 2025Bioinformatics tools are essential for complex computational biology tasks, yet their integration with emerging AI-agent frameworks is hindered by incompatible interfaces, heterogeneous input-output formats, and inconsistent parameter conventions. The Model Context Protocol (MCP) provides a standardized framework for tool-AI communication, but manually converting hundreds of existing and rapidly growing specialized bioinformatics tools into MCP-compliant servers is labor-intensive and unsustainable. Here, we present BioinfoMCP, a unified platform comprising two components: BioinfoMCP Converter, which automatically generates robust MCP servers from tool documentation using large language models, and BioinfoMCP Benchmark, which systematically validates the reliability and versatility of converted tools across diverse computational tasks. We present a platform of 38 MCP-converted bioinformatics tools, extensively validated to show that 94.7% successfully executed complex workflows across three widely used AI-agent platforms. By removing technical barriers to AI automation, BioinfoMCP enables natural-language interaction with sophisticated bioinformatics analyses without requiring extensive programming expertise, offering a scalable path to intelligent, interoperable computational biology.
Evaluating and Mitigating Bias in AI-Based Medical Text Generation
Apr 24, 2025Artificial intelligence (AI) systems, particularly those based on deep learning models, have increasingly achieved expert-level performance in medical applications. However, there is growing concern that such AI systems may reflect and amplify human bias, and reduce the quality of their performance in historically under-served populations. The fairness issue has attracted considerable research interest in the medical imaging classification field, yet it remains understudied in the text generation domain. In this study, we investigate the fairness problem in text generation within the medical field and observe significant performance discrepancies across different races, sexes, and age groups, including intersectional groups, various model scales, and different evaluation metrics. To mitigate this fairness issue, we propose an algorithm that selectively optimizes those underperformed groups to reduce bias. The selection rules take into account not only word-level accuracy but also the pathology accuracy to the target reference, while ensuring that the entire process remains fully differentiable for effective model training. Our evaluations across multiple backbones, datasets, and modalities demonstrate that our proposed algorithm enhances fairness in text generation without compromising overall performance. Specifically, the disparities among various groups across different metrics were diminished by more than 30% with our algorithm, while the relative change in text generation accuracy was typically within 2%. By reducing the bias generated by deep learning models, our proposed approach can potentially alleviate concerns about the fairness and reliability of text generation diagnosis in medical domain. Our code is publicly available to facilitate further research at https://github.com/iriscxy/GenFair.
* 12 pages, 8 figures, published in Nature Computational Science
ScholarChemQA: Unveiling the Power of Language Models in Chemical Research Question Answering
Jul 24, 2024



Question Answering (QA) effectively evaluates language models' reasoning and knowledge depth. While QA datasets are plentiful in areas like general domain and biomedicine, academic chemistry is less explored. Chemical QA plays a crucial role in both education and research by effectively translating complex chemical information into readily understandable format. Addressing this gap, we introduce ScholarChemQA, a large-scale QA dataset constructed from chemical papers. This dataset reflects typical real-world challenges, including an imbalanced data distribution and a substantial amount of unlabeled data that can be potentially useful. Correspondingly, we introduce a QAMatch model, specifically designed to effectively answer chemical questions by fully leveraging our collected data. We first address the issue of imbalanced label distribution by re-weighting the instance-wise loss based on the inverse frequency of each class, ensuring minority classes are not dominated by majority ones during optimization. Next, we utilize the unlabeled data to enrich the learning process, generating a variety of augmentations based on a SoftMix operation and ensuring their predictions align with the same target, i.e., pseudo-labels. To ensure the quality of the pseudo-labels, we propose a calibration procedure aimed at closely aligning the pseudo-label estimates of individual samples with a desired ground truth distribution. Experiments show that our QAMatch significantly outperforms the recent similar-scale baselines and Large Language Models (LLMs) not only on our ScholarChemQA dataset but also on four benchmark datasets. We hope our benchmark and model can facilitate and promote more research on chemical QA.
SkinCAP: A Multi-modal Dermatology Dataset Annotated with Rich Medical Captions
May 28, 2024



With the widespread application of artificial intelligence (AI), particularly deep learning (DL) and vision-based large language models (VLLMs), in skin disease diagnosis, the need for interpretability becomes crucial. However, existing dermatology datasets are limited in their inclusion of concept-level meta-labels, and none offer rich medical descriptions in natural language. This deficiency impedes the advancement of LLM-based methods in dermatological diagnosis. To address this gap and provide a meticulously annotated dermatology dataset with comprehensive natural language descriptions, we introduce SkinCAP: a multi-modal dermatology dataset annotated with rich medical captions. SkinCAP comprises 4,000 images sourced from the Fitzpatrick 17k skin disease dataset and the Diverse Dermatology Images dataset, annotated by board-certified dermatologists to provide extensive medical descriptions and captions. Notably, SkinCAP represents the world's first such dataset and is publicly available at https://huggingface.co/datasets/joshuachou/SkinCAP.
Deep learning-driven pulmonary arteries and veins segmentation reveals demography-associated pulmonary vasculature anatomy
Apr 11, 2024Pulmonary artery-vein segmentation is crucial for diagnosing pulmonary diseases and surgical planning, and is traditionally achieved by Computed Tomography Pulmonary Angiography (CTPA). However, concerns regarding adverse health effects from contrast agents used in CTPA have constrained its clinical utility. In contrast, identifying arteries and veins using non-contrast CT, a conventional and low-cost clinical examination routine, has long been considered impossible. Here we propose a High-abundant Pulmonary Artery-vein Segmentation (HiPaS) framework achieving accurate artery-vein segmentation on both non-contrast CT and CTPA across various spatial resolutions. HiPaS first performs spatial normalization on raw CT scans via a super-resolution module, and then iteratively achieves segmentation results at different branch levels by utilizing the low-level vessel segmentation as a prior for high-level vessel segmentation. We trained and validated HiPaS on our established multi-centric dataset comprising 1,073 CT volumes with meticulous manual annotation. Both quantitative experiments and clinical evaluation demonstrated the superior performance of HiPaS, achieving a dice score of 91.8% and a sensitivity of 98.0%. Further experiments demonstrated the non-inferiority of HiPaS segmentation on non-contrast CT compared to segmentation on CTPA. Employing HiPaS, we have conducted an anatomical study of pulmonary vasculature on 10,613 participants in China (five sites), discovering a new association between pulmonary vessel abundance and sex and age: vessel abundance is significantly higher in females than in males, and slightly decreases with age, under the controlling of lung volumes (p < 0.0001). HiPaS realizing accurate artery-vein segmentation delineates a promising avenue for clinical diagnosis and understanding pulmonary physiology in a non-invasive manner.
Automated Bioinformatics Analysis via AutoBA
Sep 06, 2023With the fast-growing and evolving omics data, the demand for streamlined and adaptable tools to handle the analysis continues to grow. In response to this need, we introduce Auto Bioinformatics Analysis (AutoBA), an autonomous AI agent based on a large language model designed explicitly for conventional omics data analysis. AutoBA simplifies the analytical process by requiring minimal user input while delivering detailed step-by-step plans for various bioinformatics tasks. Through rigorous validation by expert bioinformaticians, AutoBA's robustness and adaptability are affirmed across a diverse range of omics analysis cases, including whole genome sequencing (WGS), RNA sequencing (RNA-seq), single-cell RNA-seq, ChIP-seq, and spatial transcriptomics. AutoBA's unique capacity to self-design analysis processes based on input data variations further underscores its versatility. Compared with online bioinformatic services, AutoBA deploys the analysis locally, preserving data privacy. Moreover, different from the predefined pipeline, AutoBA has adaptability in sync with emerging bioinformatics tools. Overall, AutoBA represents a convenient tool, offering robustness and adaptability for complex omics data analysis.
Path to Medical AGI: Unify Domain-specific Medical LLMs with the Lowest Cost
Jun 19, 2023Medical artificial general intelligence (AGI) is an emerging field that aims to develop systems specifically designed for medical applications that possess the ability to understand, learn, and apply knowledge across a wide range of tasks and domains. Large language models (LLMs) represent a significant step towards AGI. However, training cross-domain LLMs in the medical field poses significant challenges primarily attributed to the requirement of collecting data from diverse domains. This task becomes particularly difficult due to privacy restrictions and the scarcity of publicly available medical datasets. Here, we propose Medical AGI (MedAGI), a paradigm to unify domain-specific medical LLMs with the lowest cost, and suggest a possible path to achieve medical AGI. With an increasing number of domain-specific professional multimodal LLMs in the medical field being developed, MedAGI is designed to automatically select appropriate medical models by analyzing users' questions with our novel adaptive expert selection algorithm. It offers a unified approach to existing LLMs in the medical field, eliminating the need for retraining regardless of the introduction of new models. This characteristic renders it a future-proof solution in the dynamically advancing medical domain. To showcase the resilience of MedAGI, we conducted an evaluation across three distinct medical domains: dermatology diagnosis, X-ray diagnosis, and analysis of pathology pictures. The results demonstrated that MedAGI exhibited remarkable versatility and scalability, delivering exceptional performance across diverse domains. Our code is publicly available to facilitate further research at https://github.com/JoshuaChou2018/MedAGI.