 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPA: Achieving Consensus in LLM Alignment via Self-Priority Optimization
Nov 09, 2025In high-stakes scenarios-such as self-harm, legal, or medical queries-LLMs must be both trustworthy and helpful. However, these goals often conflict. We propose priority alignment, a new alignment paradigm that enforces a strict "trustworthy-before-helpful" ordering: optimization of helpfulness is conditioned on first meeting trustworthy thresholds (e.g., harmlessness or honesty). To realize this, we introduce Self-Priority Alignment (SPA)-a fully unsupervised framework that generates diverse responses, self-evaluates them and refines them by the model itself, and applies dual-criterion denoising to remove inconsistency and control variance. From this, SPA constructs lexicographically ordered preference pairs and fine-tunes the model using an uncertainty-weighted alignment loss that emphasizes high-confidence, high-gap decisions. Experiments across multiple benchmarks show that SPA improves helpfulness without compromising safety, outperforming strong baselines while preserving general capabilities. Our results demonstrate that SPA provides a scalable and interpretable alignment strategy for critical LLM applications.
Better Datasets Start From RefineLab: Automatic Optimization for High-Quality Dataset Refinement
Nov 09, 2025High-quality Question-Answer (QA) datasets are foundational for reliable Large Language Model (LLM) evaluation, yet even expert-crafted datasets exhibit persistent gaps in domain coverage, misaligned difficulty distributions, and factual inconsistencies. The recent surge in generative model-powered datasets has compounded these quality challenges. In this work, we introduce RefineLab, the first LLM-driven framework that automatically refines raw QA textual data into high-quality datasets under a controllable token-budget constraint. RefineLab takes a set of target quality attributes (such as coverage and difficulty balance) as refinement objectives, and performs selective edits within a predefined token budget to ensure practicality and efficiency. In essence, RefineLab addresses a constrained optimization problem: improving the quality of QA samples as much as possible while respecting resource limitations. With a set of available refinement operations (e.g., rephrasing, distractor replacement), RefineLab takes as input the original dataset, a specified set of target quality dimensions, and a token budget, and determines which refinement operations should be applied to each QA sample. This process is guided by an assignment module that selects optimal refinement strategies to maximize overall dataset quality while adhering to the budget constraint. Experiments demonstrate that RefineLab consistently narrows divergence from expert datasets across coverage, difficulty alignment, factual fidelity, and distractor quality. RefineLab pioneers a scalable, customizable path to reproducible dataset design, with broad implications for LLM evaluation.
TableDART: Dynamic Adaptive Multi-Modal Routing for Table Understanding
Sep 18, 2025Modeling semantic and structural information from tabular data remains a core challenge for effective table understanding. Existing Table-as-Text approaches flatten tables for large language models (LLMs), but lose crucial structural cues, while Table-as-Image methods preserve structure yet struggle with fine-grained semantics. Recent Table-as-Multimodality strategies attempt to combine textual and visual views, but they (1) statically process both modalities for every query-table pair within a large multimodal LLMs (MLLMs), inevitably introducing redundancy and even conflicts, and (2) depend on costly fine-tuning of MLLMs. In light of this, we propose TableDART, a training-efficient framework that integrates multimodal views by reusing pretrained single-modality models. TableDART introduces a lightweight 2.59M-parameter MLP gating network that dynamically selects the optimal path (either Text-only, Image-only, or Fusion) for each table-query pair, effectively reducing redundancy and conflicts from both modalities. In addition, we propose a novel agent to mediate cross-modal knowledge integration by analyzing outputs from text- and image-based models, either selecting the best result or synthesizing a new answer through reasoning. This design avoids the prohibitive costs of full MLLM fine-tuning. Extensive experiments on seven benchmarks show that TableDART establishes new state-of-the-art performance among open-source models, surpassing the strongest baseline by an average of 4.02%. The code is available at: https://anonymous.4open.science/r/TableDART-C52B
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Sep 18, 2025Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.
Generative Models for Synthetic Data: Transforming Data Mining in the GenAI Era
Aug 27, 2025Generative models such as Large Language Models, Diffusion Models, and generative adversarial networks have recently revolutionized the creation of synthetic data, offering scalable solutions to data scarcity, privacy, and annotation challenges in data mining. This tutorial introduces the foundations and latest advances in synthetic data generation, covers key methodologies and practical frameworks, and discusses evaluation strategies and applications. Attendees will gain actionable insights into leveraging generative synthetic data to enhance data mining research and practice. More information can be found on our website: https://syndata4dm.github.io/.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
Seeing the Invisible: Machine learning-Based QPI Kernel Extraction via Latent Alignment
Jun 05, 2025Quasiparticle interference (QPI) imaging is a powerful tool for probing electronic structures in quantum materials, but extracting the single-scatterer QPI pattern (i.e., the kernel) from a multi-scatterer image remains a fundamentally ill-posed inverse problem. In this work, we propose the first AI-based framework for QPI kernel extraction. We introduce a two-step learning strategy that decouples kernel representation learning from observation-to-kernel inference. In the first step, we train a variational autoencoder to learn a compact latent space of scattering kernels. In the second step, we align the latent representation of QPI observations with those of the pre-learned kernels using a dedicated encoder. This design enables the model to infer kernels robustly even under complex, entangled scattering conditions. We construct a diverse and physically realistic QPI dataset comprising 100 unique kernels and evaluate our method against a direct one-step baseline. Experimental results demonstrate that our approach achieves significantly higher extraction accuracy, and improved generalization to unseen kernels.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025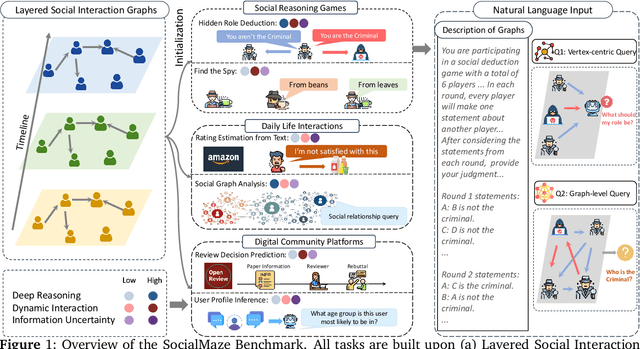
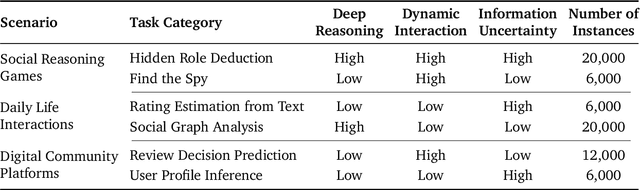
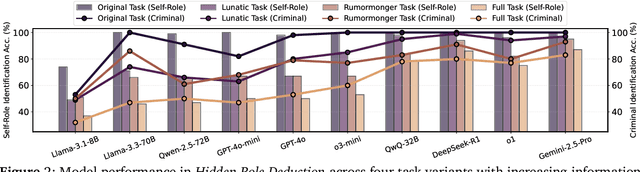
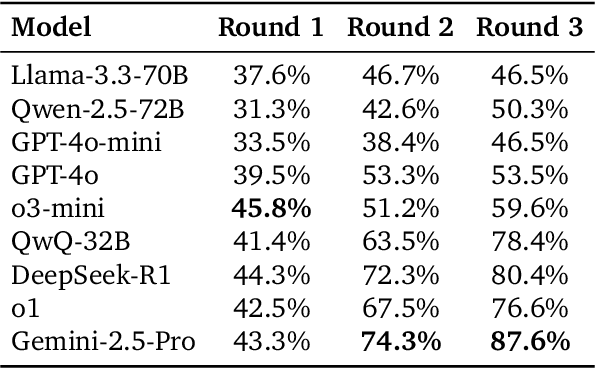
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
Cross-Lingual Pitfalls: Automatic Probing Cross-Lingual Weakness of Multilingual Large Language Models
May 24, 2025Large Language Models (LLMs) have achieved remarkable success in Natural Language Processing (NLP), yet their cross-lingual performance consistency remains a significant challenge. This paper introduces a novel methodology for efficiently identifying inherent cross-lingual weaknesses in LLMs. Our approach leverages beam search and LLM-based simulation to generate bilingual question pairs that expose performance discrepancies between English and target languages. We construct a new dataset of over 6,000 bilingual pairs across 16 languages using this methodology, demonstrating its effectiveness in revealing weaknesses even in state-of-the-art models. The extensive experiments demonstrate that our method precisely and cost-effectively pinpoints cross-lingual weaknesses, consistently revealing over 50\% accuracy drops in target languages across a wide range of models. Moreover, further experiments investigate the relationship between linguistic similarity and cross-lingual weaknesses, revealing that linguistically related languages share similar performance patterns and benefit from targeted post-training. Code is available at https://github.com/xzx34/Cross-Lingual-Pitfalls.
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking
May 22, 2025LLMs often need effective configurations, like temperature and reasoning steps, to handle tasks requiring sophisticated reasoning and problem-solving, ranging from joke generation to mathematical reasoning. Existing prompting approaches usually adopt general-purpose, fixed configurations that work 'well enough' across tasks but seldom achieve task-specific optimality. To address this gap, we introduce AdaReasoner, an LLM-agnostic plugin designed for any LLM to automate adaptive reasoning configurations for tasks requiring different types of thinking. AdaReasoner is trained using a reinforcement learning (RL) framework, combining a factorized action space with a targeted exploration strategy, along with a pretrained reward model to optimize the policy model for reasoning configurations with only a few-shot guide. AdaReasoner is backed by theoretical guarantees and experiments of fast convergence and a sublinear policy gap. Across six different LLMs and a variety of reasoning tasks, it consistently outperforms standard baselines, preserves out-of-distribution robustness, and yield gains on knowledge-intensive tasks through tailored prompts.