 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-adaptive Expert Pruning for Pre-Training of Mixture-of-Experts Large Language Models
Jan 20, 2026Although Mixture-of-Experts (MoE) Large Language Models (LLMs) deliver superior accuracy with a reduced number of active parameters, their pre-training represents a significant computationally bottleneck due to underutilized experts and limited training efficiency. This work introduces a Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs. In contrast to previous expert pruning approaches that operate primarily in the post-training phase, the proposed algorithm enhances training efficiency by selectively pruning underutilized experts and reorganizing experts across computing devices according to token distribution statistics. Comprehensive experiments demonstrate that LAEP effectively reduces model size and substantially improves pre-training efficiency. In particular, when pre-training the 1010B Base model from scratch, LAEP achieves a 48.3\% improvement in training efficiency alongside a 33.3% parameter reduction, while still delivering excellent performance across multiple domains.
Yuan3.0 Flash: An Open Multimodal Large Language Model for Enterprise Applications
Jan 05, 2026We introduce Yuan3.0 Flash, an open-source Mixture-of-Experts (MoE) MultiModal Large Language Model featuring 3.7B activated parameters and 40B total parameters, specifically designed to enhance performance on enterprise-oriented tasks while maintaining competitive capabilities on general-purpose tasks. To address the overthinking phenomenon commonly observed in Large Reasoning Models (LRMs), we propose Reflection-aware Adaptive Policy Optimization (RAPO), a novel RL training algorithm that effectively regulates overthinking behaviors. In enterprise-oriented tasks such as retrieval-augmented generation (RAG), complex table understanding, and summarization, Yuan3.0 Flash consistently achieves superior performance. Moreover, it also demonstrates strong reasoning capabilities in domains such as mathematics, science, etc., attaining accuracy comparable to frontier model while requiring only approximately 1/4 to 1/2 of the average tokens. Yuan3.0 Flash has been fully open-sourced to facilitate further research and real-world deployment: https://github.com/Yuan-lab-LLM/Yuan3.0.
Five Years of SciCap: What We Learned and Future Directions for Scientific Figure Captioning
Dec 25, 2025Between 2021 and 2025, the SciCap project grew from a small seed-funded idea at The Pennsylvania State University (Penn State) into one of the central efforts shaping the scientific figure-captioning landscape. Supported by a Penn State seed grant, Adobe, and the Alfred P. Sloan Foundation, what began as our attempt to test whether domain-specific training, which was successful in text models like SciBERT, could also work for figure captions expanded into a multi-institution collaboration. Over these five years, we curated, released, and continually updated a large collection of figure-caption pairs from arXiv papers, conducted extensive automatic and human evaluations on both generated and author-written captions, navigated the rapid rise of large language models (LLMs), launched annual challenges, and built interactive systems that help scientists write better captions. In this piece, we look back at the first five years of SciCap and summarize the key technical and methodological lessons we learned. We then outline five major unsolved challenges and propose directions for the next phase of research in scientific figure captioning.
Yuan-TecSwin: A text conditioned Diffusion model with Swin-transformer blocks
Dec 18, 2025Diffusion models have shown remarkable capacity in image synthesis based on their U-shaped architecture and convolutional neural networks (CNN) as basic blocks. The locality of the convolution operation in CNN may limit the model's ability to understand long-range semantic information. To address this issue, we propose Yuan-TecSwin, a text-conditioned diffusion model with Swin-transformer in this work. The Swin-transformer blocks take the place of CNN blocks in the encoder and decoder, to improve the non-local modeling ability in feature extraction and image restoration. The text-image alignment is improved with a well-chosen text encoder, effective utilization of text embedding, and careful design in the incorporation of text condition. Using an adapted time step to search in different diffusion stages, inference performance is further improved by 10%. Yuan-TecSwin achieves the state-of-the-art FID score of 1.37 on ImageNet generation benchmark, without any additional models at different denoising stages. In a side-by-side comparison, we find it difficult for human interviewees to tell the model-generated images from the human-painted ones.
Representation Calibration and Uncertainty Guidance for Class-Incremental Learning based on Vision Language Model
Dec 10, 2025Class-incremental learning requires a learning system to continually learn knowledge of new classes and meanwhile try to preserve previously learned knowledge of old classes. As current state-of-the-art methods based on Vision-Language Models (VLMs) still suffer from the issue of differentiating classes across learning tasks. Here a novel VLM-based continual learning framework for image classification is proposed. In this framework, task-specific adapters are added to the pre-trained and frozen image encoder to learn new knowledge, and a novel cross-task representation calibration strategy based on a mixture of light-weight projectors is used to help better separate all learned classes in a unified feature space, alleviating class confusion across tasks. In addition, a novel inference strategy guided by prediction uncertainty is developed to more accurately select the most appropriate image feature for class prediction. Extensive experiments on multiple datasets under various settings demonstrate the superior performance of our method compared to existing ones.
Mitigating Forgetting Between Supervised and Reinforcement Learning Yields Stronger Reasoners
Oct 06, 2025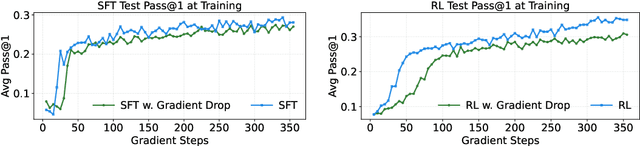
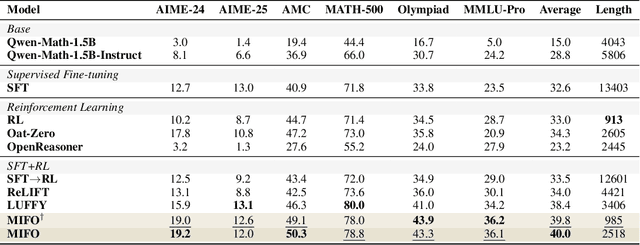
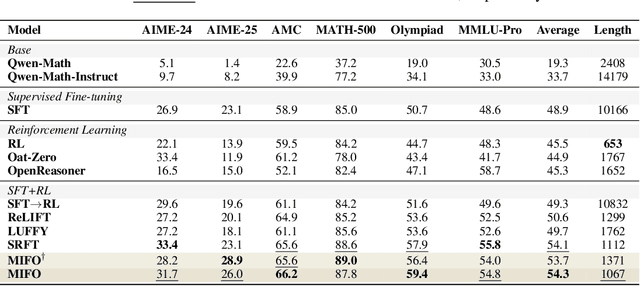

Large Language Models (LLMs) show strong reasoning abilities, often amplified by Chain-of-Thought (CoT) prompting and reinforcement learning (RL). Although RL algorithms can substantially improve reasoning, they struggle to expand reasoning boundaries because they learn from their own reasoning trajectories rather than acquiring external knowledge. Supervised fine-tuning (SFT) offers complementary benefits but typically requires large-scale data and risks overfitting. Recent attempts to combine SFT and RL face three main challenges: data inefficiency, algorithm-specific designs, and catastrophic forgetting. We propose a plug-and-play framework that dynamically integrates SFT into RL by selecting challenging examples for SFT. This approach reduces SFT data requirements and remains agnostic to the choice of RL or SFT algorithm. To mitigate catastrophic forgetting of RL-acquired skills during SFT, we select high-entropy tokens for loss calculation and freeze parameters identified as critical for RL. Our method achieves state-of-the-art (SoTA) reasoning performance using only 1.5% of the SFT data and 20.4% of the RL data used by prior SoTA, providing an efficient and plug-and-play solution for combining SFT and RL in reasoning post-training.
VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
Aug 10, 2025Most organizational data in this world are stored as documents, and visual retrieval plays a crucial role in unlocking the collective intelligence from all these documents. However, existing benchmarks focus on English-only document retrieval or only consider multilingual question-answering on a single-page image. To bridge this gap, we introduce VisR-Bench, a multilingual benchmark designed for question-driven multimodal retrieval in long documents. Our benchmark comprises over 35K high-quality QA pairs across 1.2K documents, enabling fine-grained evaluation of multimodal retrieval. VisR-Bench spans sixteen languages with three question types (figures, text, and tables), offering diverse linguistic and question coverage. Unlike prior datasets, we include queries without explicit answers, preventing models from relying on superficial keyword matching. We evaluate various retrieval models, including text-based methods, multimodal encoders, and MLLMs, providing insights into their strengths and limitations. Our results show that while MLLMs significantly outperform text-based and multimodal encoder models, they still struggle with structured tables and low-resource languages, highlighting key challenges in multilingual visual retrieval.
SAND: Boosting LLM Agents with Self-Taught Action Deliberation
Jul 10, 2025Large Language Model (LLM) agents are commonly tuned with supervised finetuning on ReAct-style expert trajectories or preference optimization over pairwise rollouts. Most of these methods focus on imitating specific expert behaviors or promoting chosen reasoning thoughts and actions over rejected ones. However, without reasoning and comparing over alternatives actions, LLM agents finetuned with these methods may over-commit towards seemingly plausible but suboptimal actions due to limited action space exploration. To address this, in this paper we propose Self-taught ActioN Deliberation (SAND) framework, enabling LLM agents to explicitly deliberate over candidate actions before committing to one. To tackle the challenges of when and what to deliberate given large action space and step-level action evaluation, we incorporate self-consistency action sampling and execution-guided action critique to help synthesize step-wise action deliberation thoughts using the base model of the LLM agent. In an iterative manner, the deliberation trajectories are then used to finetune the LLM agent itself. Evaluating on two representative interactive agent tasks, SAND achieves an average 20% improvement over initial supervised finetuning and also outperforms state-of-the-art agent tuning approaches.
Federated In-Context Learning: Iterative Refinement for Improved Answer Quality
Jun 09, 2025For question-answering (QA) tasks, in-context learning (ICL) enables language models to generate responses without modifying their parameters by leveraging examples provided in the input. However, the effectiveness of ICL heavily depends on the availability of high-quality examples, which are often scarce due to data privacy constraints, annotation costs, and distribution disparities. A natural solution is to utilize examples stored on client devices, but existing approaches either require transmitting model parameters - incurring significant communication overhead - or fail to fully exploit local datasets, limiting their effectiveness. To address these challenges, we propose Federated In-Context Learning (Fed-ICL), a general framework that enhances ICL through an iterative, collaborative process. Fed-ICL progressively refines responses by leveraging multi-round interactions between clients and a central server, improving answer quality without the need to transmit model parameters. We establish theoretical guarantees for the convergence of Fed-ICL and conduct extensive experiments on standard QA benchmarks, demonstrating that our proposed approach achieves strong performance while maintaining low communication costs.
LaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
Jun 06, 2025Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.