 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Visualization Recommendation with Hier-SUCB
Feb 06, 2025Visualization recommendation aims to enable rapid visual analysis of massive datasets. In real-world scenarios, it is essential to quickly gather and comprehend user preferences to cover users from diverse backgrounds, including varying skill levels and analytical tasks. Previous approaches to personalized visualization recommendations are non-interactive and rely on initial user data for new users. As a result, these models cannot effectively explore options or adapt to real-time feedback. To address this limitation, we propose an interactive personalized visualization recommendation (PVisRec) system that learns on user feedback from previous interactions. For more interactive and accurate recommendations, we propose Hier-SUCB, a contextual combinatorial semi-bandit in the PVisRec setting. Theoretically, we show an improved overall regret bound with the same rank of time but an improved rank of action space. We further demonstrate the effectiveness of Hier-SUCB through extensive experiments where it is comparable to offline methods and outperforms other bandit algorithms in the setting of visualization recommendation.
Hierarchical Conversational Preference Elicitation with Bandit Feedback
Sep 06, 2022


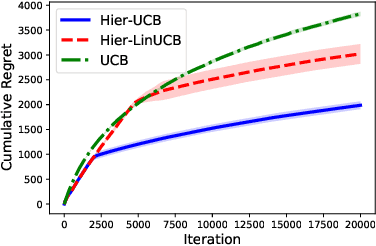
The recent advances of conversational recommendations provide a promising way to efficiently elicit users' preferences via conversational interactions. To achieve this, the recommender system conducts conversations with users, asking their preferences for different items or item categories. Most existing conversational recommender systems for cold-start users utilize a multi-armed bandit framework to learn users' preference in an online manner. However, they rely on a pre-defined conversation frequency for asking about item categories instead of individual items, which may incur excessive conversational interactions that hurt user experience. To enable more flexible questioning about key-terms, we formulate a new conversational bandit problem that allows the recommender system to choose either a key-term or an item to recommend at each round and explicitly models the rewards of these actions. This motivates us to handle a new exploration-exploitation (EE) trade-off between key-term asking and item recommendation, which requires us to accurately model the relationship between key-term and item rewards. We conduct a survey and analyze a real-world dataset to find that, unlike assumptions made in prior works, key-term rewards are mainly affected by rewards of representative items. We propose two bandit algorithms, Hier-UCB and Hier-LinUCB, that leverage this observed relationship and the hierarchical structure between key-terms and items to efficiently learn which items to recommend. We theoretically prove that our algorithm can reduce the regret bound's dependency on the total number of items from previous work. We validate our proposed algorithms and regret bound on both synthetic and real-world data.