 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Failure Attribution in Multi-Agent Systems: A Multi-Perspective Benchmark and Evaluation
Mar 26, 2026Failure attribution is essential for diagnosing and improving multi-agent systems (MAS), yet existing benchmarks and methods largely assume a single deterministic root cause for each failure. In practice, MAS failures often admit multiple plausible attributions due to complex inter-agent dependencies and ambiguous execution trajectories. We revisit MAS failure attribution from a multi-perspective standpoint and propose multi-perspective failure attribution, a practical paradigm that explicitly accounts for attribution ambiguity. To support this setting, we introduce MP-Bench, the first benchmark designed for multi-perspective failure attribution in MAS, along with a new evaluation protocol tailored to this paradigm. Through extensive experiments, we find that prior conclusions suggesting LLMs struggle with failure attribution are largely driven by limitations in existing benchmark designs. Our results highlight the necessity of multi-perspective benchmarks and evaluation protocols for realistic and reliable MAS debugging.
Five Years of SciCap: What We Learned and Future Directions for Scientific Figure Captioning
Dec 25, 2025Between 2021 and 2025, the SciCap project grew from a small seed-funded idea at The Pennsylvania State University (Penn State) into one of the central efforts shaping the scientific figure-captioning landscape. Supported by a Penn State seed grant, Adobe, and the Alfred P. Sloan Foundation, what began as our attempt to test whether domain-specific training, which was successful in text models like SciBERT, could also work for figure captions expanded into a multi-institution collaboration. Over these five years, we curated, released, and continually updated a large collection of figure-caption pairs from arXiv papers, conducted extensive automatic and human evaluations on both generated and author-written captions, navigated the rapid rise of large language models (LLMs), launched annual challenges, and built interactive systems that help scientists write better captions. In this piece, we look back at the first five years of SciCap and summarize the key technical and methodological lessons we learned. We then outline five major unsolved challenges and propose directions for the next phase of research in scientific figure captioning.
SAND: Boosting LLM Agents with Self-Taught Action Deliberation
Jul 10, 2025Large Language Model (LLM) agents are commonly tuned with supervised finetuning on ReAct-style expert trajectories or preference optimization over pairwise rollouts. Most of these methods focus on imitating specific expert behaviors or promoting chosen reasoning thoughts and actions over rejected ones. However, without reasoning and comparing over alternatives actions, LLM agents finetuned with these methods may over-commit towards seemingly plausible but suboptimal actions due to limited action space exploration. To address this, in this paper we propose Self-taught ActioN Deliberation (SAND) framework, enabling LLM agents to explicitly deliberate over candidate actions before committing to one. To tackle the challenges of when and what to deliberate given large action space and step-level action evaluation, we incorporate self-consistency action sampling and execution-guided action critique to help synthesize step-wise action deliberation thoughts using the base model of the LLM agent. In an iterative manner, the deliberation trajectories are then used to finetune the LLM agent itself. Evaluating on two representative interactive agent tasks, SAND achieves an average 20% improvement over initial supervised finetuning and also outperforms state-of-the-art agent tuning approaches.
Improving the performance of optical inverse design of multilayer thin films using CNN-LSTM tandem neural networks
Jun 11, 2025Optical properties of thin film are greatly influenced by the thickness of each layer. Accurately predicting these thicknesses and their corresponding optical properties is important in the optical inverse design of thin films. However, traditional inverse design methods usually demand extensive numerical simulations and optimization procedures, which are time-consuming. In this paper, we utilize deep learning for the inverse design of the transmission spectra of SiO2/TiO2 multilayer thin films. We implement a tandem neural network (TNN), which can solve the one-to-many mapping problem that greatly degrades the performance of deep-learning-based inverse designs. In general, the TNN has been implemented by a back-to-back connection of an inverse neural network and a pre-trained forward neural network, both of which have been implemented based on multilayer perceptron (MLP) algorithms. In this paper, we propose to use not only MLP, but also convolutional neural network (CNN) or long short-term memory (LSTM) algorithms in the configuration of the TNN. We show that an LSTM-LSTM-based TNN yields the highest accuracy but takes the longest training time among nine configurations of TNNs. We also find that a CNN-LSTM-based TNN will be an optimal solution in terms of accuracy and speed because it could integrate the strengths of the CNN and LSTM algorithms.
LaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
Jun 06, 2025Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
Disambiguation in Conversational Question Answering in the Era of LLM: A Survey
May 18, 2025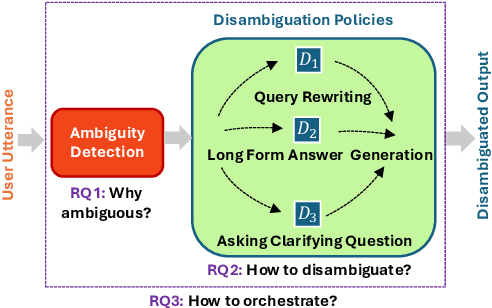
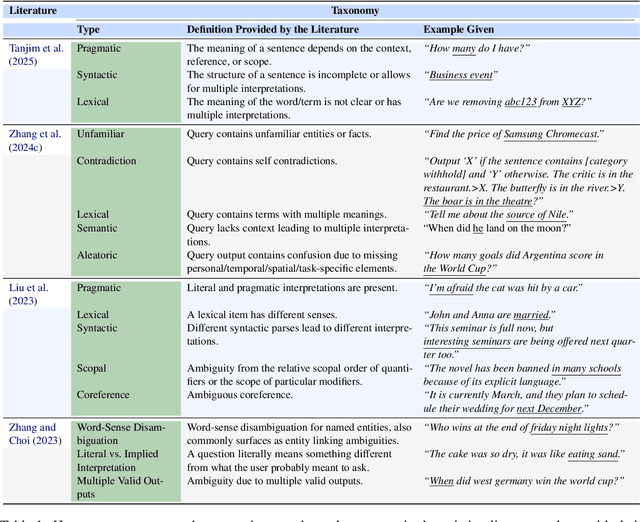
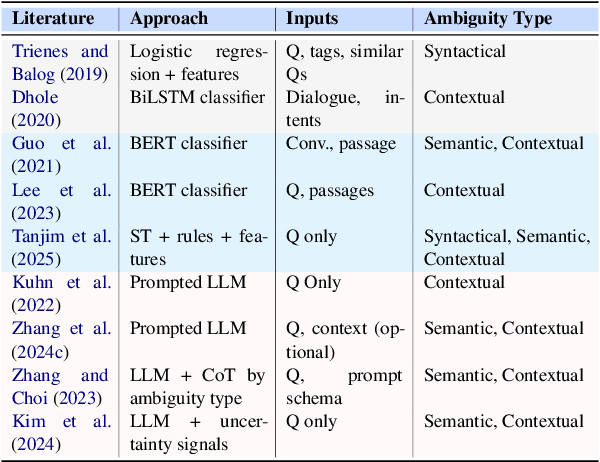
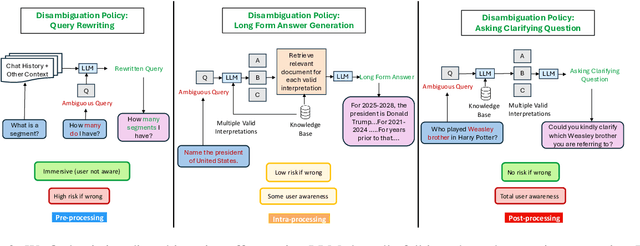
Ambiguity remains a fundamental challenge in Natural Language Processing (NLP) due to the inherent complexity and flexibility of human language. With the advent of Large Language Models (LLMs), addressing ambiguity has become even more critical due to their expanded capabilities and applications. In the context of Conversational Question Answering (CQA), this paper explores the definition, forms, and implications of ambiguity for language driven systems, particularly in the context of LLMs. We define key terms and concepts, categorize various disambiguation approaches enabled by LLMs, and provide a comparative analysis of their advantages and disadvantages. We also explore publicly available datasets for benchmarking ambiguity detection and resolution techniques and highlight their relevance for ongoing research. Finally, we identify open problems and future research directions, proposing areas for further investigation. By offering a comprehensive review of current research on ambiguities and disambiguation with LLMs, we aim to contribute to the development of more robust and reliable language systems.
WaterFlow: Learning Fast & Robust Watermarks using Stable Diffusion
Apr 18, 2025The ability to embed watermarks in images is a fundamental problem of interest for computer vision, and is exacerbated by the rapid rise of generated imagery in recent times. Current state-of-the-art techniques suffer from computational and statistical challenges such as the slow execution speed for practical deployments. In addition, other works trade off fast watermarking speeds but suffer greatly in their robustness or perceptual quality. In this work, we propose WaterFlow (WF), a fast and extremely robust approach for high fidelity visual watermarking based on a learned latent-dependent watermark. Our approach utilizes a pretrained latent diffusion model to encode an arbitrary image into a latent space and produces a learned watermark that is then planted into the Fourier Domain of the latent. The transformation is specified via invertible flow layers that enhance the expressivity of the latent space of the pre-trained model to better preserve image quality while permitting robust and tractable detection. Most notably, WaterFlow demonstrates state-of-the-art performance on general robustness and is the first method capable of effectively defending against difficult combination attacks. We validate our findings on three widely used real and generated datasets: MS-COCO, DiffusionDB, and WikiArt.
Training Robust Graph Neural Networks by Modeling Noise Dependencies
Feb 27, 2025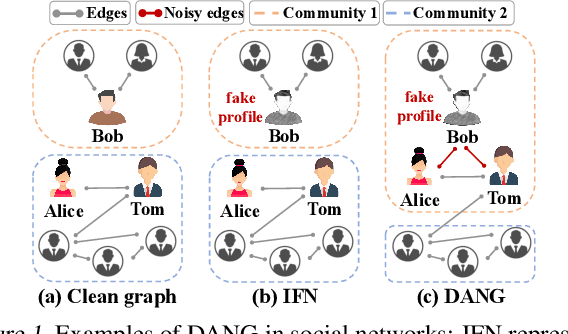
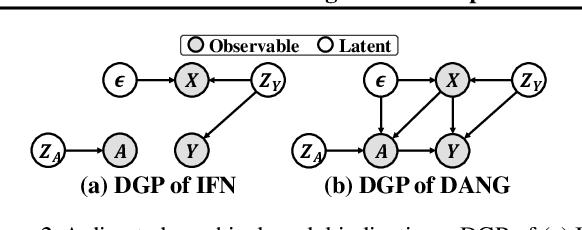
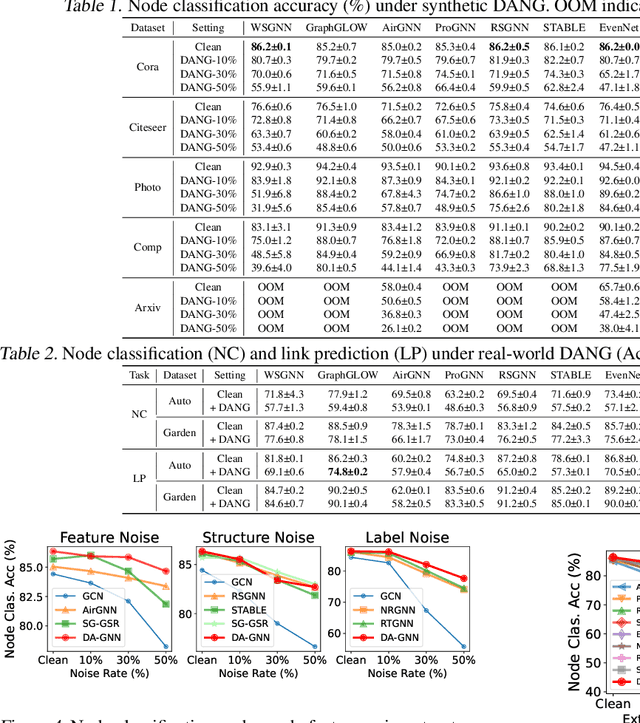
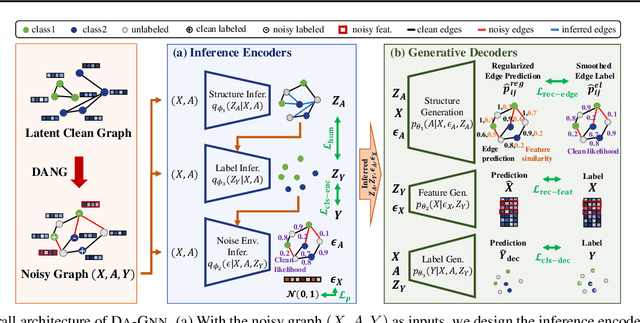
In real-world applications, node features in graphs often contain noise from various sources, leading to significant performance degradation in GNNs. Although several methods have been developed to enhance robustness, they rely on the unrealistic assumption that noise in node features is independent of the graph structure and node labels, thereby limiting their applicability. To this end, we introduce a more realistic noise scenario, dependency-aware noise on graphs (DANG), where noise in node features create a chain of noise dependencies that propagates to the graph structure and node labels. We propose a novel robust GNN, DA-GNN, which captures the causal relationships among variables in the data generating process (DGP) of DANG using variational inference. In addition, we present new benchmark datasets that simulate DANG in real-world applications, enabling more practical research on robust GNNs. Extensive experiments demonstrate that DA-GNN consistently outperforms existing baselines across various noise scenarios, including both DANG and conventional noise models commonly considered in this field.
Exploring Rewriting Approaches for Different Conversational Tasks
Feb 26, 2025



Conversational assistants often require a question rewriting algorithm that leverages a subset of past interactions to provide a more meaningful (accurate) answer to the user's question or request. However, the exact rewriting approach may often depend on the use case and application-specific tasks supported by the conversational assistant, among other constraints. In this paper, we systematically investigate two different approaches, denoted as rewriting and fusion, on two fundamentally different generation tasks, including a text-to-text generation task and a multimodal generative task that takes as input text and generates a visualization or data table that answers the user's question. Our results indicate that the specific rewriting or fusion approach highly depends on the underlying use case and generative task. In particular, we find that for a conversational question-answering assistant, the query rewriting approach performs best, whereas for a data analysis assistant that generates visualizations and data tables based on the user's conversation with the assistant, the fusion approach works best. Notably, we explore two datasets for the data analysis assistant use case, for short and long conversations, and we find that query fusion always performs better, whereas for the conversational text-based question-answering, the query rewrite approach performs best.
From Documents to Dialogue: Building KG-RAG Enhanced AI Assistants
Feb 21, 2025The Adobe Experience Platform AI Assistant is a conversational tool that enables organizations to interact seamlessly with proprietary enterprise data through a chatbot. However, due to access restrictions, Large Language Models (LLMs) cannot retrieve these internal documents, limiting their ability to generate accurate zero-shot responses. To overcome this limitation, we use a Retrieval-Augmented Generation (RAG) framework powered by a Knowledge Graph (KG) to retrieve relevant information from external knowledge sources, enabling LLMs to answer questions over private or previously unseen document collections. In this paper, we propose a novel approach for building a high-quality, low-noise KG. We apply several techniques, including incremental entity resolution using seed concepts, similarity-based filtering to deduplicate entries, assigning confidence scores to entity-relation pairs to filter for high-confidence pairs, and linking facts to source documents for provenance. Our KG-RAG system retrieves relevant tuples, which are added to the user prompts context before being sent to the LLM generating the response. Our evaluation demonstrates that this approach significantly enhances response relevance, reducing irrelevant answers by over 50% and increasing fully relevant answers by 88% compared to the existing production system.