 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalize-then-Store: Benchmarking and Learning Personalized Memory for Long-horizon Agents
May 25, 2026Existing large language model (LLM) based memory systems apply universal, static policies that overlook a fundamental reality: the contexts that are worth storing in memory are different across users. This misalignment wastes limited memory budget on transient interactions while failing to preserve critical context for long horizon tasks. To address this gap, we investigate an underexplored question: can LLM based memory systems learn personalized memory policies? We introduce PerMemBench, the first benchmark for evaluating personalized memory systems, featuring multi year, multi domain interaction histories across diverse user personas. We further present the first empirical study of memory personalization, proposing session level storage gating, a lightweight framework that selectively bypasses memory operations for transient sessions. Our study confirms that personalization yields substantial retention gains under perfect gating, yet reveals that accurate gating remains an open and critical challenge.
Reasoning Structure Matters for Safety Alignment of Reasoning Models
Apr 21, 2026Large reasoning models (LRMs) achieve strong performance on complex reasoning tasks but often generate harmful responses to malicious user queries. This paper investigates the underlying cause of these safety risks and shows that the issue lies in the reasoning structure itself. Based on this insight, we claim that effective safety alignment can be achieved by altering the reasoning structure. We propose AltTrain, a simple yet effective post training method that explicitly alters the reasoning structure of LRMs. AltTrain is both practical and generalizable, requiring no complex reinforcement learning (RL) training or reward design, only supervised finetuning (SFT) with a lightweight 1K training examples. Experiments across LRM backbones and model sizes demonstrate strong safety alignment, along with robust generalization across reasoning, QA, summarization, and multilingual setting.
Why and When Visual Token Pruning Fails? A Study on Relevant Visual Information Shift in MLLMs Decoding
Apr 14, 2026Recently, visual token pruning has been studied to handle the vast number of visual tokens in Multimodal Large Language Models. However, we observe that while existing pruning methods perform reliably on simple visual understanding, they struggle to effectively generalize to complex visual reasoning tasks, a critical gap underexplored in previous studies. Through a systematic analysis, we identify Relevant Visual Information Shift (RVIS) during decoding as the primary failure driver. To address this, we propose Decoding-stage Shift-aware Token Pruning (DSTP), a training-free add-on framework that enables existing pruning methods to align visual tokens with shifting reasoning requirements during the decoding stage. Extensive experiments demonstrate that DSTP significantly mitigates performance degradation of pruning methods in complex reasoning tasks, while consistently yielding performance gains even across visual understanding benchmarks. Furthermore, DSTP demonstrates effectiveness across diverse state-of-the-art architectures, highlighting its generalizability and efficiency with minimal computational overhead.
Rethinking Failure Attribution in Multi-Agent Systems: A Multi-Perspective Benchmark and Evaluation
Mar 26, 2026Failure attribution is essential for diagnosing and improving multi-agent systems (MAS), yet existing benchmarks and methods largely assume a single deterministic root cause for each failure. In practice, MAS failures often admit multiple plausible attributions due to complex inter-agent dependencies and ambiguous execution trajectories. We revisit MAS failure attribution from a multi-perspective standpoint and propose multi-perspective failure attribution, a practical paradigm that explicitly accounts for attribution ambiguity. To support this setting, we introduce MP-Bench, the first benchmark designed for multi-perspective failure attribution in MAS, along with a new evaluation protocol tailored to this paradigm. Through extensive experiments, we find that prior conclusions suggesting LLMs struggle with failure attribution are largely driven by limitations in existing benchmark designs. Our results highlight the necessity of multi-perspective benchmarks and evaluation protocols for realistic and reliable MAS debugging.
Self-EvolveRec: Self-Evolving Recommender Systems with LLM-based Directional Feedback
Feb 13, 2026Traditional methods for automating recommender system design, such as Neural Architecture Search (NAS), are often constrained by a fixed search space defined by human priors, limiting innovation to pre-defined operators. While recent LLM-driven code evolution frameworks shift fixed search space target to open-ended program spaces, they primarily rely on scalar metrics (e.g., NDCG, Hit Ratio) that fail to provide qualitative insights into model failures or directional guidance for improvement. To address this, we propose Self-EvolveRec, a novel framework that establishes a directional feedback loop by integrating a User Simulator for qualitative critiques and a Model Diagnosis Tool for quantitative internal verification. Furthermore, we introduce a Diagnosis Tool - Model Co-Evolution strategy to ensure that evaluation criteria dynamically adapt as the recommendation architecture evolves. Extensive experiments demonstrate that Self-EvolveRec significantly outperforms state-of-the-art NAS and LLM-driven code evolution baselines in both recommendation performance and user satisfaction. Our code is available at https://github.com/Sein-Kim/self_evolverec.
R1-ACT: Efficient Reasoning Model Safety Alignment by Activating Safety Knowledge
Aug 01, 2025Although large reasoning models (LRMs) have demonstrated impressive capabilities on complex tasks, recent studies reveal that these models frequently fulfill harmful user instructions, raising significant safety concerns. In this paper, we investigate the underlying cause of LRM safety risks and find that models already possess sufficient safety knowledge but fail to activate it during reasoning. Based on this insight, we propose R1-Act, a simple and efficient post-training method that explicitly triggers safety knowledge through a structured reasoning process. R1-Act achieves strong safety improvements while preserving reasoning performance, outperforming prior alignment methods. Notably, it requires only 1,000 training examples and 90 minutes of training on a single RTX A6000 GPU. Extensive experiments across multiple LRM backbones and sizes demonstrate the robustness, scalability, and practical efficiency of our approach.
Dynamic Time-aware Continual User Representation Learning
Apr 23, 2025
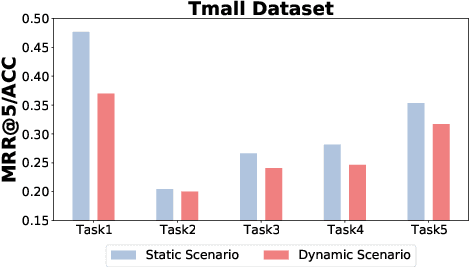
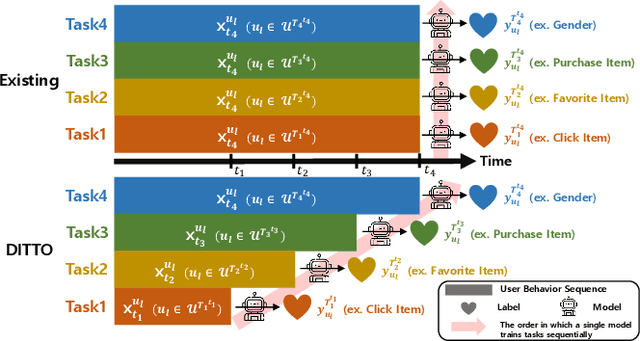
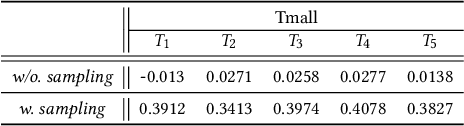
Traditional user modeling (UM) approaches have primarily focused on designing models for a single specific task, but they face limitations in generalization and adaptability across various tasks. Recognizing these challenges, recent studies have shifted towards continual learning (CL)-based universal user representation learning aiming to develop a single model capable of handling multiple tasks. Despite advancements, existing methods are in fact evaluated under an unrealistic scenario that does not consider the passage of time as tasks progress, which overlooks newly emerged items that may change the item distribution of previous tasks. In this paper, we introduce a practical evaluation scenario on which CL-based universal user representation learning approaches should be evaluated, which takes into account the passage of time as tasks progress. Then, we propose a novel framework Dynamic Time-aware continual user representation learner, named DITTO, designed to alleviate catastrophic forgetting despite continuous shifts in item distribution, while also allowing the knowledge acquired from previous tasks to adapt to the current shifted item distribution. Through our extensive experiments, we demonstrate the superiority of DITTO over state-of-the-art methods under a practical evaluation scenario. Our source code is available at https://github.com/seungyoon-Choi/DITTO_official.
Is Safety Standard Same for Everyone? User-Specific Safety Evaluation of Large Language Models
Feb 20, 2025As the use of large language model (LLM) agents continues to grow, their safety vulnerabilities have become increasingly evident. Extensive benchmarks evaluate various aspects of LLM safety by defining the safety relying heavily on general standards, overlooking user-specific standards. However, safety standards for LLM may vary based on a user-specific profiles rather than being universally consistent across all users. This raises a critical research question: Do LLM agents act safely when considering user-specific safety standards? Despite its importance for safe LLM use, no benchmark datasets currently exist to evaluate the user-specific safety of LLMs. To address this gap, we introduce U-SAFEBENCH, the first benchmark designed to assess user-specific aspect of LLM safety. Our evaluation of 18 widely used LLMs reveals current LLMs fail to act safely when considering user-specific safety standards, marking a new discovery in this field. To address this vulnerability, we propose a simple remedy based on chain-of-thought, demonstrating its effectiveness in improving user-specific safety. Our benchmark and code are available at https://github.com/yeonjun-in/U-SafeBench.
DSLR: Diversity Enhancement and Structure Learning for Rehearsal-based Graph Continual Learning
Feb 23, 2024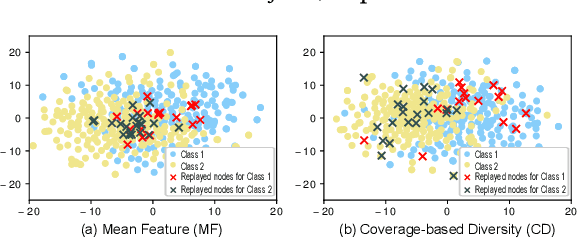
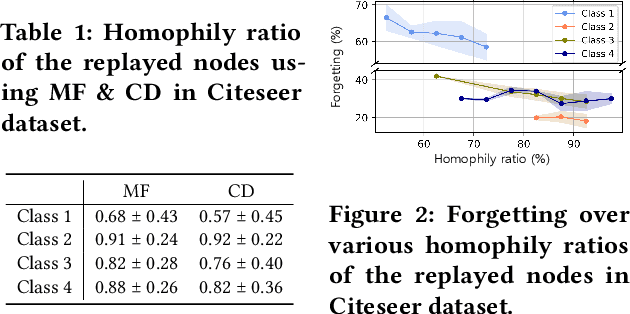

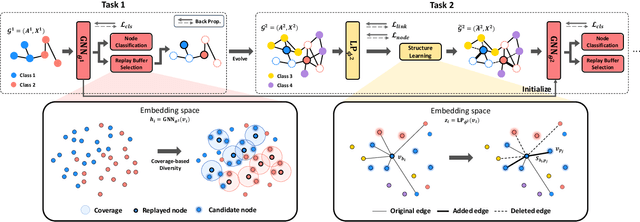
We investigate the replay buffer in rehearsal-based approaches for graph continual learning (GCL) methods. Existing rehearsal-based GCL methods select the most representative nodes for each class and store them in a replay buffer for later use in training subsequent tasks. However, we discovered that considering only the class representativeness of each replayed node makes the replayed nodes to be concentrated around the center of each class, incurring a potential risk of overfitting to nodes residing in those regions, which aggravates catastrophic forgetting. Moreover, as the rehearsal-based approach heavily relies on a few replayed nodes to retain knowledge obtained from previous tasks, involving the replayed nodes that have irrelevant neighbors in the model training may have a significant detrimental impact on model performance. In this paper, we propose a GCL model named DSLR, specifically, we devise a coverage-based diversity (CD) approach to consider both the class representativeness and the diversity within each class of the replayed nodes. Moreover, we adopt graph structure learning (GSL) to ensure that the replayed nodes are connected to truly informative neighbors. Extensive experimental results demonstrate the effectiveness and efficiency of DSLR. Our source code is available at https://github.com/seungyoon-Choi/DSLR_official.
Task-Equivariant Graph Few-shot Learning
Jun 01, 2023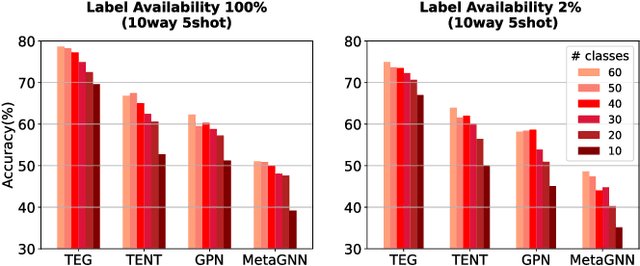
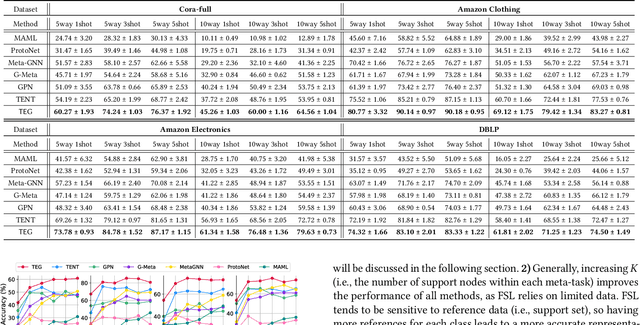
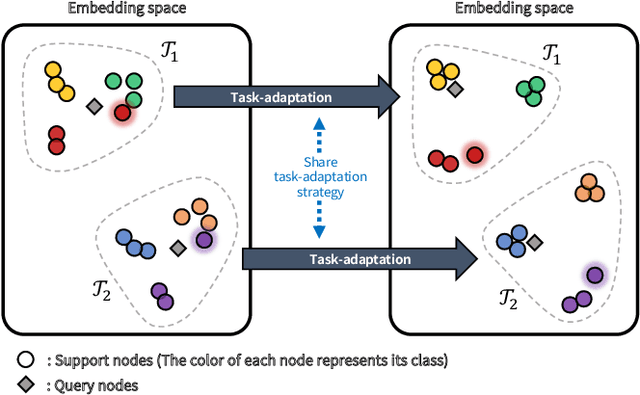
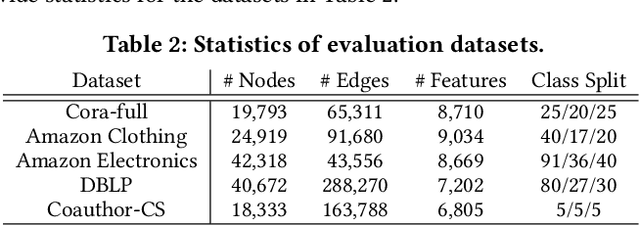
Although Graph Neural Networks (GNNs) have been successful in node classification tasks, their performance heavily relies on the availability of a sufficient number of labeled nodes per class. In real-world situations, not all classes have many labeled nodes and there may be instances where the model needs to classify new classes, making manual labeling difficult. To solve this problem, it is important for GNNs to be able to classify nodes with a limited number of labeled nodes, known as few-shot node classification. Previous episodic meta-learning based methods have demonstrated success in few-shot node classification, but our findings suggest that optimal performance can only be achieved with a substantial amount of diverse training meta-tasks. To address this challenge of meta-learning based few-shot learning (FSL), we propose a new approach, the Task-Equivariant Graph few-shot learning (TEG) framework. Our TEG framework enables the model to learn transferable task-adaptation strategies using a limited number of training meta-tasks, allowing it to acquire meta-knowledge for a wide range of meta-tasks. By incorporating equivariant neural networks, TEG can utilize their strong generalization abilities to learn highly adaptable task-specific strategies. As a result, TEG achieves state-of-the-art performance with limited training meta-tasks. Our experiments on various benchmark datasets demonstrate TEG's superiority in terms of accuracy and generalization ability, even when using minimal meta-training data, highlighting the effectiveness of our proposed approach in addressing the challenges of meta-learning based few-shot node classification. Our code is available at the following link: https://github.com/sung-won-kim/TEG