 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD-FKD: Cross-Domain Feature Knowledge Distillation for Robust Single-Domain Generalization in Object Detection
Mar 17, 2026Single-domain generalization is essential for object detection, particularly when training models on a single source domain and evaluating them on unseen target domains. Domain shifts, such as changes in weather, lighting, or scene conditions, pose significant challenges to the generalization ability of existing models. To address this, we propose Cross-Domain Feature Knowledge Distillation (CD-FKD), which enhances the generalization capability of the student network by leveraging both global and instance-wise feature distillation. The proposed method uses diversified data through downscaling and corruption to train the student network, whereas the teacher network receives the original source domain data. The student network mimics the features of the teacher through both global and instance-wise distillation, enabling it to extract object-centric features effectively, even for objects that are difficult to detect owing to corruption. Extensive experiments on challenging scenes demonstrate that CD-FKD outperforms state-of-the-art methods in both target domain generalization and source domain performance, validating its effectiveness in improving object detection robustness to domain shifts. This approach is valuable in real-world applications, like autonomous driving and surveillance, where robust object detection in diverse environments is crucial.
LSR-Net: A Lightweight and Strong Robustness Network for Bearing Fault Diagnosis in Noise Environment
Jan 14, 2026Rotating bearings play an important role in modern industries, but have a high probability of occurrence of defects because they operate at high speed, high load, and poor operating environments. Therefore, if a delay time occurs when a bearing is diagnosed with a defect, this may cause economic loss and loss of life. Moreover, since the vibration sensor from which the signal is collected is highly affected by the operating environment and surrounding noise, accurate defect diagnosis in a noisy environment is also important. In this paper, we propose a lightweight and strong robustness network (LSR-Net) that is accurate in a noisy environment and enables real-time fault diagnosis. To this end, first, a denoising and feature enhancement module (DFEM) was designed to create a 3-channel 2D matrix by giving several nonlinearity to the feature-map that passed through the denoising module (DM) block composed of convolution-based denoising (CD) blocks. Moreover, adaptive pruning was applied to DM to improve denoising ability when the power of noise is strong. Second, for lightweight model design, a convolution-based efficiency shuffle (CES) block was designed using group convolution (GConv), group pointwise convolution (GPConv) and channel split that can design the model while maintaining low parameters. In addition, the trade-off between the accuracy and model computational complexity that can occur due to the lightweight design of the model was supplemented using attention mechanisms and channel shuffle. In order to verify the defect diagnosis performance of the proposed model, performance verification was conducted in a noisy environment using a vibration signal. As a result, it was confirmed that the proposed model had the best anti-noise ability compared to the benchmark models, and the computational complexity of the model was also the lowest.
Towards LLM-Centric Multimodal Fusion: A Survey on Integration Strategies and Techniques
Jun 05, 2025The rapid progress of Multimodal Large Language Models(MLLMs) has transformed the AI landscape. These models combine pre-trained LLMs with various modality encoders. This integration requires a systematic understanding of how different modalities connect to the language backbone. Our survey presents an LLM-centric analysis of current approaches. We examine methods for transforming and aligning diverse modal inputs into the language embedding space. This addresses a significant gap in existing literature. We propose a classification framework for MLLMs based on three key dimensions. First, we examine architectural strategies for modality integration. This includes both the specific integration mechanisms and the fusion level. Second, we categorize representation learning techniques as either joint or coordinate representations. Third, we analyze training paradigms, including training strategies and objective functions. By examining 125 MLLMs developed between 2021 and 2025, we identify emerging patterns in the field. Our taxonomy provides researchers with a structured overview of current integration techniques. These insights aim to guide the development of more robust multimodal integration strategies for future models built on pre-trained foundations.
Subgraph Federated Learning for Local Generalization
Mar 06, 2025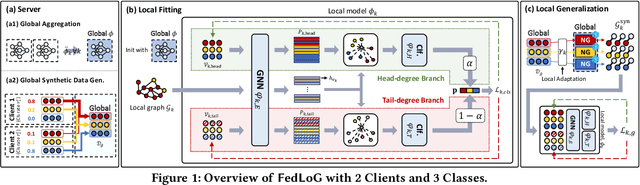
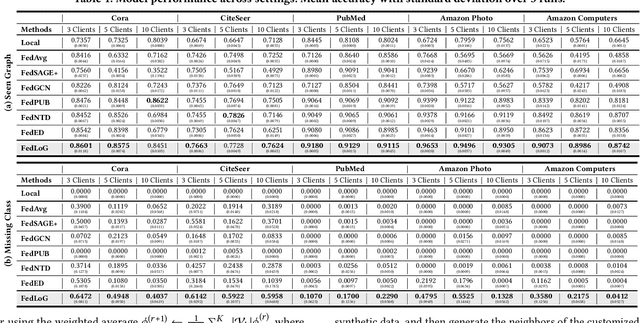
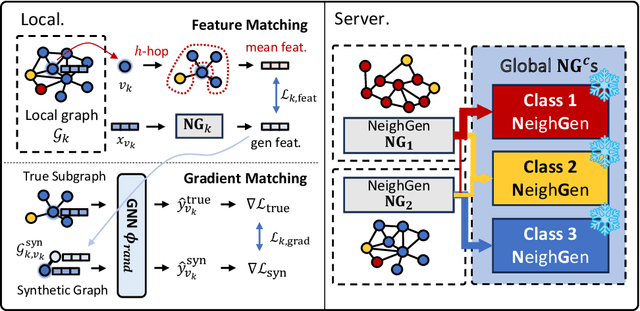
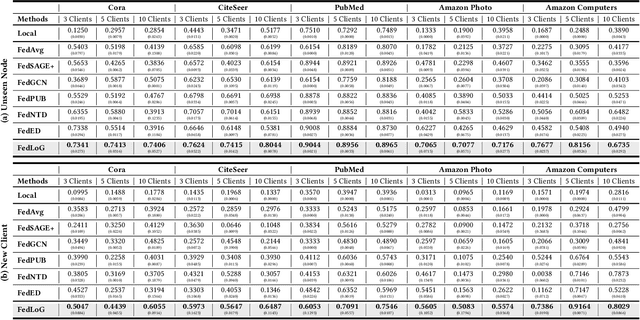
Federated Learning (FL) on graphs enables collaborative model training to enhance performance without compromising the privacy of each client. However, existing methods often overlook the mutable nature of graph data, which frequently introduces new nodes and leads to shifts in label distribution. Since they focus solely on performing well on each client's local data, they are prone to overfitting to their local distributions (i.e., local overfitting), which hinders their ability to generalize to unseen data with diverse label distributions. In contrast, our proposed method, FedLoG, effectively tackles this issue by mitigating local overfitting. Our model generates global synthetic data by condensing the reliable information from each class representation and its structural information across clients. Using these synthetic data as a training set, we alleviate the local overfitting problem by adaptively generalizing the absent knowledge within each local dataset. This enhances the generalization capabilities of local models, enabling them to handle unseen data effectively. Our model outperforms baselines in our proposed experimental settings, which are designed to measure generalization power to unseen data in practical scenarios. Our code is available at https://github.com/sung-won-kim/FedLoG
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
SoccerNet 2024 Challenges Results
Sep 16, 2024

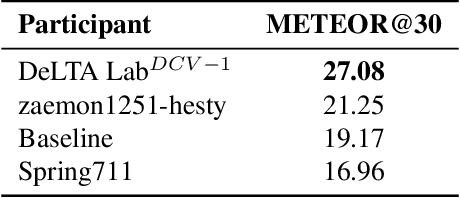
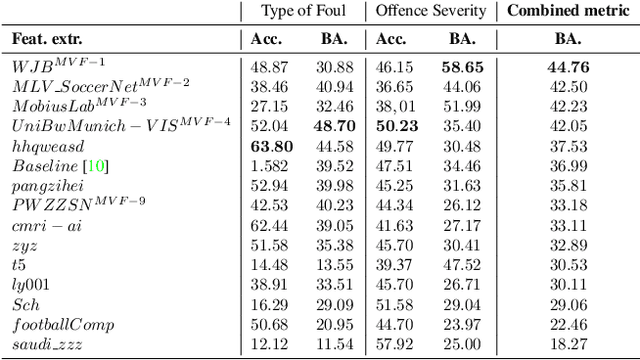
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
MART: MultiscAle Relational Transformer Networks for Multi-agent Trajectory Prediction
Jul 31, 2024Multi-agent trajectory prediction is crucial to autonomous driving and understanding the surrounding environment. Learning-based approaches for multi-agent trajectory prediction, such as primarily relying on graph neural networks, graph transformers, and hypergraph neural networks, have demonstrated outstanding performance on real-world datasets in recent years. However, the hypergraph transformer-based method for trajectory prediction is yet to be explored. Therefore, we present a MultiscAle Relational Transformer (MART) network for multi-agent trajectory prediction. MART is a hypergraph transformer architecture to consider individual and group behaviors in transformer machinery. The core module of MART is the encoder, which comprises a Pair-wise Relational Transformer (PRT) and a Hyper Relational Transformer (HRT). The encoder extends the capabilities of a relational transformer by introducing HRT, which integrates hyperedge features into the transformer mechanism, promoting attention weights to focus on group-wise relations. In addition, we propose an Adaptive Group Estimator (AGE) designed to infer complex group relations in real-world environments. Extensive experiments on three real-world datasets (NBA, SDD, and ETH-UCY) demonstrate that our method achieves state-of-the-art performance, enhancing ADE/FDE by 3.9%/11.8% on the NBA dataset. Code is available at https://github.com/gist-ailab/MART.
M2Former: Multi-Scale Patch Selection for Fine-Grained Visual Recognition
Aug 04, 2023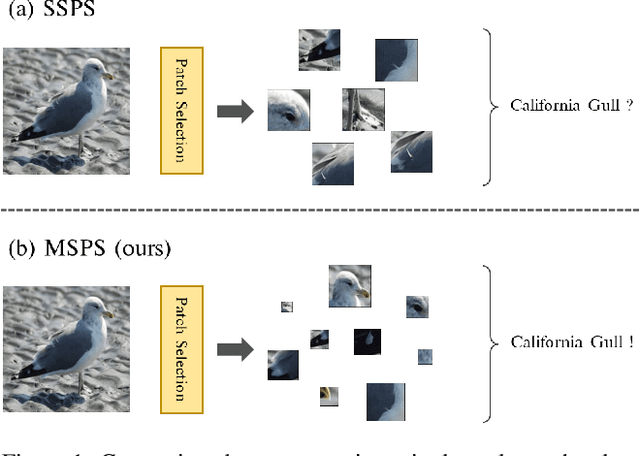
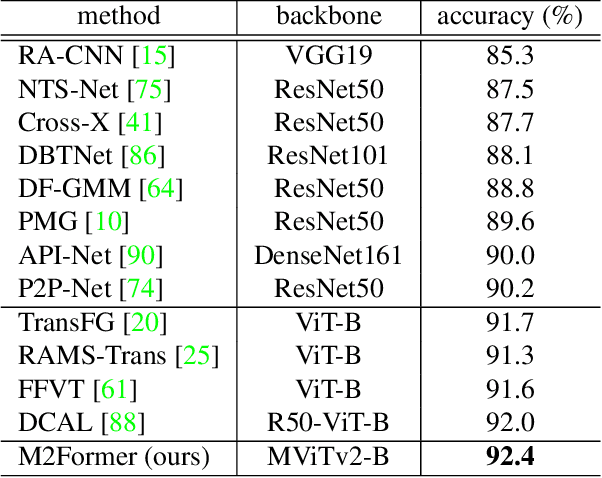
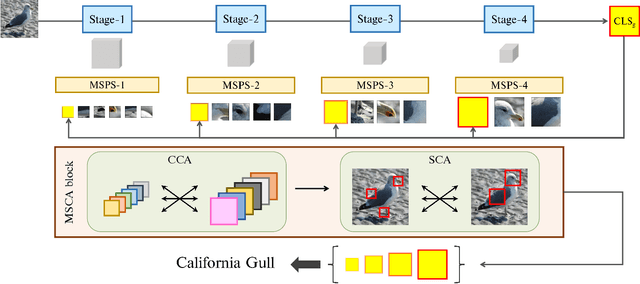
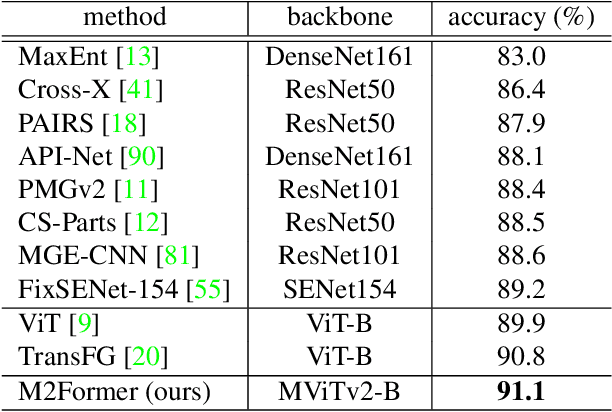
Recently, vision Transformers (ViTs) have been actively applied to fine-grained visual recognition (FGVR). ViT can effectively model the interdependencies between patch-divided object regions through an inherent self-attention mechanism. In addition, patch selection is used with ViT to remove redundant patch information and highlight the most discriminative object patches. However, existing ViT-based FGVR models are limited to single-scale processing, and their fixed receptive fields hinder representational richness and exacerbate vulnerability to scale variability. Therefore, we propose multi-scale patch selection (MSPS) to improve the multi-scale capabilities of existing ViT-based models. Specifically, MSPS selects salient patches of different scales at different stages of a multi-scale vision Transformer (MS-ViT). In addition, we introduce class token transfer (CTT) and multi-scale cross-attention (MSCA) to model cross-scale interactions between selected multi-scale patches and fully reflect them in model decisions. Compared to previous single-scale patch selection (SSPS), our proposed MSPS encourages richer object representations based on feature hierarchy and consistently improves performance from small-sized to large-sized objects. As a result, we propose M2Former, which outperforms CNN-/ViT-based models on several widely used FGVR benchmarks.
Task-Equivariant Graph Few-shot Learning
Jun 01, 2023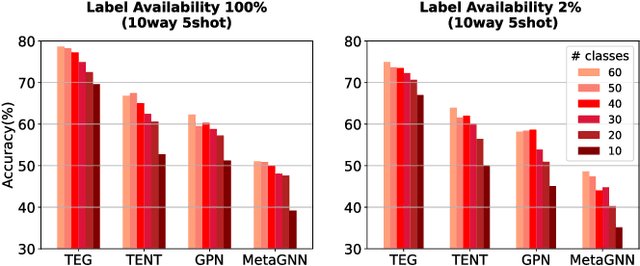
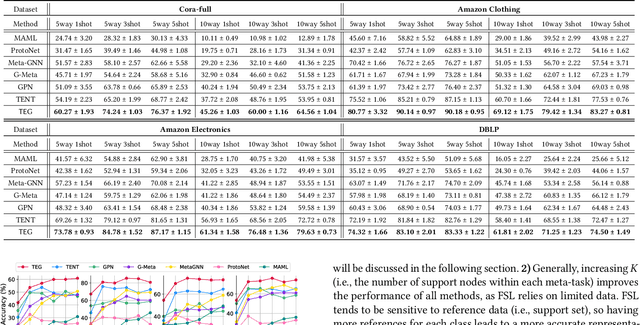
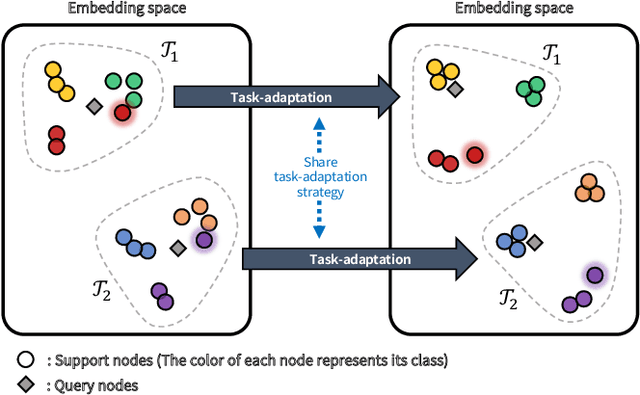
Although Graph Neural Networks (GNNs) have been successful in node classification tasks, their performance heavily relies on the availability of a sufficient number of labeled nodes per class. In real-world situations, not all classes have many labeled nodes and there may be instances where the model needs to classify new classes, making manual labeling difficult. To solve this problem, it is important for GNNs to be able to classify nodes with a limited number of labeled nodes, known as few-shot node classification. Previous episodic meta-learning based methods have demonstrated success in few-shot node classification, but our findings suggest that optimal performance can only be achieved with a substantial amount of diverse training meta-tasks. To address this challenge of meta-learning based few-shot learning (FSL), we propose a new approach, the Task-Equivariant Graph few-shot learning (TEG) framework. Our TEG framework enables the model to learn transferable task-adaptation strategies using a limited number of training meta-tasks, allowing it to acquire meta-knowledge for a wide range of meta-tasks. By incorporating equivariant neural networks, TEG can utilize their strong generalization abilities to learn highly adaptable task-specific strategies. As a result, TEG achieves state-of-the-art performance with limited training meta-tasks. Our experiments on various benchmark datasets demonstrate TEG's superiority in terms of accuracy and generalization ability, even when using minimal meta-training data, highlighting the effectiveness of our proposed approach in addressing the challenges of meta-learning based few-shot node classification. Our code is available at the following link: https://github.com/sung-won-kim/TEG
Conditional Graph Information Bottleneck for Molecular Relational Learning
Apr 29, 2023



Molecular relational learning, whose goal is to learn the interaction behavior between molecular pairs, got a surge of interest in molecular sciences due to its wide range of applications. Recently, graph neural networks have recently shown great success in molecular relational learning by modeling a molecule as a graph structure, and considering atom-level interactions between two molecules. Despite their success, existing molecular relational learning methods tend to overlook the nature of chemistry, i.e., a chemical compound is composed of multiple substructures such as functional groups that cause distinctive chemical reactions. In this work, we propose a novel relational learning framework, called CGIB, that predicts the interaction behavior between a pair of graphs by detecting core subgraphs therein. The main idea is, given a pair of graphs, to find a subgraph from a graph that contains the minimal sufficient information regarding the task at hand conditioned on the paired graph based on the principle of conditional graph information bottleneck. We argue that our proposed method mimics the nature of chemical reactions, i.e., the core substructure of a molecule varies depending on which other molecule it interacts with. Extensive experiments on various tasks with real-world datasets demonstrate the superiority of CGIB over state-of-the-art baselines. Our code is available at https://github.com/Namkyeong/CGIB.