 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Fine-tuning of Vision Foundation Model for Medical Image Classification Under Label Noise
Nov 29, 2024Deep neural networks have demonstrated remarkable performance in various vision tasks, but their success heavily depends on the quality of the training data. Noisy labels are a critical issue in medical datasets and can significantly degrade model performance. Previous clean sample selection methods have not utilized the well pre-trained features of vision foundation models (VFMs) and assumed that training begins from scratch. In this paper, we propose CUFIT, a curriculum fine-tuning paradigm of VFMs for medical image classification under label noise. Our method is motivated by the fact that linear probing of VFMs is relatively unaffected by noisy samples, as it does not update the feature extractor of the VFM, thus robustly classifying the training samples. Subsequently, curriculum fine-tuning of two adapters is conducted, starting with clean sample selection from the linear probing phase. Our experimental results demonstrate that CUFIT outperforms previous methods across various medical image benchmarks. Specifically, our method surpasses previous baselines by 5.0%, 2.1%, 4.6%, and 5.8% at a 40% noise rate on the HAM10000, APTOS-2019, BloodMnist, and OrgancMnist datasets, respectively. Furthermore, we provide extensive analyses to demonstrate the impact of our method on noisy label detection. For instance, our method shows higher label precision and recall compared to previous approaches. Our work highlights the potential of leveraging VFMs in medical image classification under challenging conditions of noisy labels.
MART: MultiscAle Relational Transformer Networks for Multi-agent Trajectory Prediction
Jul 31, 2024Multi-agent trajectory prediction is crucial to autonomous driving and understanding the surrounding environment. Learning-based approaches for multi-agent trajectory prediction, such as primarily relying on graph neural networks, graph transformers, and hypergraph neural networks, have demonstrated outstanding performance on real-world datasets in recent years. However, the hypergraph transformer-based method for trajectory prediction is yet to be explored. Therefore, we present a MultiscAle Relational Transformer (MART) network for multi-agent trajectory prediction. MART is a hypergraph transformer architecture to consider individual and group behaviors in transformer machinery. The core module of MART is the encoder, which comprises a Pair-wise Relational Transformer (PRT) and a Hyper Relational Transformer (HRT). The encoder extends the capabilities of a relational transformer by introducing HRT, which integrates hyperedge features into the transformer mechanism, promoting attention weights to focus on group-wise relations. In addition, we propose an Adaptive Group Estimator (AGE) designed to infer complex group relations in real-world environments. Extensive experiments on three real-world datasets (NBA, SDD, and ETH-UCY) demonstrate that our method achieves state-of-the-art performance, enhancing ADE/FDE by 3.9%/11.8% on the NBA dataset. Code is available at https://github.com/gist-ailab/MART.
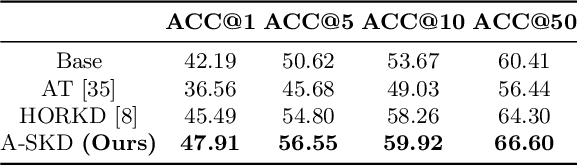
Domain-Specific Block Selection and Paired-View Pseudo-Labeling for Online Test-Time Adaptation
Apr 17, 2024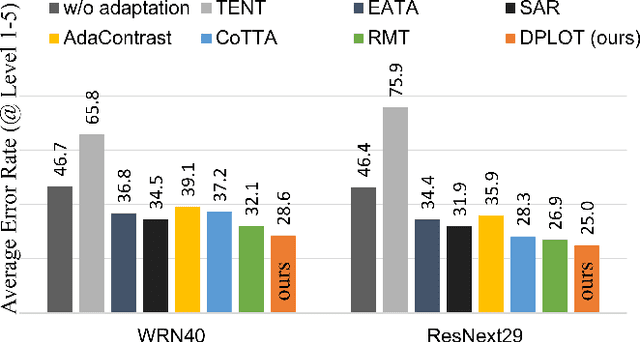
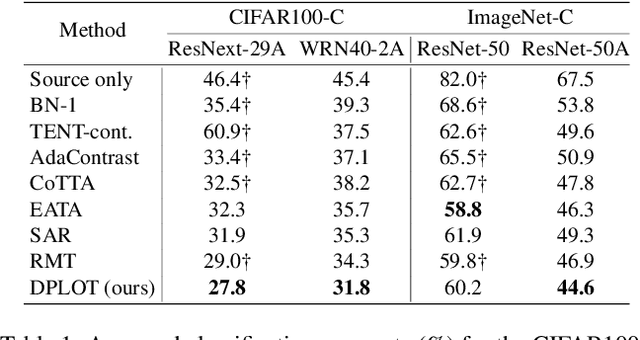
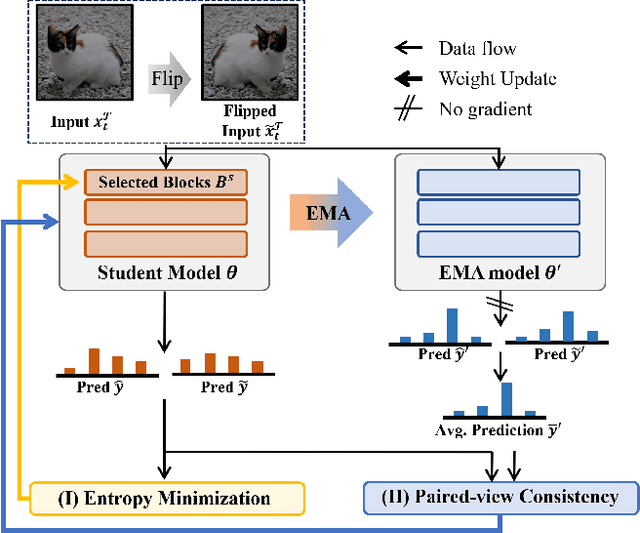
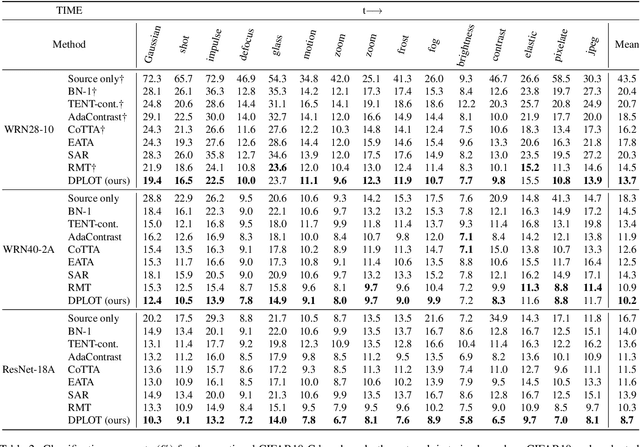
Test-time adaptation (TTA) aims to adapt a pre-trained model to a new test domain without access to source data after deployment. Existing approaches typically rely on self-training with pseudo-labels since ground-truth cannot be obtained from test data. Although the quality of pseudo labels is important for stable and accurate long-term adaptation, it has not been previously addressed. In this work, we propose DPLOT, a simple yet effective TTA framework that consists of two components: (1) domain-specific block selection and (2) pseudo-label generation using paired-view images. Specifically, we select blocks that involve domain-specific feature extraction and train these blocks by entropy minimization. After blocks are adjusted for current test domain, we generate pseudo-labels by averaging given test images and corresponding flipped counterparts. By simply using flip augmentation, we prevent a decrease in the quality of the pseudo-labels, which can be caused by the domain gap resulting from strong augmentation. Our experimental results demonstrate that DPLOT outperforms previous TTA methods in CIFAR10-C, CIFAR100-C, and ImageNet-C benchmarks, reducing error by up to 5.4%, 9.1%, and 2.9%, respectively. Also, we provide an extensive analysis to demonstrate effectiveness of our framework. Code is available at https://github.com/gist-ailab/domain-specific-block-selection-and-paired-view-pseudo-labeling-for-online-TTA.
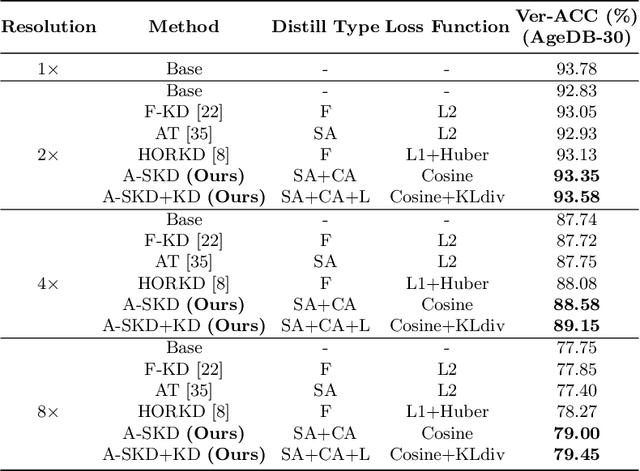
Enhancing Low-resolution Face Recognition with Feature Similarity Knowledge Distillation
Mar 08, 2023



In this study, we introduce a feature knowledge distillation framework to improve low-resolution (LR) face recognition performance using knowledge obtained from high-resolution (HR) images. The proposed framework transfers informative features from an HR-trained network to an LR-trained network by reducing the distance between them. A cosine similarity measure was employed as a distance metric to effectively align the HR and LR features. This approach differs from conventional knowledge distillation frameworks, which use the L_p distance metrics and offer the advantage of converging well when reducing the distance between features of different resolutions. Our framework achieved a 3% improvement over the previous state-of-the-art method on the AgeDB-30 benchmark without bells and whistles, while maintaining a strong performance on HR images. The effectiveness of cosine similarity as a distance metric was validated through statistical analysis, making our approach a promising solution for real-world applications in which LR images are frequently encountered. The code and pretrained models will be publicly available on GitHub.
Block Selection Method for Using Feature Norm in Out-of-distribution Detection
Dec 10, 2022



Detecting out-of-distribution (OOD) inputs during the inference stage is crucial for deploying neural networks in the real world. Previous methods commonly relied on the output of a network derived from the highly activated feature map. In this study, we first revealed that a norm of the feature map obtained from the other block than the last block can be a better indicator of OOD detection. Motivated by this, we propose a simple framework consisting of FeatureNorm: a norm of the feature map and NormRatio: a ratio of FeatureNorm for ID and OOD to measure the OOD detection performance of each block. In particular, to select the block that provides the largest difference between FeatureNorm of ID and FeatureNorm of OOD, we create Jigsaw puzzle images as pseudo OOD from ID training samples and calculate NormRatio, and the block with the largest value is selected. After the suitable block is selected, OOD detection with the FeatureNorm outperforms other OOD detection methods by reducing FPR95 by up to 52.77% on CIFAR10 benchmark and by up to 48.53% on ImageNet benchmark. We demonstrate that our framework can generalize to various architectures and the importance of block selection, which can improve previous OOD detection methods as well.
Teaching Where to Look: Attention Similarity Knowledge Distillation for Low Resolution Face Recognition
Sep 29, 2022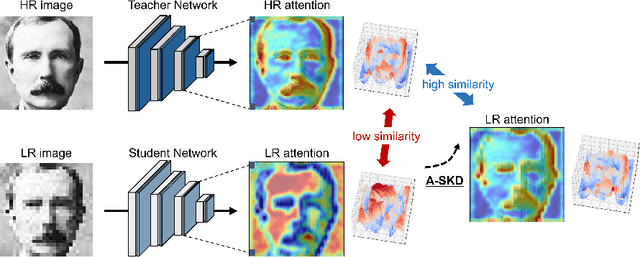

Deep learning has achieved outstanding performance for face recognition benchmarks, but performance reduces significantly for low resolution (LR) images. We propose an attention similarity knowledge distillation approach, which transfers attention maps obtained from a high resolution (HR) network as a teacher into an LR network as a student to boost LR recognition performance. Inspired by humans being able to approximate an object's region from an LR image based on prior knowledge obtained from HR images, we designed the knowledge distillation loss using the cosine similarity to make the student network's attention resemble the teacher network's attention. Experiments on various LR face related benchmarks confirmed the proposed method generally improved recognition performances on LR settings, outperforming state-of-the-art results by simply transferring well-constructed attention maps. The code and pretrained models are publicly available in the https://github.com/gist-ailab/teaching-where-to-look.
SleePyCo: Automatic Sleep Scoring with Feature Pyramid and Contrastive Learning
Sep 20, 2022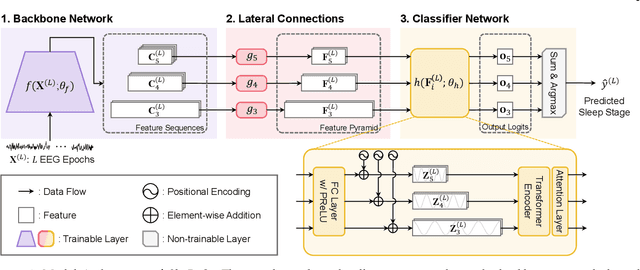
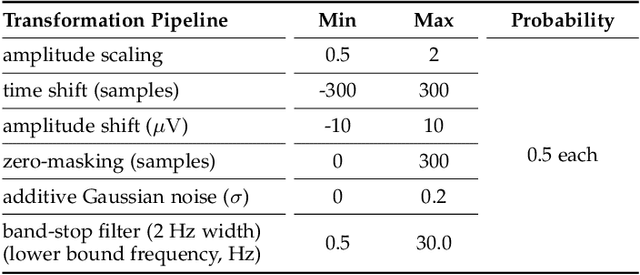
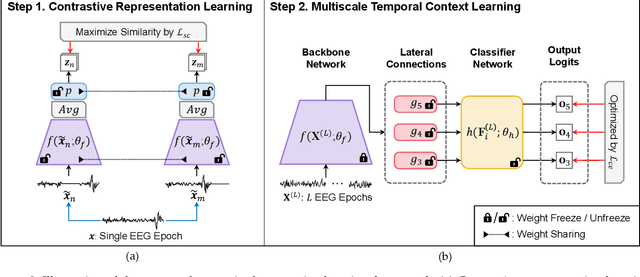
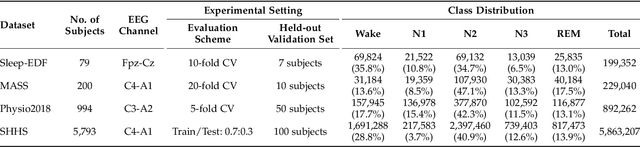
Automatic sleep scoring is essential for the diagnosis and treatment of sleep disorders and enables longitudinal sleep tracking in home environments. Conventionally, learning-based automatic sleep scoring on single-channel electroencephalogram (EEG) is actively studied because obtaining multi-channel signals during sleep is difficult. However, learning representation from raw EEG signals is challenging owing to the following issues: 1) sleep-related EEG patterns occur on different temporal and frequency scales and 2) sleep stages share similar EEG patterns. To address these issues, we propose a deep learning framework named SleePyCo that incorporates 1) a feature pyramid and 2) supervised contrastive learning for automatic sleep scoring. For the feature pyramid, we propose a backbone network named SleePyCo-backbone to consider multiple feature sequences on different temporal and frequency scales. Supervised contrastive learning allows the network to extract class discriminative features by minimizing the distance between intra-class features and simultaneously maximizing that between inter-class features. Comparative analyses on four public datasets demonstrate that SleePyCo consistently outperforms existing frameworks based on single-channel EEG. Extensive ablation experiments show that SleePyCo exhibits enhanced overall performance, with significant improvements in discrimination between the N1 and rapid eye movement (REM) stages.
Multiple Classification with Split Learning
Sep 11, 2020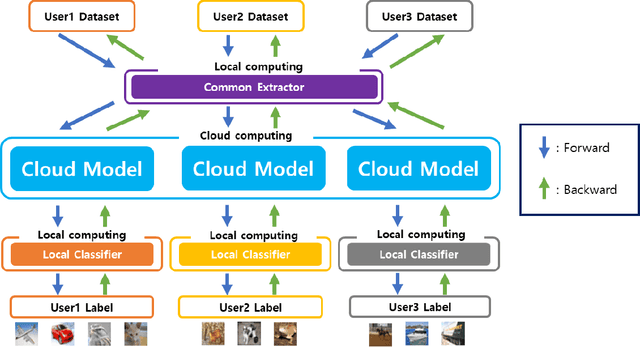
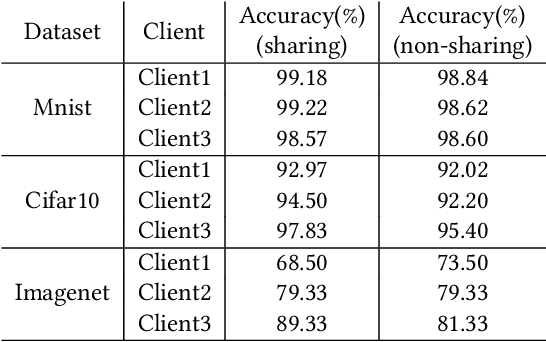
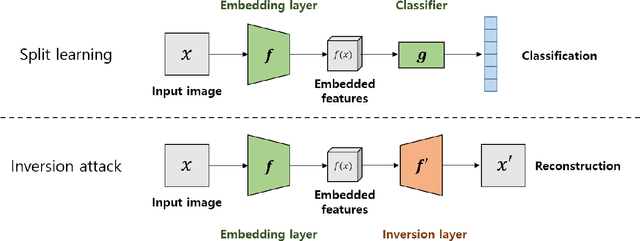
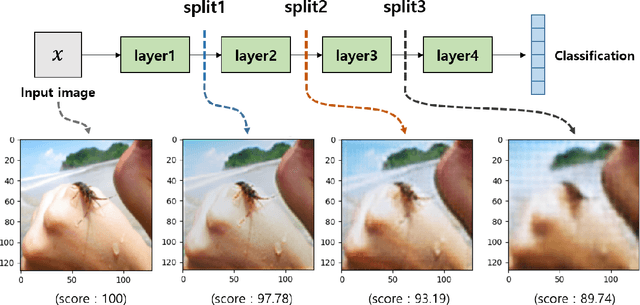
Privacy issues were raised in the process of training deep learning in medical, mobility, and other fields. To solve this problem, we present privacy-preserving distributed deep learning method that allow clients to learn a variety of data without direct exposure. We divided a single deep learning architecture into a common extractor, a cloud model and a local classifier for the distributed learning. First, the common extractor, which is used by local clients, extracts secure features from the input data. The secure features also take the role that the cloud model can employ various task and diverse types of data. The feature contain the most important information that helps to proceed various task. Second, the cloud model including most parts of the whole training model gets the embedded features from the massive local clients, and performs most of deep learning operations which takes severe computing cost. After the operations in cloud model finished, outputs of the cloud model send back to local clients. Finally, the local classifier determined classification results and delivers the results to local clients. When clients train models, our model does not directly expose sensitive information to exterior network. During the test, the average performance improvement was 2.63% over the existing local training model. However, in a distributed environment, there is a possibility of inversion attack due to exposed features. For this reason, we experimented with the common extractor to prevent data restoration. The quality of restoration of the original image was tested by adjusting the depth of the common extractor. As a result, we found that the deeper the common extractor, the restoration score decreased to 89.74.