 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspClutter6D: A Large-scale Real-world Dataset for Robust Perception and Grasping in Cluttered Scenes
Apr 09, 2025
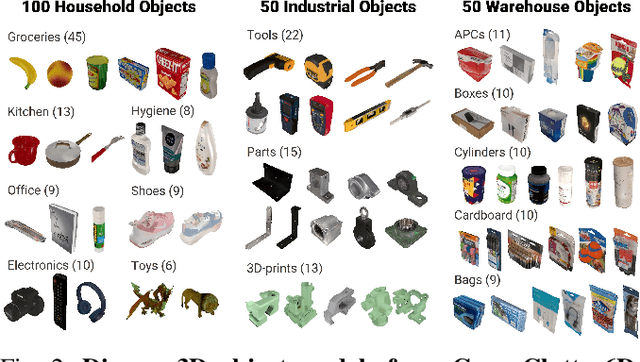
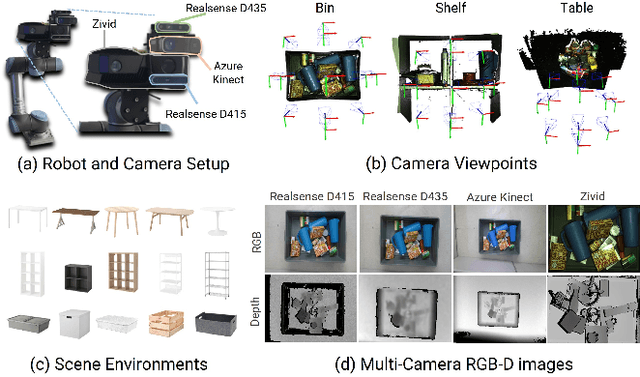
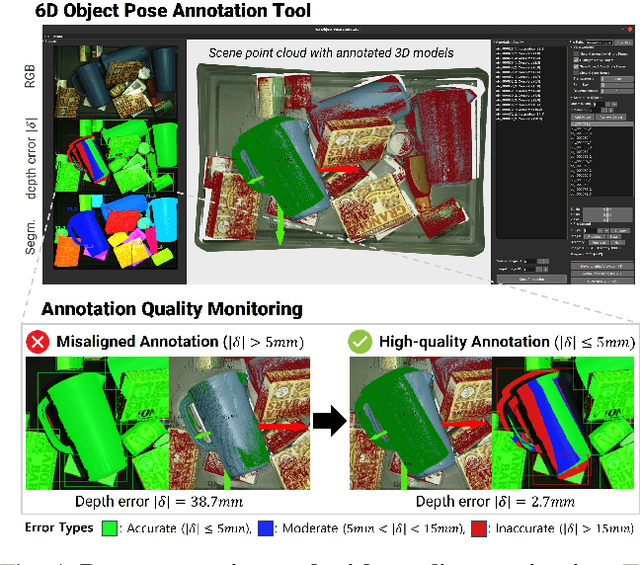
Robust grasping in cluttered environments remains an open challenge in robotics. While benchmark datasets have significantly advanced deep learning methods, they mainly focus on simplistic scenes with light occlusion and insufficient diversity, limiting their applicability to practical scenarios. We present GraspClutter6D, a large-scale real-world grasping dataset featuring: (1) 1,000 highly cluttered scenes with dense arrangements (14.1 objects/scene, 62.6\% occlusion), (2) comprehensive coverage across 200 objects in 75 environment configurations (bins, shelves, and tables) captured using four RGB-D cameras from multiple viewpoints, and (3) rich annotations including 736K 6D object poses and 9.3B feasible robotic grasps for 52K RGB-D images. We benchmark state-of-the-art segmentation, object pose estimation, and grasping detection methods to provide key insights into challenges in cluttered environments. Additionally, we validate the dataset's effectiveness as a training resource, demonstrating that grasping networks trained on GraspClutter6D significantly outperform those trained on existing datasets in both simulation and real-world experiments. The dataset, toolkit, and annotation tools are publicly available on our project website: https://sites.google.com/view/graspclutter6d.
Curriculum Fine-tuning of Vision Foundation Model for Medical Image Classification Under Label Noise
Nov 29, 2024Deep neural networks have demonstrated remarkable performance in various vision tasks, but their success heavily depends on the quality of the training data. Noisy labels are a critical issue in medical datasets and can significantly degrade model performance. Previous clean sample selection methods have not utilized the well pre-trained features of vision foundation models (VFMs) and assumed that training begins from scratch. In this paper, we propose CUFIT, a curriculum fine-tuning paradigm of VFMs for medical image classification under label noise. Our method is motivated by the fact that linear probing of VFMs is relatively unaffected by noisy samples, as it does not update the feature extractor of the VFM, thus robustly classifying the training samples. Subsequently, curriculum fine-tuning of two adapters is conducted, starting with clean sample selection from the linear probing phase. Our experimental results demonstrate that CUFIT outperforms previous methods across various medical image benchmarks. Specifically, our method surpasses previous baselines by 5.0%, 2.1%, 4.6%, and 5.8% at a 40% noise rate on the HAM10000, APTOS-2019, BloodMnist, and OrgancMnist datasets, respectively. Furthermore, we provide extensive analyses to demonstrate the impact of our method on noisy label detection. For instance, our method shows higher label precision and recall compared to previous approaches. Our work highlights the potential of leveraging VFMs in medical image classification under challenging conditions of noisy labels.
SentiCSE: A Sentiment-aware Contrastive Sentence Embedding Framework with Sentiment-guided Textual Similarity
Apr 01, 2024Recently, sentiment-aware pre-trained language models (PLMs) demonstrate impressive results in downstream sentiment analysis tasks. However, they neglect to evaluate the quality of their constructed sentiment representations; they just focus on improving the fine-tuning performance, which overshadows the representation quality. We argue that without guaranteeing the representation quality, their downstream performance can be highly dependent on the supervision of the fine-tuning data rather than representation quality. This problem would make them difficult to foray into other sentiment-related domains, especially where labeled data is scarce. We first propose Sentiment-guided Textual Similarity (SgTS), a novel metric for evaluating the quality of sentiment representations, which is designed based on the degree of equivalence in sentiment polarity between two sentences. We then propose SentiCSE, a novel Sentiment-aware Contrastive Sentence Embedding framework for constructing sentiment representations via combined word-level and sentence-level objectives, whose quality is guaranteed by SgTS. Qualitative and quantitative comparison with the previous sentiment-aware PLMs shows the superiority of our work. Our code is available at: https://github.com/nayohan/SentiCSE
* 14 pages, 8 figures
Leveraging Human-Machine Interactions for Computer Vision Dataset Quality Enhancement
Jan 31, 2024Large-scale datasets for single-label multi-class classification, such as \emph{ImageNet-1k}, have been instrumental in advancing deep learning and computer vision. However, a critical and often understudied aspect is the comprehensive quality assessment of these datasets, especially regarding potential multi-label annotation errors. In this paper, we introduce a lightweight, user-friendly, and scalable framework that synergizes human and machine intelligence for efficient dataset validation and quality enhancement. We term this novel framework \emph{Multilabelfy}. Central to Multilabelfy is an adaptable web-based platform that systematically guides annotators through the re-evaluation process, effectively leveraging human-machine interactions to enhance dataset quality. By using Multilabelfy on the ImageNetV2 dataset, we found that approximately $47.88\%$ of the images contained at least two labels, underscoring the need for more rigorous assessments of such influential datasets. Furthermore, our analysis showed a negative correlation between the number of potential labels per image and model top-1 accuracy, illuminating a crucial factor in model evaluation and selection. Our open-source framework, Multilabelfy, offers a convenient, lightweight solution for dataset enhancement, emphasizing multi-label proportions. This study tackles major challenges in dataset integrity and provides key insights into model performance evaluation. Moreover, it underscores the advantages of integrating human expertise with machine capabilities to produce more robust models and trustworthy data development. The source code for Multilabelfy will be available at https://github.com/esla/Multilabelfy. \keywords{Computer Vision \and Dataset Quality Enhancement \and Dataset Validation \and Human-Computer Interaction \and Multi-label Annotation.}
PolyFit: A Peg-in-hole Assembly Framework for Unseen Polygon Shapes via Sim-to-real Adaptation
Dec 05, 2023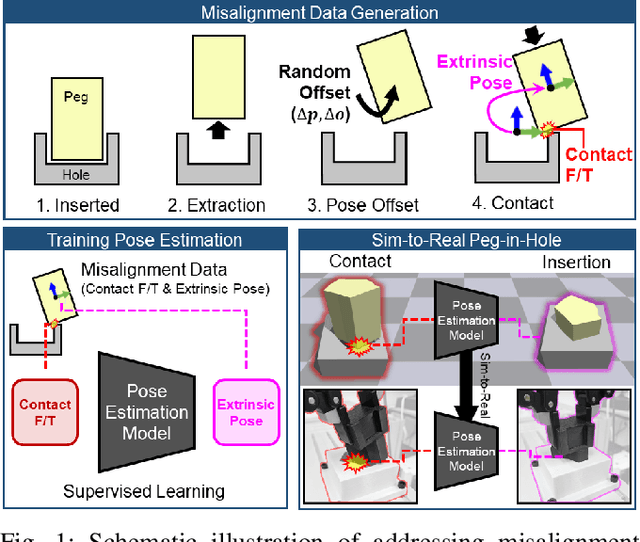
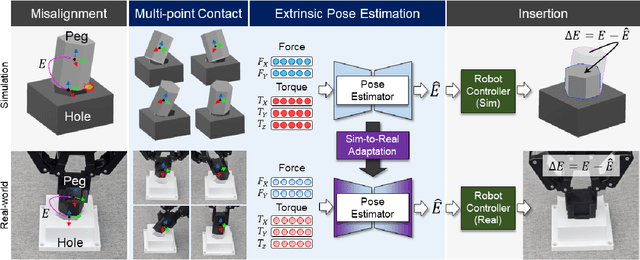
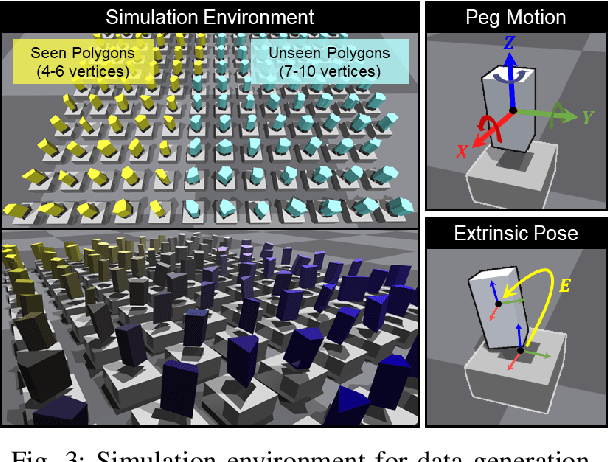
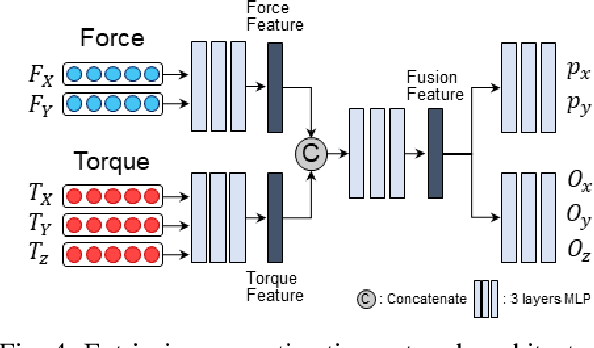
The study addresses the foundational and challenging task of peg-in-hole assembly in robotics, where misalignments caused by sensor inaccuracies and mechanical errors often result in insertion failures or jamming. This research introduces PolyFit, representing a paradigm shift by transitioning from a reinforcement learning approach to a supervised learning methodology. PolyFit is a Force/Torque (F/T)-based supervised learning framework designed for 5-DoF peg-in-hole assembly. It utilizes F/T data for accurate extrinsic pose estimation and adjusts the peg pose to rectify misalignments. Extensive training in a simulated environment involves a dataset encompassing a diverse range of peg-hole shapes, extrinsic poses, and their corresponding contact F/T readings. To enhance extrinsic pose estimation, a multi-point contact strategy is integrated into the model input, recognizing that identical F/T readings can indicate different poses. The study proposes a sim-to-real adaptation method for real-world application, using a sim-real paired dataset to enable effective generalization to complex and unseen polygon shapes. PolyFit achieves impressive peg-in-hole success rates of 97.3% and 96.3% for seen and unseen shapes in simulations, respectively. Real-world evaluations further demonstrate substantial success rates of 86.7% and 85.0%, highlighting the robustness and adaptability of the proposed method.
INSTA-BEEER: Explicit Error Estimation and Refinement for Fast and Accurate Unseen Object Instance Segmentation
Jun 28, 2023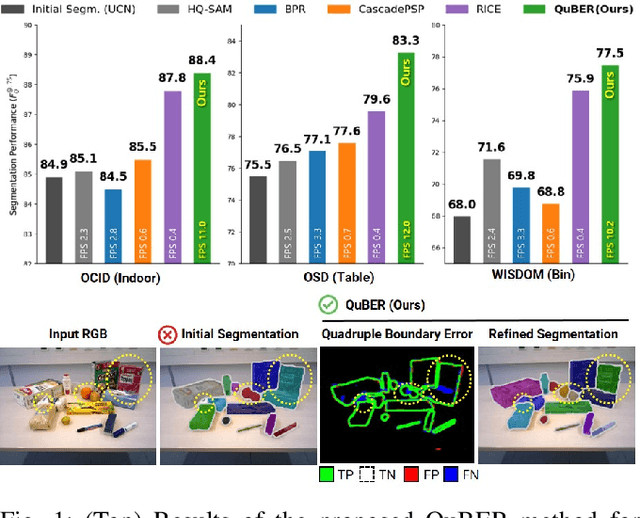

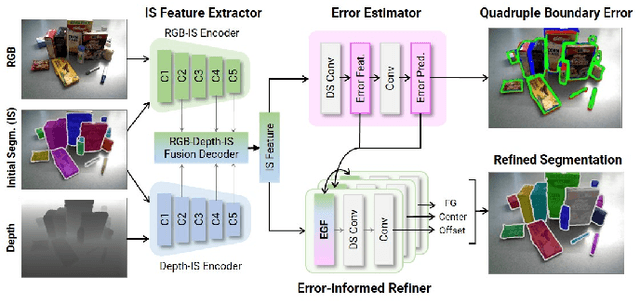

Efficient and accurate segmentation of unseen objects is crucial for robotic manipulation. However, it remains challenging due to over- or under-segmentation. Although existing refinement methods can enhance the segmentation quality, they fix only minor boundary errors or are not sufficiently fast. In this work, we propose INSTAnce Boundary Explicit Error Estimation and Refinement (INSTA-BEEER), a novel refinement model that allows for adding and deleting instances and sharpening boundaries. Leveraging an error-estimation-then-refinement scheme, the model first estimates the pixel-wise boundary explicit errors: true positive, true negative, false positive, and false negative pixels of the instance boundary in the initial segmentation. It then refines the initial segmentation using these error estimates as guidance. Experiments show that the proposed model significantly enhances segmentation, achieving state-of-the-art performance. Furthermore, with a fast runtime (less than 0.1 s), the model consistently improves performance across various initial segmentation methods, making it highly suitable for practical robotic applications.