 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspClutter6D: A Large-scale Real-world Dataset for Robust Perception and Grasping in Cluttered Scenes
Apr 09, 2025
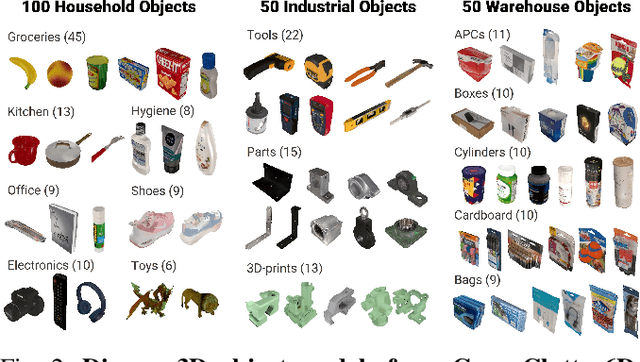
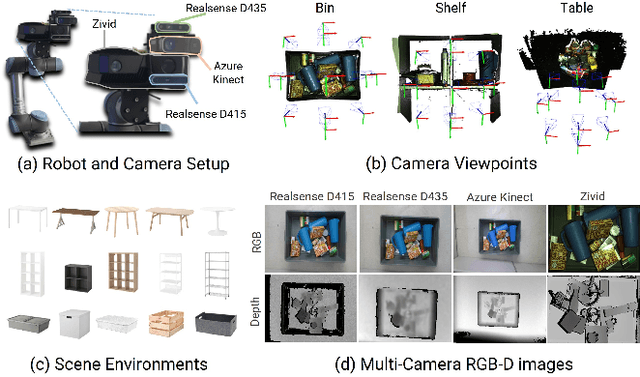
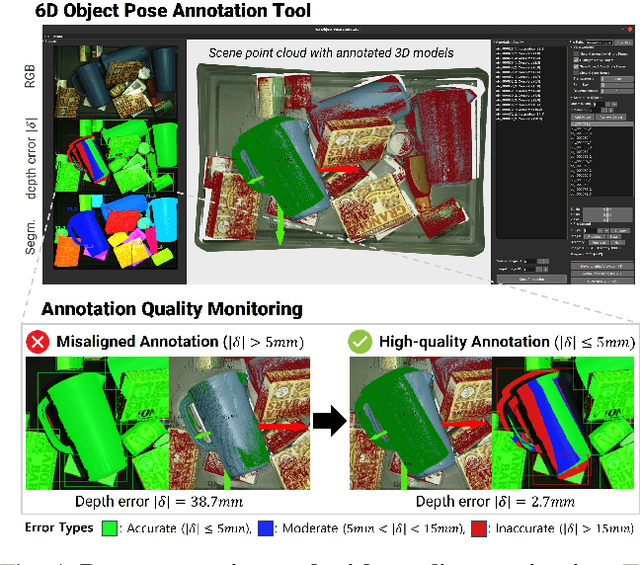
Robust grasping in cluttered environments remains an open challenge in robotics. While benchmark datasets have significantly advanced deep learning methods, they mainly focus on simplistic scenes with light occlusion and insufficient diversity, limiting their applicability to practical scenarios. We present GraspClutter6D, a large-scale real-world grasping dataset featuring: (1) 1,000 highly cluttered scenes with dense arrangements (14.1 objects/scene, 62.6\% occlusion), (2) comprehensive coverage across 200 objects in 75 environment configurations (bins, shelves, and tables) captured using four RGB-D cameras from multiple viewpoints, and (3) rich annotations including 736K 6D object poses and 9.3B feasible robotic grasps for 52K RGB-D images. We benchmark state-of-the-art segmentation, object pose estimation, and grasping detection methods to provide key insights into challenges in cluttered environments. Additionally, we validate the dataset's effectiveness as a training resource, demonstrating that grasping networks trained on GraspClutter6D significantly outperform those trained on existing datasets in both simulation and real-world experiments. The dataset, toolkit, and annotation tools are publicly available on our project website: https://sites.google.com/view/graspclutter6d.
Domain-Specific Block Selection and Paired-View Pseudo-Labeling for Online Test-Time Adaptation
Apr 17, 2024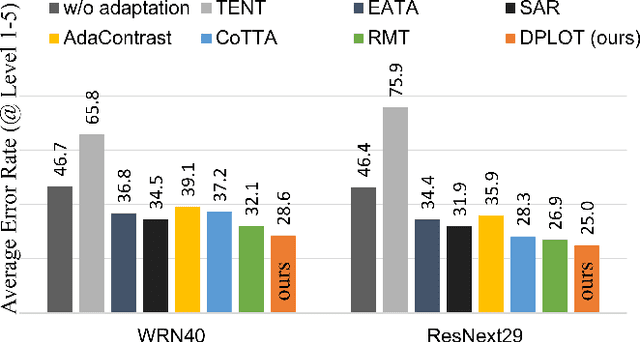
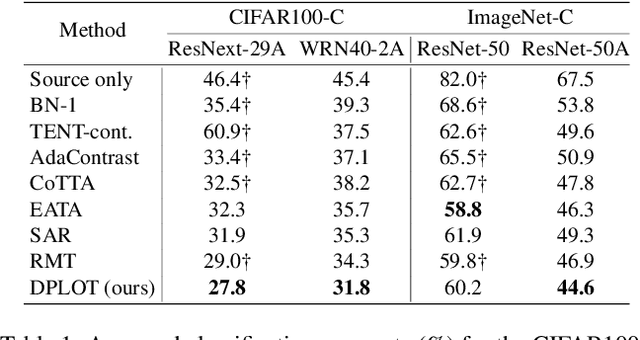
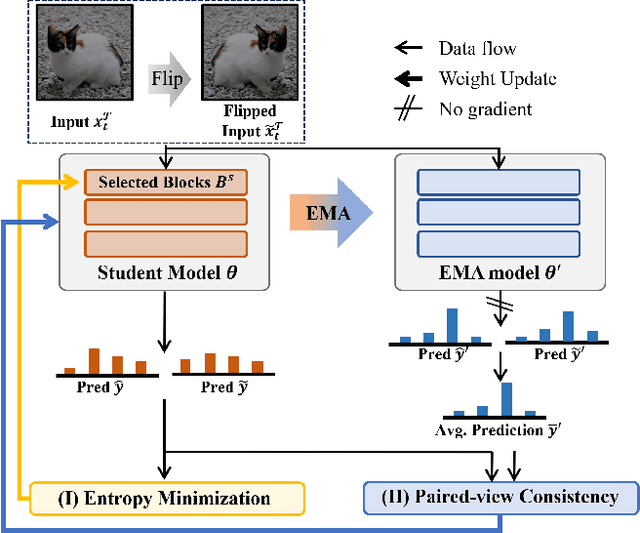
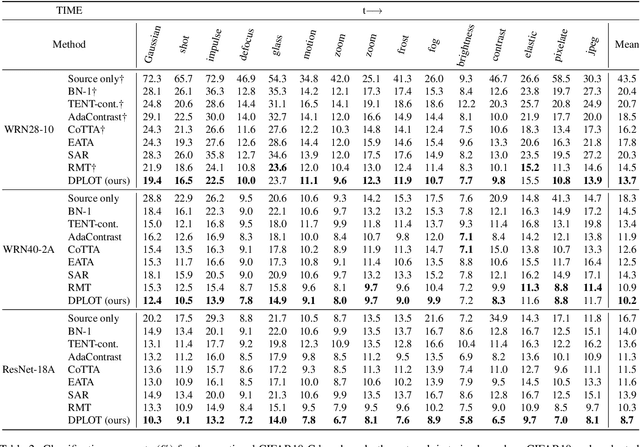
Test-time adaptation (TTA) aims to adapt a pre-trained model to a new test domain without access to source data after deployment. Existing approaches typically rely on self-training with pseudo-labels since ground-truth cannot be obtained from test data. Although the quality of pseudo labels is important for stable and accurate long-term adaptation, it has not been previously addressed. In this work, we propose DPLOT, a simple yet effective TTA framework that consists of two components: (1) domain-specific block selection and (2) pseudo-label generation using paired-view images. Specifically, we select blocks that involve domain-specific feature extraction and train these blocks by entropy minimization. After blocks are adjusted for current test domain, we generate pseudo-labels by averaging given test images and corresponding flipped counterparts. By simply using flip augmentation, we prevent a decrease in the quality of the pseudo-labels, which can be caused by the domain gap resulting from strong augmentation. Our experimental results demonstrate that DPLOT outperforms previous TTA methods in CIFAR10-C, CIFAR100-C, and ImageNet-C benchmarks, reducing error by up to 5.4%, 9.1%, and 2.9%, respectively. Also, we provide an extensive analysis to demonstrate effectiveness of our framework. Code is available at https://github.com/gist-ailab/domain-specific-block-selection-and-paired-view-pseudo-labeling-for-online-TTA.
INSTA-BEEER: Explicit Error Estimation and Refinement for Fast and Accurate Unseen Object Instance Segmentation
Jun 28, 2023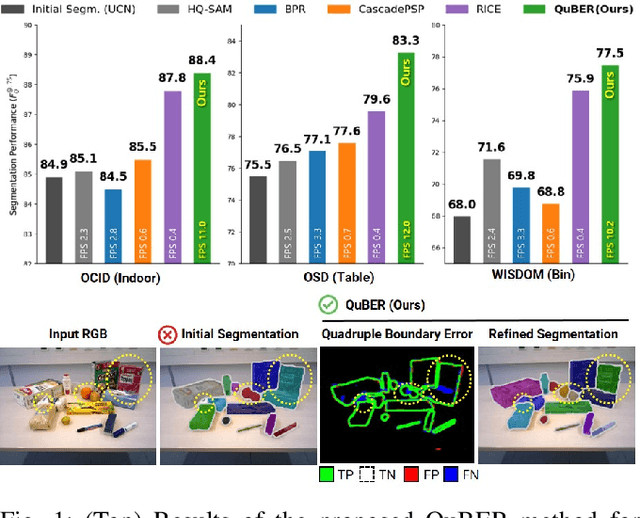

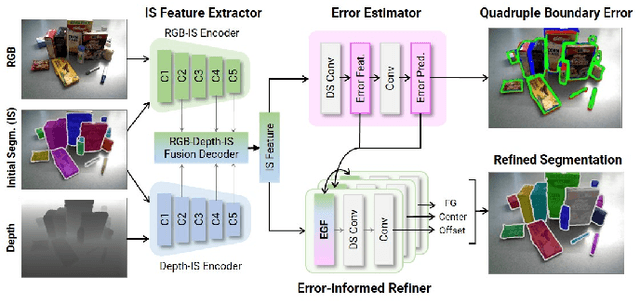

Efficient and accurate segmentation of unseen objects is crucial for robotic manipulation. However, it remains challenging due to over- or under-segmentation. Although existing refinement methods can enhance the segmentation quality, they fix only minor boundary errors or are not sufficiently fast. In this work, we propose INSTAnce Boundary Explicit Error Estimation and Refinement (INSTA-BEEER), a novel refinement model that allows for adding and deleting instances and sharpening boundaries. Leveraging an error-estimation-then-refinement scheme, the model first estimates the pixel-wise boundary explicit errors: true positive, true negative, false positive, and false negative pixels of the instance boundary in the initial segmentation. It then refines the initial segmentation using these error estimates as guidance. Experiments show that the proposed model significantly enhances segmentation, achieving state-of-the-art performance. Furthermore, with a fast runtime (less than 0.1 s), the model consistently improves performance across various initial segmentation methods, making it highly suitable for practical robotic applications.
Learning to Place Unseen Objects Stably using a Large-scale Simulation
Mar 15, 2023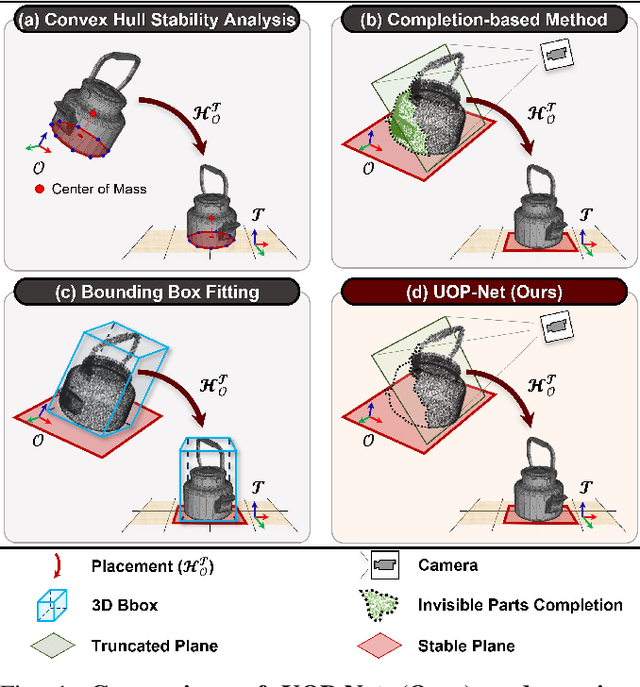
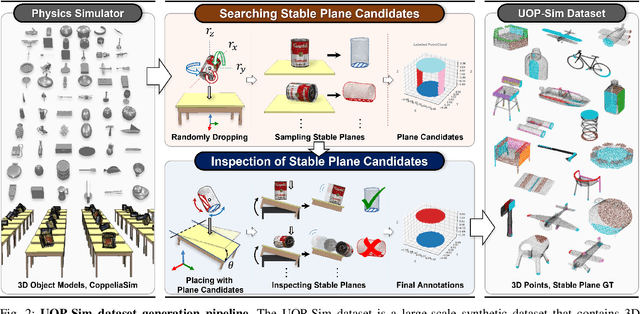
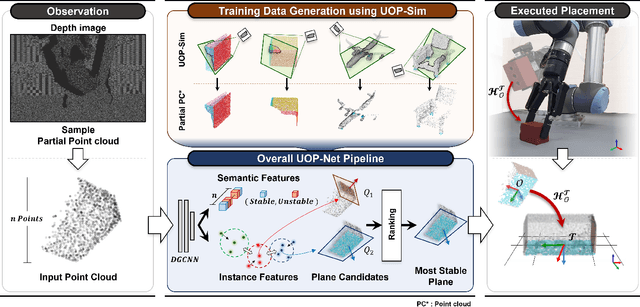
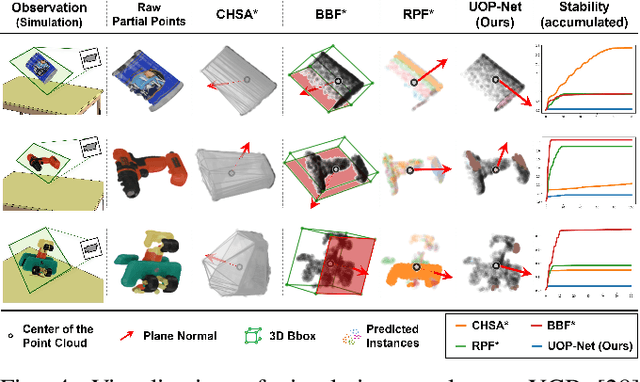
Object placement is a crucial task for robots in unstructured environments as it enables them to manipulate and arrange objects safely and efficiently. However, existing methods for object placement have limitations, such as the requirement for a complete 3D model of the object or the inability to handle complex object shapes, which restrict the applicability of robots in unstructured scenarios. In this paper, we propose an Unseen Object Placement (UOP) method that directly detects stable planes of unseen objects from a single-view and partial point cloud. We trained our model on large-scale simulation data to generalize over relationships between the shape and properties of stable planes with a 3D point cloud. We verify our approach through simulation and real-world robot experiments, demonstrating state-of-the-art performance for placing single-view and partial objects. Our UOP approach enables robots to place objects stably, even when the object's shape and properties are not fully known, providing a promising solution for object placement in unstructured environments. Our research has potential applications in various domains such as manufacturing, logistics, and home automation. Additional results can be viewed on https://sites.google.com/uop-net, and we will release our code, dataset upon publication.
SleePyCo: Automatic Sleep Scoring with Feature Pyramid and Contrastive Learning
Sep 20, 2022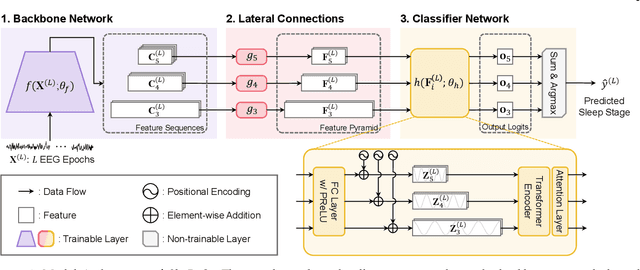
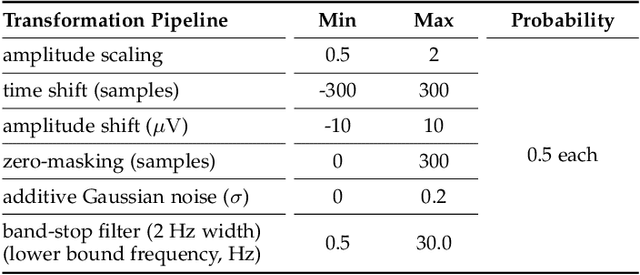
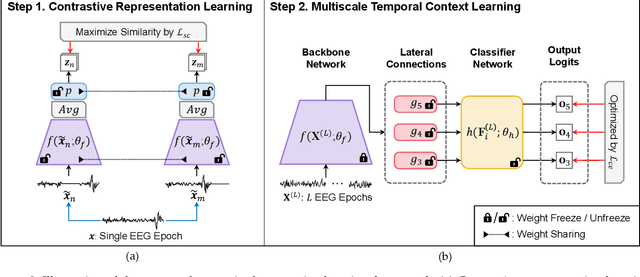
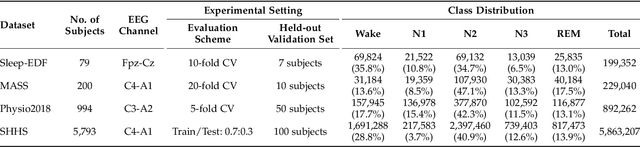
Automatic sleep scoring is essential for the diagnosis and treatment of sleep disorders and enables longitudinal sleep tracking in home environments. Conventionally, learning-based automatic sleep scoring on single-channel electroencephalogram (EEG) is actively studied because obtaining multi-channel signals during sleep is difficult. However, learning representation from raw EEG signals is challenging owing to the following issues: 1) sleep-related EEG patterns occur on different temporal and frequency scales and 2) sleep stages share similar EEG patterns. To address these issues, we propose a deep learning framework named SleePyCo that incorporates 1) a feature pyramid and 2) supervised contrastive learning for automatic sleep scoring. For the feature pyramid, we propose a backbone network named SleePyCo-backbone to consider multiple feature sequences on different temporal and frequency scales. Supervised contrastive learning allows the network to extract class discriminative features by minimizing the distance between intra-class features and simultaneously maximizing that between inter-class features. Comparative analyses on four public datasets demonstrate that SleePyCo consistently outperforms existing frameworks based on single-channel EEG. Extensive ablation experiments show that SleePyCo exhibits enhanced overall performance, with significant improvements in discrimination between the N1 and rapid eye movement (REM) stages.
Automatic Detection of Injection and Press Mold Parts on 2D Drawing Using Deep Neural Network
Oct 22, 2021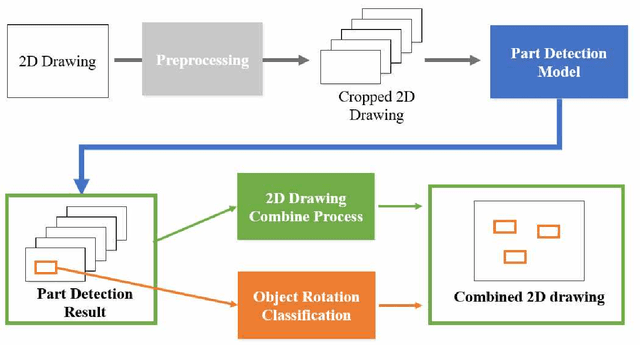
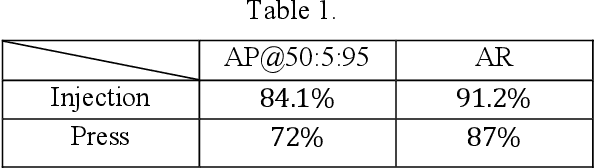
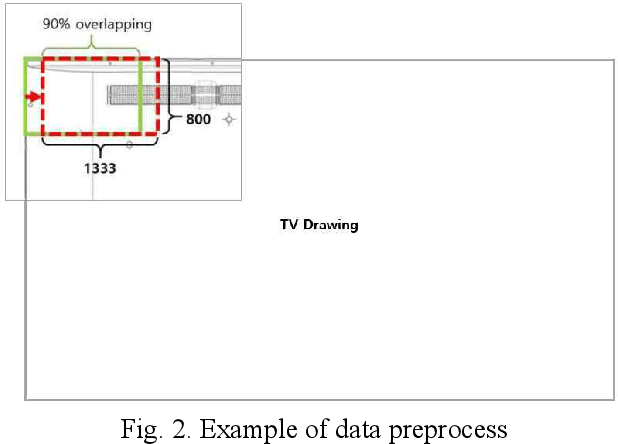
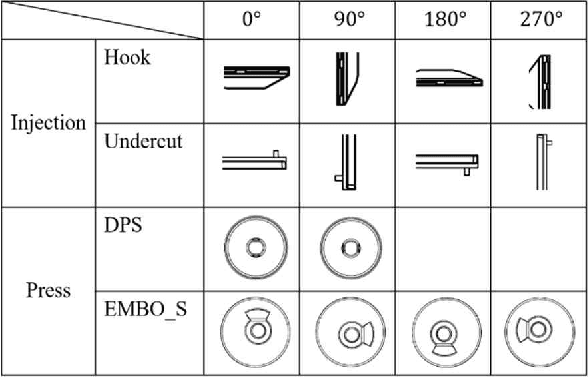
This paper proposes a method to automatically detect the key feature parts in a CAD of commercial TV and monitor using a deep neural network. We developed a deep learning pipeline that can detect the injection parts such as hook, boss, undercut and press parts such as DPS, Embo-Screwless, Embo-Burring, and EMBO in the 2D CAD drawing images. We first cropped the drawing to a specific size for the training efficiency of a deep neural network. Then, we use Cascade R-CNN to find the position of injection and press parts and use Resnet-50 to predict the orientation of the parts. Finally, we convert the position of the parts found through the cropped image to the position of the original image. As a result, we obtained detection accuracy of injection and press parts with 84.1% in AP (Average Precision), 91.2% in AR(Average Recall), 72.0% in AP, 87.0% in AR, and orientation accuracy of injection and press parts with 94.4% and 92.0%, which can facilitate the faster design in industrial product design.
Unseen Object Amodal Instance Segmentation via Hierarchical Occlusion Modeling
Sep 23, 2021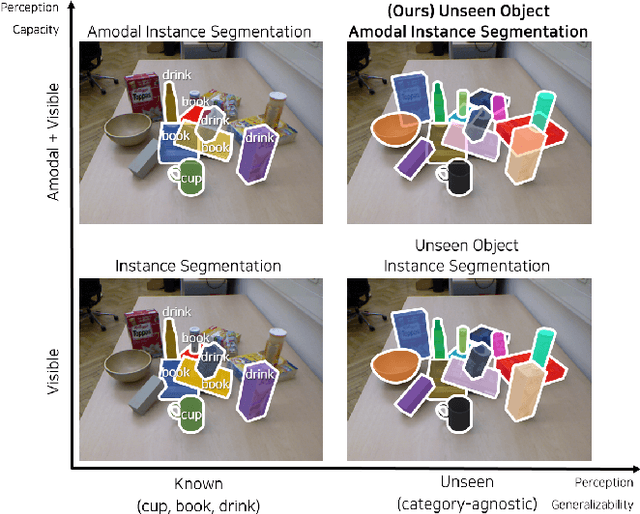
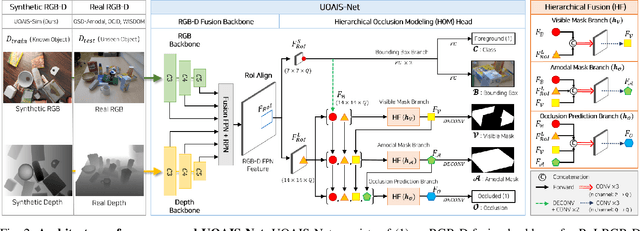
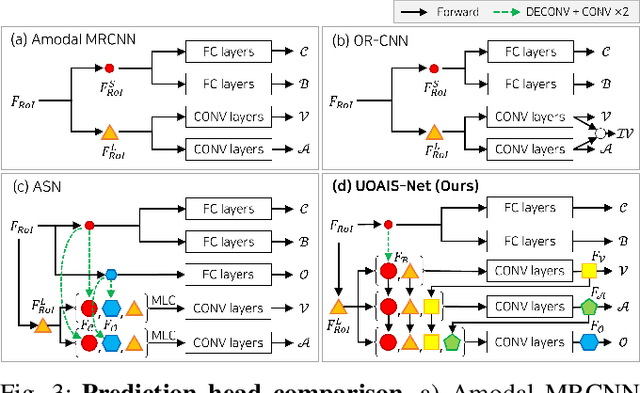

Instance-aware segmentation of unseen objects is essential for a robotic system in an unstructured environment. Although previous works achieved encouraging results, they were limited to segmenting the only visible regions of unseen objects. For robotic manipulation in a cluttered scene, amodal perception is required to handle the occluded objects behind others. This paper addresses Unseen Object Amodal Instance Segmentation (UOAIS) to detect 1) visible masks, 2) amodal masks, and 3) occlusions on unseen object instances. For this, we propose a Hierarchical Occlusion Modeling (HOM) scheme designed to reason about the occlusion by assigning a hierarchy to a feature fusion and prediction order. We evaluated our method on three benchmarks (tabletop, indoors, and bin environments) and achieved state-of-the-art (SOTA) performance. Robot demos for picking up occluded objects, codes, and datasets are available at https://sites.google.com/view/uoais
Object Detection for Understanding Assembly Instruction Using Context-aware Data Augmentation and Cascade Mask R-CNN
Jan 08, 2021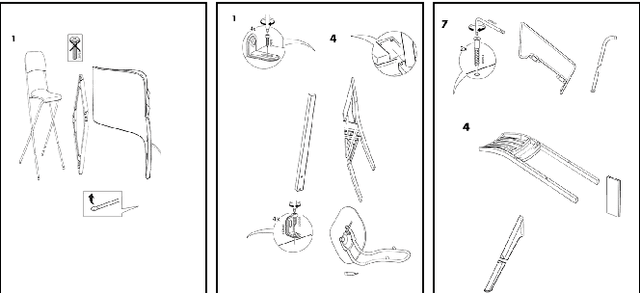

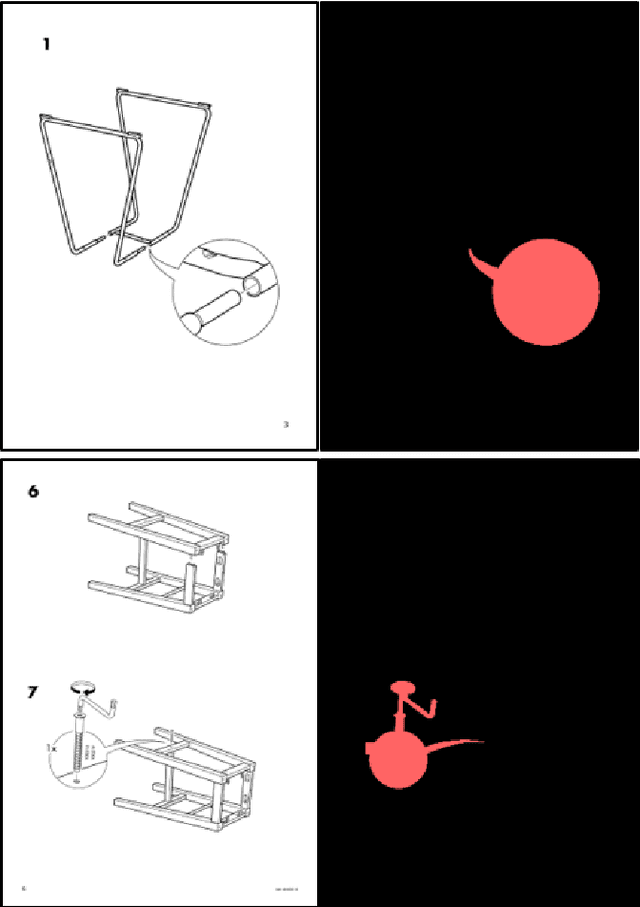
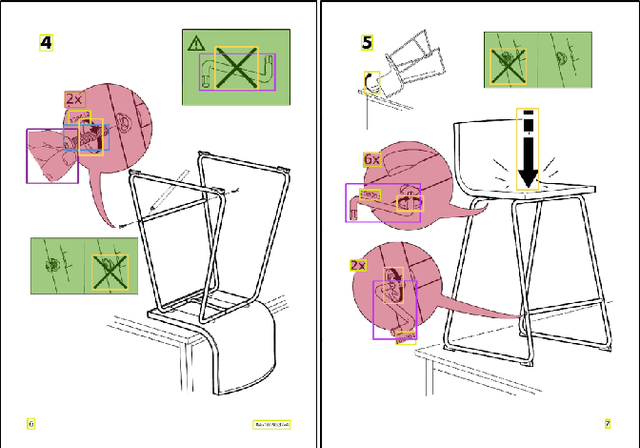
Understanding assembly instruction has the potential to enhance the robot s task planning ability and enables advanced robotic applications. To recognize the key components from the 2D assembly instruction image, We mainly focus on segmenting the speech bubble area, which contains lots of information about instructions. For this, We applied Cascade Mask R-CNN and developed a context-aware data augmentation scheme for speech bubble segmentation, which randomly combines images cuts by considering the context of assembly instructions. We showed that the proposed augmentation scheme achieves a better segmentation performance compared to the existing augmentation algorithm by increasing the diversity of trainable data while considering the distribution of components locations. Also, we showed that deep learning can be useful to understand assembly instruction by detecting the essential objects in the assembly instruction, such as tools and parts.
Segmenting Unseen Industrial Components in a Heavy Clutter Using RGB-D Fusion and Synthetic Data
Feb 11, 2020



Segmentation of unseen industrial parts is essential for autonomous industrial systems. However, industrial components are texture-less, reflective, and often found in cluttered and unstructured environments with heavy occlusion, which makes it more challenging to deal with unseen objects. To tackle this problem, we propose a synthetic data generation pipeline that randomizes textures via domain randomization to focus on the shape information. In addition, we propose an RGB-D Fusion Mask R-CNN with a confidence map estimator, which exploits reliable depth information in multiple feature levels. We transferred the trained model to real-world scenarios and evaluated its performance by making comparisons with baselines and ablation studies. We demonstrate that our methods, which use only synthetic data, could be effective solutions for unseen industrial components segmentation.
Intra- and Inter-epoch Temporal Context Network (IITNet) for Automatic Sleep Stage Scoring
Feb 18, 2019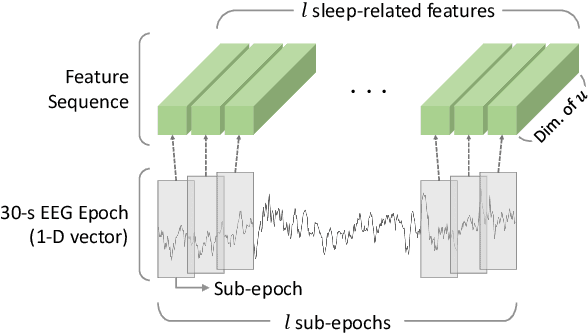

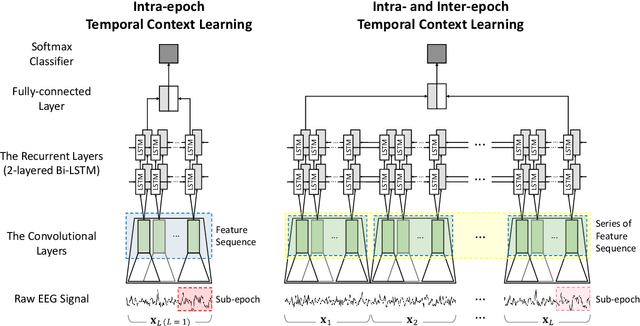
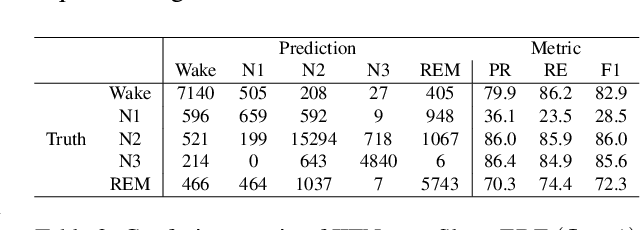
This study proposes a novel deep learning model, called IITNet, to learn intra- and inter-epoch temporal contexts from a raw single channel electroencephalogram (EEG) for automatic sleep stage scoring. When sleep experts identify the sleep stage of a 30-second PSG data called an epoch, they investigate the sleep-related events such as sleep spindles, K-complex, and frequency components from local segments of an epoch (sub-epoch) and consider the relations between sleep-related events of successive epochs to follow the transition rules. Inspired by this, IITNet learns how to encode sub-epoch into representative feature via a deep residual network, then captures contextual information in the sequence of representative features via BiLSTM. Thus, IITNet can extract features in sub-epoch level and consider temporal context not only between epochs but also in an epoch. IITNet is an end-to-end architecture and does not need any preprocessing, handcrafted feature design, balanced sampling, pre-training, or fine-tuning. Our model was trained and evaluated in Sleep-EDF and MASS datasets and outperformed other state-of-the-art results on both the datasets with the overall accuracy (ACC) of 84.0% and 86.6%, macro F1-score (MF1) of 77.7 and 80.8, and Cohen's kappa of 0.78 and 0.80 in Sleep-EDF and MASS, respectively.