 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4th Workshop on Maritime Computer Vision (MaCVi): Challenge Overview
Apr 14, 2026The 4th Workshop on Maritime Computer Vision (MaCVi) is organized as part of CVPR 2026. This edition features five benchmark challenges with emphasis on both predictive accuracy and embedded real-time feasibility. This report summarizes the MaCVi 2026 challenge setup, evaluation protocols, datasets, and benchmark tracks, and presents quantitative results, qualitative comparisons, and cross-challenge analyses of emerging method trends. We also include technical reports from top-performing teams to highlight practical design choices and lessons learned across the benchmark suite. Datasets, leaderboards, and challenge resources are available at https://macvi.org/workshop/cvpr26.
CD-FKD: Cross-Domain Feature Knowledge Distillation for Robust Single-Domain Generalization in Object Detection
Mar 17, 2026Single-domain generalization is essential for object detection, particularly when training models on a single source domain and evaluating them on unseen target domains. Domain shifts, such as changes in weather, lighting, or scene conditions, pose significant challenges to the generalization ability of existing models. To address this, we propose Cross-Domain Feature Knowledge Distillation (CD-FKD), which enhances the generalization capability of the student network by leveraging both global and instance-wise feature distillation. The proposed method uses diversified data through downscaling and corruption to train the student network, whereas the teacher network receives the original source domain data. The student network mimics the features of the teacher through both global and instance-wise distillation, enabling it to extract object-centric features effectively, even for objects that are difficult to detect owing to corruption. Extensive experiments on challenging scenes demonstrate that CD-FKD outperforms state-of-the-art methods in both target domain generalization and source domain performance, validating its effectiveness in improving object detection robustness to domain shifts. This approach is valuable in real-world applications, like autonomous driving and surveillance, where robust object detection in diverse environments is crucial.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
MART: MultiscAle Relational Transformer Networks for Multi-agent Trajectory Prediction
Jul 31, 2024Multi-agent trajectory prediction is crucial to autonomous driving and understanding the surrounding environment. Learning-based approaches for multi-agent trajectory prediction, such as primarily relying on graph neural networks, graph transformers, and hypergraph neural networks, have demonstrated outstanding performance on real-world datasets in recent years. However, the hypergraph transformer-based method for trajectory prediction is yet to be explored. Therefore, we present a MultiscAle Relational Transformer (MART) network for multi-agent trajectory prediction. MART is a hypergraph transformer architecture to consider individual and group behaviors in transformer machinery. The core module of MART is the encoder, which comprises a Pair-wise Relational Transformer (PRT) and a Hyper Relational Transformer (HRT). The encoder extends the capabilities of a relational transformer by introducing HRT, which integrates hyperedge features into the transformer mechanism, promoting attention weights to focus on group-wise relations. In addition, we propose an Adaptive Group Estimator (AGE) designed to infer complex group relations in real-world environments. Extensive experiments on three real-world datasets (NBA, SDD, and ETH-UCY) demonstrate that our method achieves state-of-the-art performance, enhancing ADE/FDE by 3.9%/11.8% on the NBA dataset. Code is available at https://github.com/gist-ailab/MART.
Block Selection Method for Using Feature Norm in Out-of-distribution Detection
Dec 10, 2022



Detecting out-of-distribution (OOD) inputs during the inference stage is crucial for deploying neural networks in the real world. Previous methods commonly relied on the output of a network derived from the highly activated feature map. In this study, we first revealed that a norm of the feature map obtained from the other block than the last block can be a better indicator of OOD detection. Motivated by this, we propose a simple framework consisting of FeatureNorm: a norm of the feature map and NormRatio: a ratio of FeatureNorm for ID and OOD to measure the OOD detection performance of each block. In particular, to select the block that provides the largest difference between FeatureNorm of ID and FeatureNorm of OOD, we create Jigsaw puzzle images as pseudo OOD from ID training samples and calculate NormRatio, and the block with the largest value is selected. After the suitable block is selected, OOD detection with the FeatureNorm outperforms other OOD detection methods by reducing FPR95 by up to 52.77% on CIFAR10 benchmark and by up to 48.53% on ImageNet benchmark. We demonstrate that our framework can generalize to various architectures and the importance of block selection, which can improve previous OOD detection methods as well.
SleePyCo: Automatic Sleep Scoring with Feature Pyramid and Contrastive Learning
Sep 20, 2022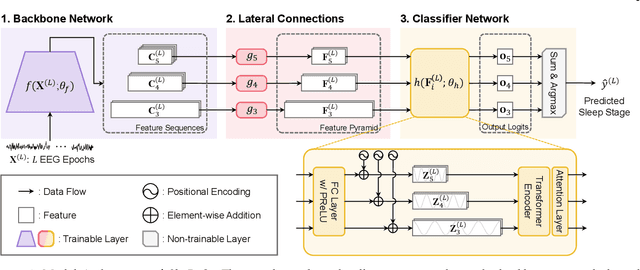
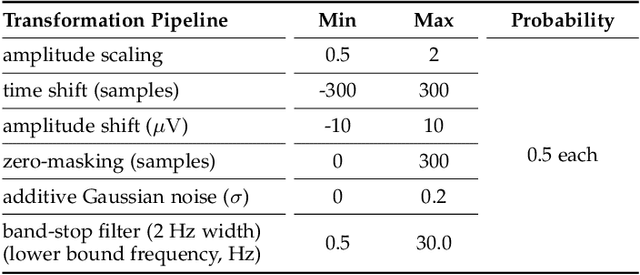
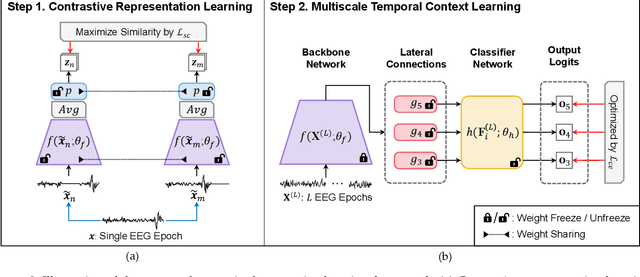
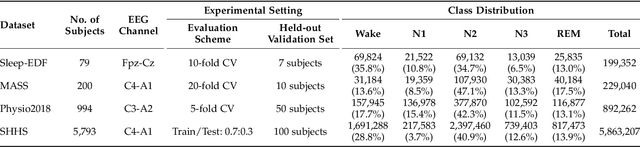
Automatic sleep scoring is essential for the diagnosis and treatment of sleep disorders and enables longitudinal sleep tracking in home environments. Conventionally, learning-based automatic sleep scoring on single-channel electroencephalogram (EEG) is actively studied because obtaining multi-channel signals during sleep is difficult. However, learning representation from raw EEG signals is challenging owing to the following issues: 1) sleep-related EEG patterns occur on different temporal and frequency scales and 2) sleep stages share similar EEG patterns. To address these issues, we propose a deep learning framework named SleePyCo that incorporates 1) a feature pyramid and 2) supervised contrastive learning for automatic sleep scoring. For the feature pyramid, we propose a backbone network named SleePyCo-backbone to consider multiple feature sequences on different temporal and frequency scales. Supervised contrastive learning allows the network to extract class discriminative features by minimizing the distance between intra-class features and simultaneously maximizing that between inter-class features. Comparative analyses on four public datasets demonstrate that SleePyCo consistently outperforms existing frameworks based on single-channel EEG. Extensive ablation experiments show that SleePyCo exhibits enhanced overall performance, with significant improvements in discrimination between the N1 and rapid eye movement (REM) stages.
Object Detection for Understanding Assembly Instruction Using Context-aware Data Augmentation and Cascade Mask R-CNN
Jan 08, 2021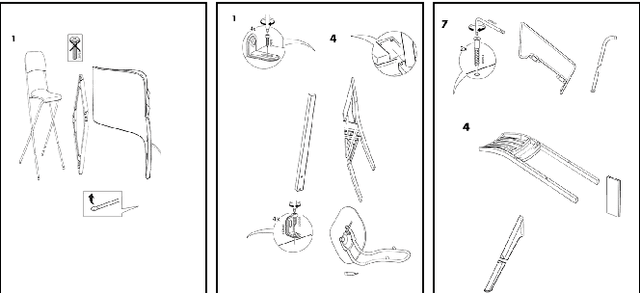

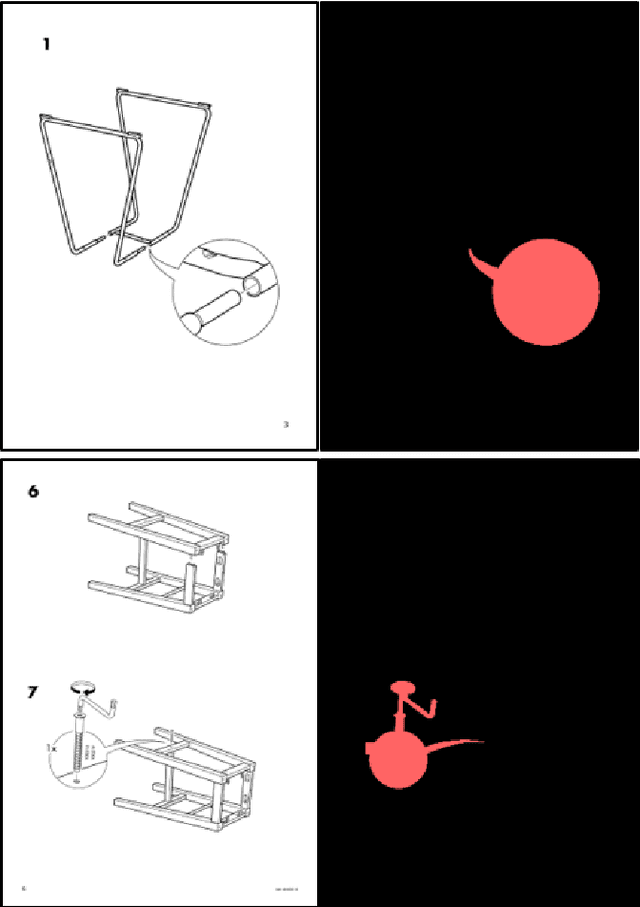
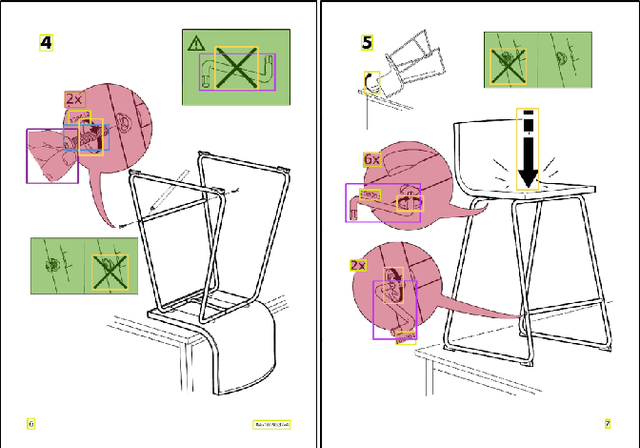
Understanding assembly instruction has the potential to enhance the robot s task planning ability and enables advanced robotic applications. To recognize the key components from the 2D assembly instruction image, We mainly focus on segmenting the speech bubble area, which contains lots of information about instructions. For this, We applied Cascade Mask R-CNN and developed a context-aware data augmentation scheme for speech bubble segmentation, which randomly combines images cuts by considering the context of assembly instructions. We showed that the proposed augmentation scheme achieves a better segmentation performance compared to the existing augmentation algorithm by increasing the diversity of trainable data while considering the distribution of components locations. Also, we showed that deep learning can be useful to understand assembly instruction by detecting the essential objects in the assembly instruction, such as tools and parts.
Intra- and Inter-epoch Temporal Context Network (IITNet) for Automatic Sleep Stage Scoring
Feb 18, 2019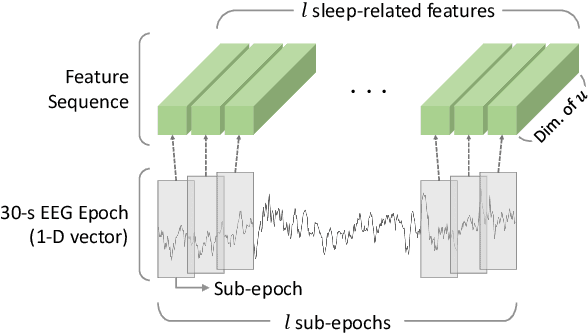

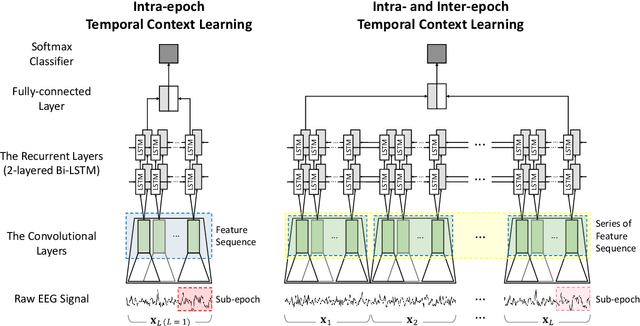
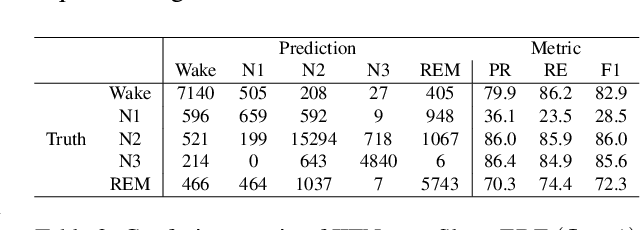
This study proposes a novel deep learning model, called IITNet, to learn intra- and inter-epoch temporal contexts from a raw single channel electroencephalogram (EEG) for automatic sleep stage scoring. When sleep experts identify the sleep stage of a 30-second PSG data called an epoch, they investigate the sleep-related events such as sleep spindles, K-complex, and frequency components from local segments of an epoch (sub-epoch) and consider the relations between sleep-related events of successive epochs to follow the transition rules. Inspired by this, IITNet learns how to encode sub-epoch into representative feature via a deep residual network, then captures contextual information in the sequence of representative features via BiLSTM. Thus, IITNet can extract features in sub-epoch level and consider temporal context not only between epochs but also in an epoch. IITNet is an end-to-end architecture and does not need any preprocessing, handcrafted feature design, balanced sampling, pre-training, or fine-tuning. Our model was trained and evaluated in Sleep-EDF and MASS datasets and outperformed other state-of-the-art results on both the datasets with the overall accuracy (ACC) of 84.0% and 86.6%, macro F1-score (MF1) of 77.7 and 80.8, and Cohen's kappa of 0.78 and 0.80 in Sleep-EDF and MASS, respectively.