 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrading Handwritten Engineering Exams with Multimodal Large Language Models
Jan 02, 2026Handwritten STEM exams capture open-ended reasoning and diagrams, but manual grading is slow and difficult to scale. We present an end-to-end workflow for grading scanned handwritten engineering quizzes with multimodal large language models (LLMs) that preserves the standard exam process (A4 paper, unconstrained student handwriting). The lecturer provides only a handwritten reference solution (100%) and a short set of grading rules; the reference is converted into a text-only summary that conditions grading without exposing the reference scan. Reliability is achieved through a multi-stage design with a format/presence check to prevent grading blank answers, an ensemble of independent graders, supervisor aggregation, and rigid templates with deterministic validation to produce auditable, machine-parseable reports. We evaluate the frozen pipeline in a clean-room protocol on a held-out real course quiz in Slovenian, including hand-drawn circuit schematics. With state-of-the-art backends (GPT-5.2 and Gemini-3 Pro), the full pipeline achieves $\approx$8-point mean absolute difference to lecturer grades with low bias and an estimated manual-review trigger rate of $\approx$17% at $D_{\max}=40$. Ablations show that trivial prompting and removing the reference solution substantially degrade accuracy and introduce systematic over-grading, confirming that structured prompting and reference grounding are essential.
MULTIAQUA: A multimodal maritime dataset and robust training strategies for multimodal semantic segmentation
Dec 19, 2025



Unmanned surface vehicles can encounter a number of varied visual circumstances during operation, some of which can be very difficult to interpret. While most cases can be solved only using color camera images, some weather and lighting conditions require additional information. To expand the available maritime data, we present a novel multimodal maritime dataset MULTIAQUA (Multimodal Aquatic Dataset). Our dataset contains synchronized, calibrated and annotated data captured by sensors of different modalities, such as RGB, thermal, IR, LIDAR, etc. The dataset is aimed at developing supervised methods that can extract useful information from these modalities in order to provide a high quality of scene interpretation regardless of potentially poor visibility conditions. To illustrate the benefits of the proposed dataset, we evaluate several multimodal methods on our difficult nighttime test set. We present training approaches that enable multimodal methods to be trained in a more robust way, thus enabling them to retain reliable performance even in near-complete darkness. Our approach allows for training a robust deep neural network only using daytime images, thus significantly simplifying data acquisition, annotation, and the training process.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
Dense Center-Direction Regression for Object Counting and Localization with Point Supervision
Aug 26, 2024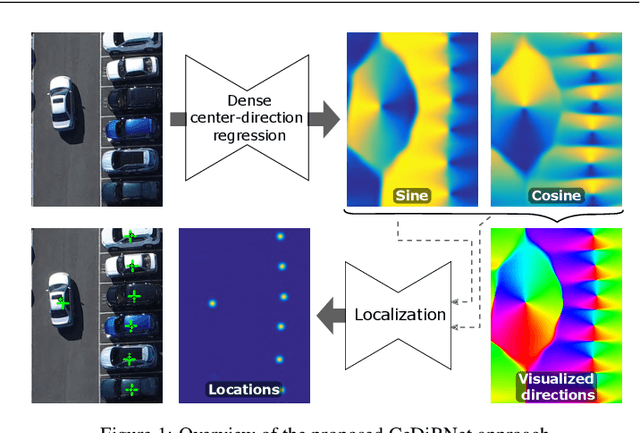



Object counting and localization problems are commonly addressed with point supervised learning, which allows the use of less labor-intensive point annotations. However, learning based on point annotations poses challenges due to the high imbalance between the sets of annotated and unannotated pixels, which is often treated with Gaussian smoothing of point annotations and focal loss. However, these approaches still focus on the pixels in the immediate vicinity of the point annotations and exploit the rest of the data only indirectly. In this work, we propose a novel approach termed CeDiRNet for point-supervised learning that uses a dense regression of directions pointing towards the nearest object centers, i.e. center-directions. This provides greater support for each center point arising from many surrounding pixels pointing towards the object center. We propose a formulation of center-directions that allows the problem to be split into the domain-specific dense regression of center-directions and the final localization task based on a small, lightweight, and domain-agnostic localization network that can be trained with synthetic data completely independent of the target domain. We demonstrate the performance of the proposed method on six different datasets for object counting and localization, and show that it outperforms the existing state-of-the-art methods. The code is accessible on GitHub at https://github.com/vicoslab/CeDiRNet.git.
Center Direction Network for Grasping Point Localization on Cloths
Aug 26, 2024



Object grasping is a fundamental challenge in robotics and computer vision, critical for advancing robotic manipulation capabilities. Deformable objects, like fabrics and cloths, pose additional challenges due to their non-rigid nature. In this work, we introduce CeDiRNet-3DoF, a deep-learning model for grasp point detection, with a particular focus on cloth objects. CeDiRNet-3DoF employs center direction regression alongside a localization network, attaining first place in the perception task of ICRA 2023's Cloth Manipulation Challenge. Recognizing the lack of standardized benchmarks in the literature that hinder effective method comparison, we present the ViCoS Towel Dataset. This extensive benchmark dataset comprises 8,000 real and 12,000 synthetic images, serving as a robust resource for training and evaluating contemporary data-driven deep-learning approaches. Extensive evaluation revealed CeDiRNet-3DoF's robustness in real-world performance, outperforming state-of-the-art methods, including the latest transformer-based models. Our work bridges a crucial gap, offering a robust solution and benchmark for cloth grasping in computer vision and robotics. Code and dataset are available at: https://github.com/vicoslab/CeDiRNet-3DoF
MODS -- A USV-oriented object detection and obstacle segmentation benchmark
May 05, 2021



Small-sized unmanned surface vehicles (USV) are coastal water devices with a broad range of applications such as environmental control and surveillance. A crucial capability for autonomous operation is obstacle detection for timely reaction and collision avoidance, which has been recently explored in the context of camera-based visual scene interpretation. Owing to curated datasets, substantial advances in scene interpretation have been made in a related field of unmanned ground vehicles. However, the current maritime datasets do not adequately capture the complexity of real-world USV scenes and the evaluation protocols are not standardised, which makes cross-paper comparison of different methods difficult and hiders the progress. To address these issues, we introduce a new obstacle detection benchmark MODS, which considers two major perception tasks: maritime object detection and the more general maritime obstacle segmentation. We present a new diverse maritime evaluation dataset containing approximately 81k stereo images synchronized with an on-board IMU, with over 60k objects annotated. We propose a new obstacle segmentation performance evaluation protocol that reflects the detection accuracy in a way meaningful for practical USV navigation. Seventeen recent state-of-the-art object detection and obstacle segmentation methods are evaluated using the proposed protocol, creating a benchmark to facilitate development of the field.
Correcting Decalibration of Stereo Cameras in Self-Driving Vehicles
Jan 15, 2020


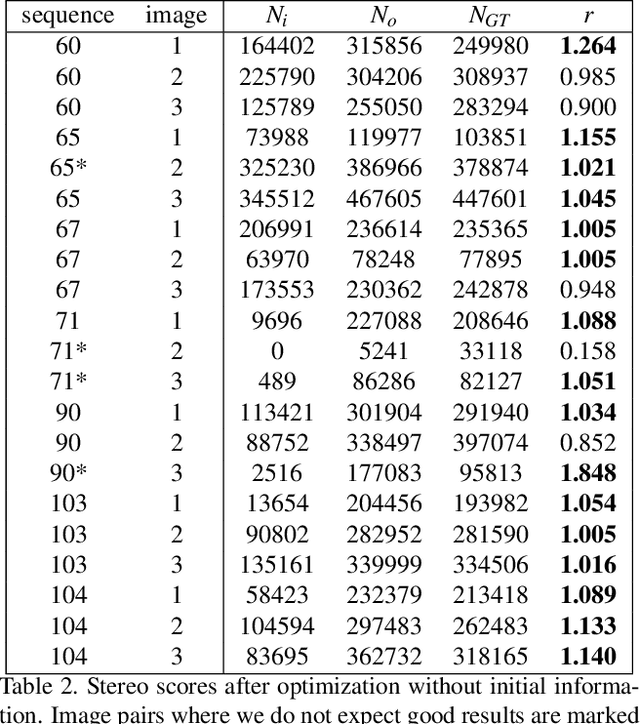
We address the problem of optical decalibration in mobile stereo camera setups, especially in context of autonomous vehicles. In real world conditions, an optical system is subject to various sources of anticipated and unanticipated mechanical stress (vibration, rough handling, collisions). Mechanical stress changes the geometry between the cameras that make up the stereo pair, and as a consequence, the pre-calculated epipolar geometry is no longer valid. Our method is based on optimization of camera geometry parameters and plugs directly into the output of the stereo matching algorithm. Therefore, it is able to recover calibration parameters on image pairs obtained from a decalibrated stereo system with minimal use of additional computing resources. The number of successfully recovered depth pixels is used as an objective function, which we aim to maximize. Our simulation confirms that the method can run constantly in parallel to stereo estimation and thus help keep the system calibrated in real time. Results confirm that the method is able to recalibrate all the parameters except for the baseline distance, which scales the absolute depth readings. However, that scaling factor could be uniquely determined using any kind of absolute range finding methods (e.g. a single beam time-of-flight sensor).