 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenter Direction Network for Grasping Point Localization on Cloths
Aug 26, 2024



Object grasping is a fundamental challenge in robotics and computer vision, critical for advancing robotic manipulation capabilities. Deformable objects, like fabrics and cloths, pose additional challenges due to their non-rigid nature. In this work, we introduce CeDiRNet-3DoF, a deep-learning model for grasp point detection, with a particular focus on cloth objects. CeDiRNet-3DoF employs center direction regression alongside a localization network, attaining first place in the perception task of ICRA 2023's Cloth Manipulation Challenge. Recognizing the lack of standardized benchmarks in the literature that hinder effective method comparison, we present the ViCoS Towel Dataset. This extensive benchmark dataset comprises 8,000 real and 12,000 synthetic images, serving as a robust resource for training and evaluating contemporary data-driven deep-learning approaches. Extensive evaluation revealed CeDiRNet-3DoF's robustness in real-world performance, outperforming state-of-the-art methods, including the latest transformer-based models. Our work bridges a crucial gap, offering a robust solution and benchmark for cloth grasping in computer vision and robotics. Code and dataset are available at: https://github.com/vicoslab/CeDiRNet-3DoF
Dense Center-Direction Regression for Object Counting and Localization with Point Supervision
Aug 26, 2024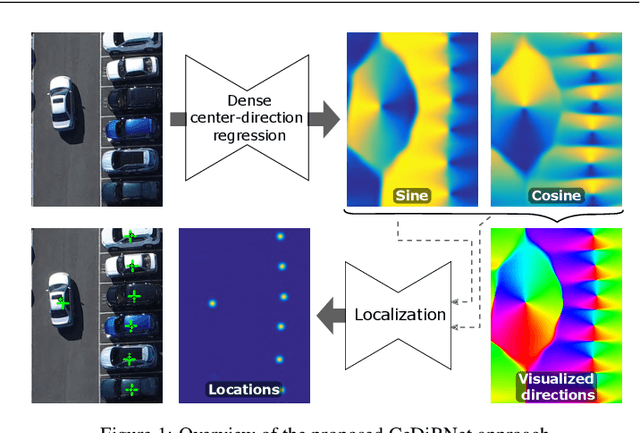



Object counting and localization problems are commonly addressed with point supervised learning, which allows the use of less labor-intensive point annotations. However, learning based on point annotations poses challenges due to the high imbalance between the sets of annotated and unannotated pixels, which is often treated with Gaussian smoothing of point annotations and focal loss. However, these approaches still focus on the pixels in the immediate vicinity of the point annotations and exploit the rest of the data only indirectly. In this work, we propose a novel approach termed CeDiRNet for point-supervised learning that uses a dense regression of directions pointing towards the nearest object centers, i.e. center-directions. This provides greater support for each center point arising from many surrounding pixels pointing towards the object center. We propose a formulation of center-directions that allows the problem to be split into the domain-specific dense regression of center-directions and the final localization task based on a small, lightweight, and domain-agnostic localization network that can be trained with synthetic data completely independent of the target domain. We demonstrate the performance of the proposed method on six different datasets for object counting and localization, and show that it outperforms the existing state-of-the-art methods. The code is accessible on GitHub at https://github.com/vicoslab/CeDiRNet.git.
Mixed supervision for surface-defect detection: from weakly to fully supervised learning
Apr 20, 2021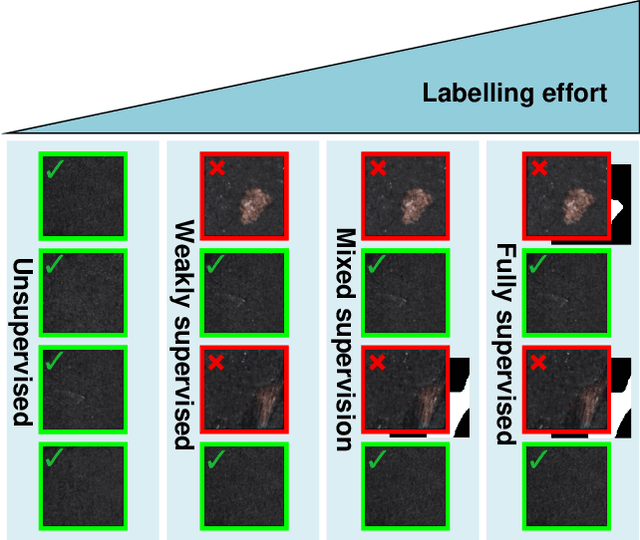
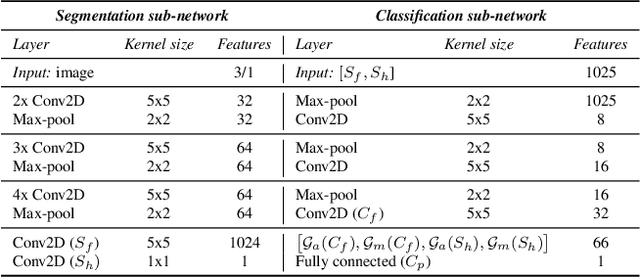
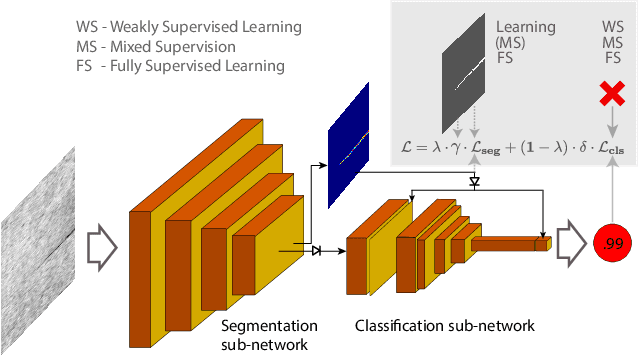
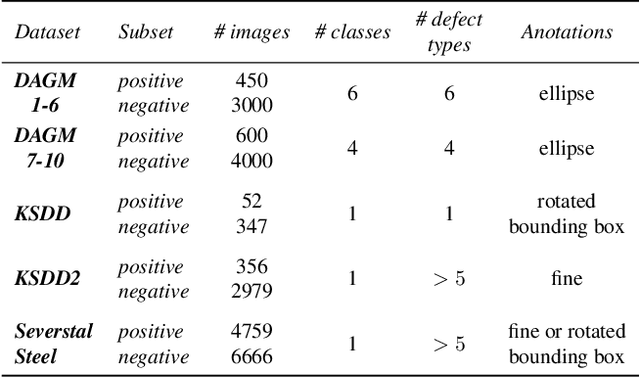
Deep-learning methods have recently started being employed for addressing surface-defect detection problems in industrial quality control. However, with a large amount of data needed for learning, often requiring high-precision labels, many industrial problems cannot be easily solved, or the cost of the solutions would significantly increase due to the annotation requirements. In this work, we relax heavy requirements of fully supervised learning methods and reduce the need for highly detailed annotations. By proposing a deep-learning architecture, we explore the use of annotations of different details ranging from weak (image-level) labels through mixed supervision to full (pixel-level) annotations on the task of surface-defect detection. The proposed end-to-end architecture is composed of two sub-networks yielding defect segmentation and classification results. The proposed method is evaluated on several datasets for industrial quality inspection: KolektorSDD, DAGM and Severstal Steel Defect. We also present a new dataset termed KolektorSDD2 with over 3000 images containing several types of defects, obtained while addressing a real-world industrial problem. We demonstrate state-of-the-art results on all four datasets. The proposed method outperforms all related approaches in fully supervised settings and also outperforms weakly-supervised methods when only image-level labels are available. We also show that mixed supervision with only a handful of fully annotated samples added to weakly labelled training images can result in performance comparable to the fully supervised model's performance but at a significantly lower annotation cost.
End-to-end training of a two-stage neural network for defect detection
Jul 15, 2020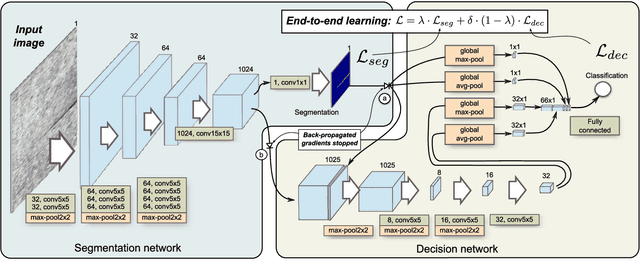
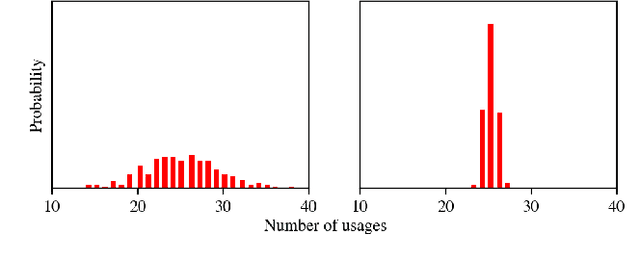


Segmentation-based, two-stage neural network has shown excellent results in the surface defect detection, enabling the network to learn from a relatively small number of samples. In this work, we introduce end-to-end training of the two-stage network together with several extensions to the training process, which reduce the amount of training time and improve the results on the surface defect detection tasks. To enable end-to-end training we carefully balance the contributions of both the segmentation and the classification loss throughout the learning. We adjust the gradient flow from the classification into the segmentation network in order to prevent the unstable features from corrupting the learning. As an additional extension to the learning, we propose frequency-of-use sampling scheme of negative samples to address the issue of over- and under-sampling of images during the training, while we employ the distance transform algorithm on the region-based segmentation masks as weights for positive pixels, giving greater importance to areas with higher probability of presence of defect without requiring a detailed annotation. We demonstrate the performance of the end-to-end training scheme and the proposed extensions on three defect detection datasets - DAGM, KolektorSDD and Severstal Steel defect dataset - where we show state-of-the-art results. On the DAGM and the KolektorSDD we demonstrate 100\% detection rate, therefore completely solving the datasets. Additional ablation study performed on all three datasets quantitatively demonstrates the contribution to the overall result improvements for each of the proposed extensions.
Deep Learning for Large-Scale Traffic-Sign Detection and Recognition
Apr 01, 2019

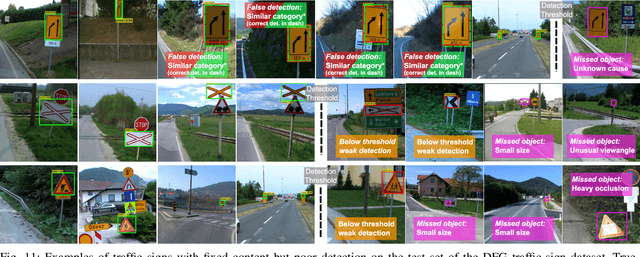

Automatic detection and recognition of traffic signs plays a crucial role in management of the traffic-sign inventory. It provides accurate and timely way to manage traffic-sign inventory with a minimal human effort. In the computer vision community the recognition and detection of traffic signs is a well-researched problem. A vast majority of existing approaches perform well on traffic signs needed for advanced drivers-assistance and autonomous systems. However, this represents a relatively small number of all traffic signs (around 50 categories out of several hundred) and performance on the remaining set of traffic signs, which are required to eliminate the manual labor in traffic-sign inventory management, remains an open question. In this paper, we address the issue of detecting and recognizing a large number of traffic-sign categories suitable for automating traffic-sign inventory management. We adopt a convolutional neural network (CNN) approach, the Mask R-CNN, to address the full pipeline of detection and recognition with automatic end-to-end learning. We propose several improvements that are evaluated on the detection of traffic signs and result in an improved overall performance. This approach is applied to detection of 200 traffic-sign categories represented in our novel dataset. Results are reported on highly challenging traffic-sign categories that have not yet been considered in previous works. We provide comprehensive analysis of the deep learning method for the detection of traffic signs with large intra-category appearance variation and show below 3% error rates with the proposed approach, which is sufficient for deployment in practical applications of traffic-sign inventory management.
Segmentation-Based Deep-Learning Approach for Surface-Defect Detection
Mar 20, 2019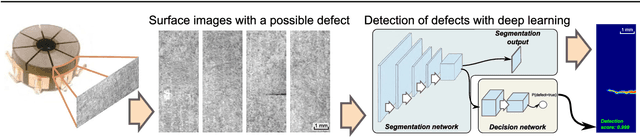


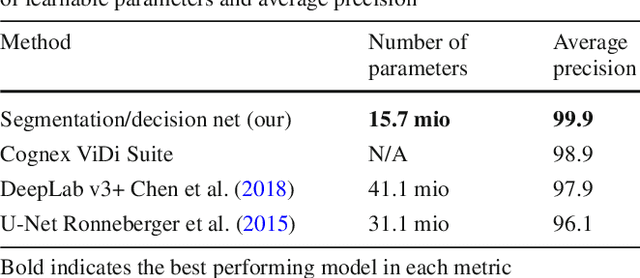
Automated surface-anomaly detection using machine learning has become an interesting and promising area of research, with a very high and direct impact on the application domain of visual inspection. Deep-learning methods have become the most suitable approaches for this task. They allow the inspection system to learn to detect the surface anomaly by simply showing it a number of exemplar images. This paper presents a segmentation-based deep-learning architecture that is designed for the detection and segmentation of surface anomalies and is demonstrated on a specific domain of surface-crack detection. The design of the architecture enables the model to be trained using a small number of samples, which is an important requirement for practical applications. The proposed model is compared with the related deep-learning methods, including the state-of-the-art commercial software, showing that the proposed approach outperforms the related methods on the domain of a surface-crack detection. The large number of experiments also shed light on the required precision of the annotation, the number of required training samples and on the required computational cost. Experiments are performed on a newly created dataset based on a real-world quality control case and demonstrate that the proposed approach is able to learn on a small number of defected surfaces, using only approximately 25-30 defective training samples, instead of hundreds or thousands, which is usually the case in deep-learning applications. This makes the deep-learning method practical for use in industry where the number of available defective samples is limited. The dataset is also made publicly available to encourage the development and evaluation of new methods for surface-defect detection.
Spatially-Adaptive Filter Units for Compact and Efficient Deep Neural Networks
Feb 20, 2019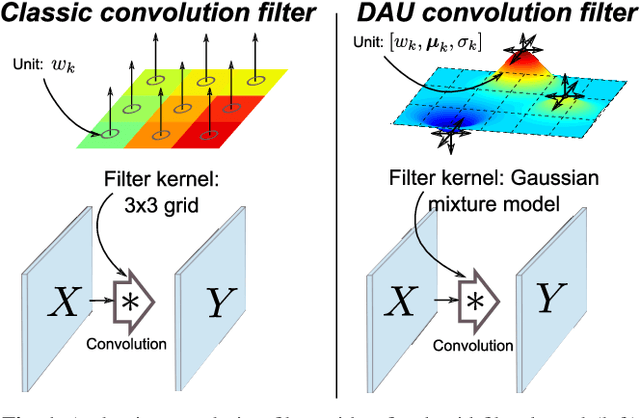

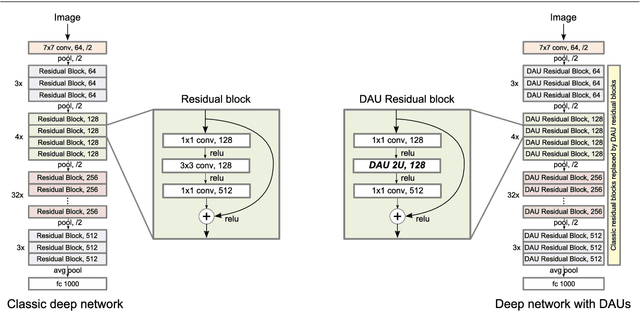

Convolutional neural networks excel in a number of computer vision tasks. One of their most crucial architectural elements is the effective receptive field size, that has to be manually set to accommodate a specific task. Standard solutions involve large kernels, down/up-sampling and dilated convolutions. These require testing a variety of dilation and down/up-sampling factors and result in non-compact representations and excessive number of parameters. We address this issue by proposing a new convolution filter composed of displaced aggregation units (DAU). DAUs learn spatial displacements and adapt the receptive field sizes of individual convolution filters to a given problem, thus eliminating the need for hand-crafted modifications. DAUs provide a seamless substitution of convolutional filters in existing state-of-the-art architectures, which we demonstrate on AlexNet, ResNet50, ResNet101, DeepLab and SRN-DeblurNet. The benefits of this design are demonstrated on a variety of computer vision tasks and datasets, such as image classification (ILSVRC 2012), semantic segmentation (PASCAL VOC 2011, Cityscape) and blind image de-blurring (GOPRO). Results show that DAUs efficiently allocate parameters resulting in up to four times more compact networks at similar or better performance.
Spatially-Adaptive Filter Units for Deep Neural Networks
Mar 15, 2018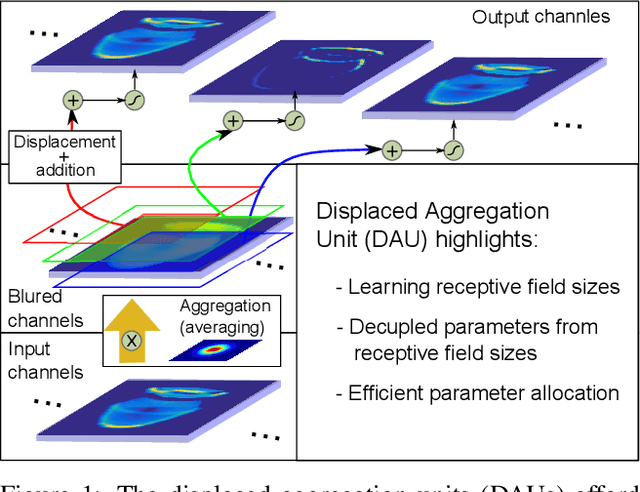
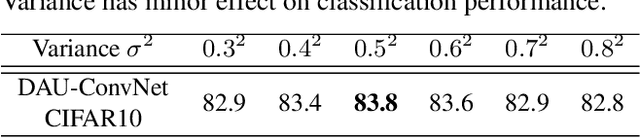

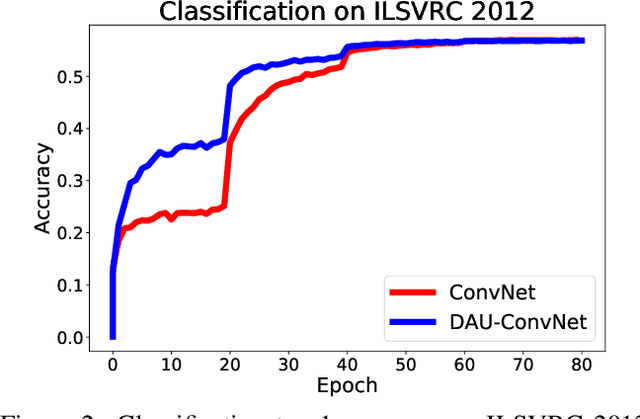
Classical deep convolutional networks increase receptive field size by either gradual resolution reduction or application of hand-crafted dilated convolutions to prevent increase in the number of parameters. In this paper we propose a novel displaced aggregation unit (DAU) that does not require hand-crafting. In contrast to classical filters with units (pixels) placed on a fixed regular grid, the displacement of the DAUs are learned, which enables filters to spatially-adapt their receptive field to a given problem. We extensively demonstrate the strength of DAUs on a classification and semantic segmentation tasks. Compared to ConvNets with regular filter, ConvNets with DAUs achieve comparable performance at faster convergence and up to 3-times reduction in parameters. Furthermore, DAUs allow us to study deep networks from novel perspectives. We study spatial distributions of DAU filters and analyze the number of parameters allocated for spatial coverage in a filter.
Towards Deep Compositional Networks
Sep 13, 2016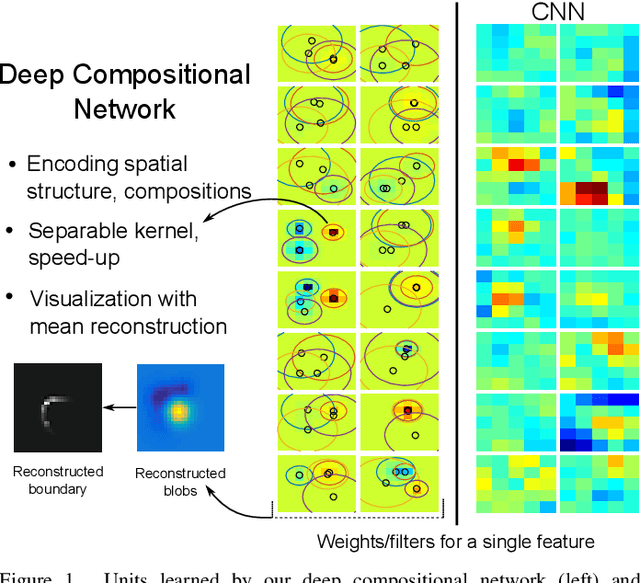

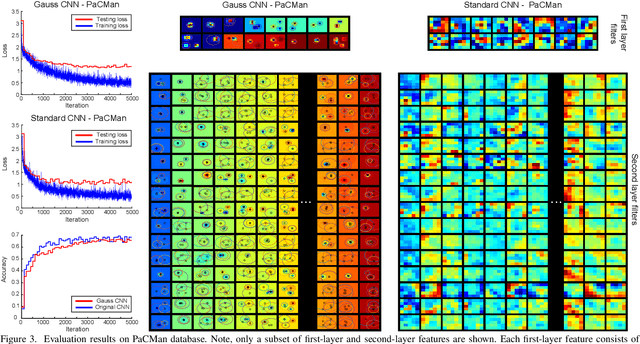
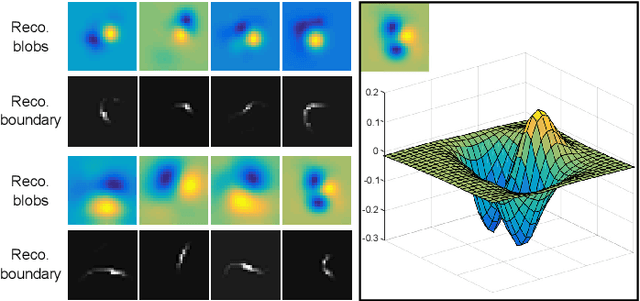
Hierarchical feature learning based on convolutional neural networks (CNN) has recently shown significant potential in various computer vision tasks. While allowing high-quality discriminative feature learning, the downside of CNNs is the lack of explicit structure in features, which often leads to overfitting, absence of reconstruction from partial observations and limited generative abilities. Explicit structure is inherent in hierarchical compositional models, however, these lack the ability to optimize a well-defined cost function. We propose a novel analytic model of a basic unit in a layered hierarchical model with both explicit compositional structure and a well-defined discriminative cost function. Our experiments on two datasets show that the proposed compositional model performs on a par with standard CNNs on discriminative tasks, while, due to explicit modeling of the structure in the feature units, affording a straight-forward visualization of parts and faster inference due to separability of the units. Actions