 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dexterous Grasping of Novel Objects from a Single View
Aug 10, 2019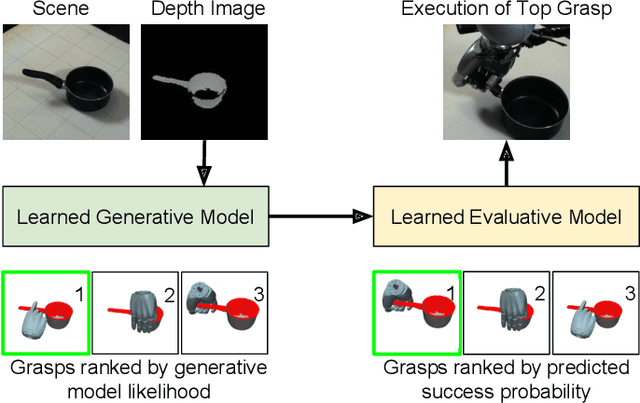



Dexterous grasping of a novel object given a single view is an open problem. This paper makes several contributions to its solution. First, we present a simulator for generating and testing dexterous grasps. Second we present a data set, generated by this simulator, of 2.4 million simulated dexterous grasps of variations of 294 base objects drawn from 20 categories. Third, we present a basic architecture for generation and evaluation of dexterous grasps that may be trained in a supervised manner. Fourth, we present three different evaluative architectures, employing ResNet-50 or VGG16 as their visual backbone. Fifth, we train, and evaluate seventeen variants of generative-evaluative architectures on this simulated data set, showing improvement from 69.53% grasp success rate to 90.49%. Finally, we present a real robot implementation and evaluate the four most promising variants, executing 196 real robot grasps in total. We show that our best architectural variant achieves a grasp success rate of 87.8% on real novel objects seen from a single view, improving on a baseline of 57.1%.
Learning better generative models for dexterous, single-view grasping of novel objects
Jul 13, 2019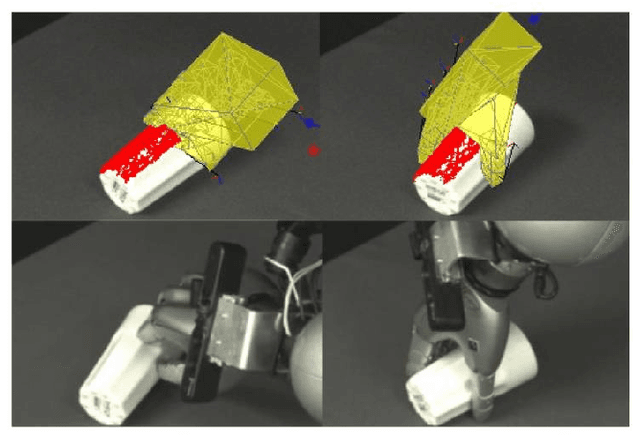


This paper concerns the problem of how to learn to grasp dexterously, so as to be able to then grasp novel objects seen only from a single view-point. Recently, progress has been made in data-efficient learning of generative grasp models which transfer well to novel objects. These generative grasp models are learned from demonstration (LfD). One weakness is that, as this paper shall show, grasp transfer under challenging single view conditions is unreliable. Second, the number of generative model elements rises linearly in the number of training examples. This, in turn, limits the potential of these generative models for generalisation and continual improvement. In this paper, it is shown how to address these problems. Several technical contributions are made: (i) a view-based model of a grasp; (ii) a method for combining and compressing multiple grasp models; (iii) a new way of evaluating contacts that is used both to generate and to score grasps. These, together, improve both grasp performance and reduce the number of models learned for grasp transfer. These advances, in turn, also allow the introduction of autonomous training, in which the robot learns from self-generated grasps. Evaluation on a challenging test set shows that, with innovations (i)-(iii) deployed, grasp transfer success rises from 55.1% to 81.6%. By adding autonomous training this rises to 87.8%. These differences are statistically significant. In total, across all experiments, 539 test grasps were executed on real objects.
Generative grasp synthesis from demonstration using parametric mixtures
Jun 27, 2019

We present a parametric formulation for learning generative models for grasp synthesis from a demonstration. We cast new light on this family of approaches, proposing a parametric formulation for grasp synthesis that is computationally faster compared to related work and indicates better grasp success rate performance in simulated experiments, showing a gain of at least 10% success rate (p < 0.05) in all the tested conditions. The proposed implementation is also able to incorporate arbitrary constraints for grasp ranking that may include task-specific constraints. Results are reported followed by a brief discussion on the merits of the proposed methods noted so far.
Hypothesis-based Belief Planning for Dexterous Grasping
Mar 13, 2019

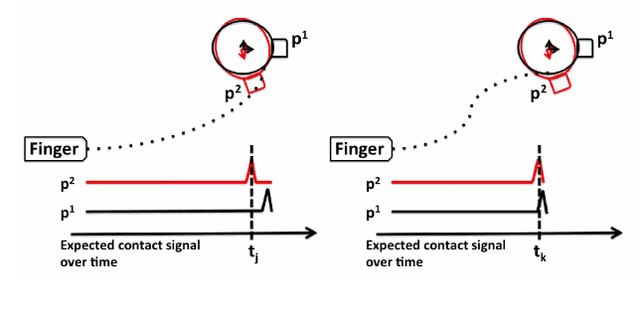

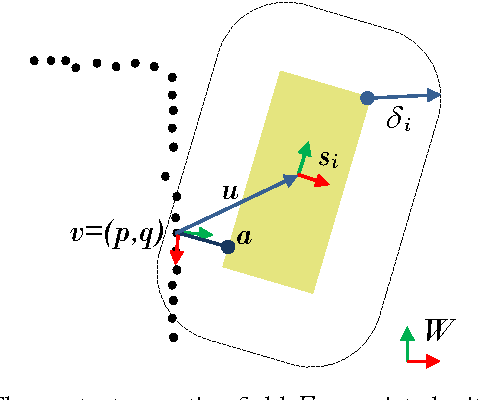
Belief space planning is a viable alternative to formalise partially observable control problems and, in the recent years, its application to robot manipulation problems has grown. However, this planning approach was tried successfully only on simplified control problems. In this paper, we apply belief space planning to the problem of planning dexterous reach-to-grasp trajectories under object pose uncertainty. In our framework, the robot perceives the object to be grasped on-the-fly as a point cloud and compute a full 6D, non-Gaussian distribution over the object's pose (our belief space). The system has no limitations on the geometry of the object, i.e., non-convex objects can be represented, nor assumes that the point cloud is a complete representation of the object. A plan in the belief space is then created to reach and grasp the object, such that the information value of expected contacts along the trajectory is maximised to compensate for the pose uncertainty. If an unexpected contact occurs when performing the action, such information is used to refine the pose distribution and triggers a re-planning. Experimental results show that our planner (IR3ne) improves grasp reliability and compensates for the pose uncertainty such that it doubles the proportion of grasps that succeed on a first attempt.
Learning and Inference of Dexterous Grasps for Novel Objects with Underactuated Hands
Sep 24, 2016

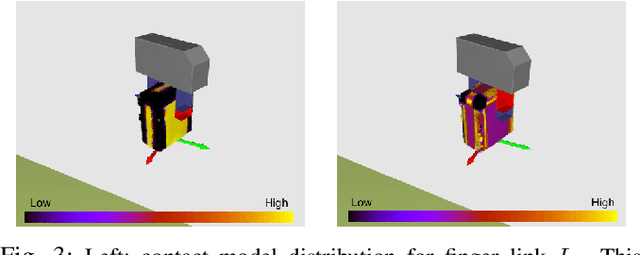
Recent advances have been made in learning of grasps for fully actuated hands. A typical approach learns the target locations of finger links on the object. When a new object must be grasped, new finger locations are generated, and a collision free reach-to-grasp trajectory is planned. This assumes a collision free trajectory to the final grasp. This is not possible with underactuated hands, which cannot be guaranteed to avoid contact, and in fact exploit contacts with the object during grasping, so as to reach an equilibrium state in which the object is held securely. Unfortunately, these contact interactions are i) not directly controllable, and ii) hard to monitor during a real grasp. We overcome these problems so as to permit learning of transferrable grasps for underactuated hands. We make two main technical innovations. First, we model contact interactions during the grasp implicitly. We do this by modelling motor commands that lead reliably to the equilibrium state, rather than modelling contact changes themselves. This alters our reach-to-grasp model. Second, we extend our contact model learning algorithm to work with multiple training examples for each grasp type. This requires the ability to learn which parts of the hand reliably interact with the object during a particular grasp. Our approach learns from a rigid body simulation. This enables us to learn how to approach the object and close the underactuated hand from a variety of poses. From nine training grasps on three objects the method transferred grasps to previously unseen, novel objects, that differ significantly from the training objects, with an 80% success rate.
Towards Deep Compositional Networks
Sep 13, 2016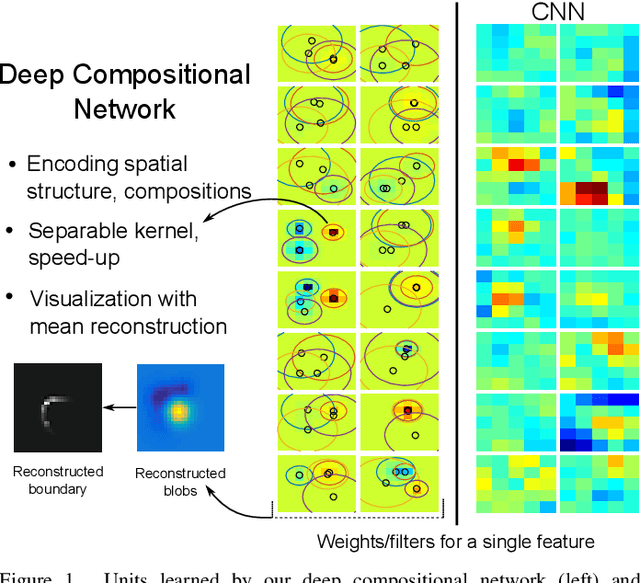

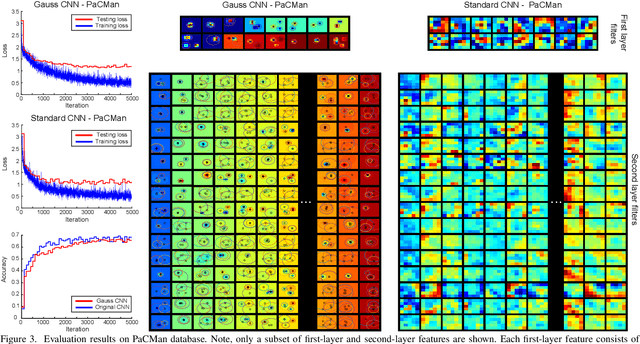
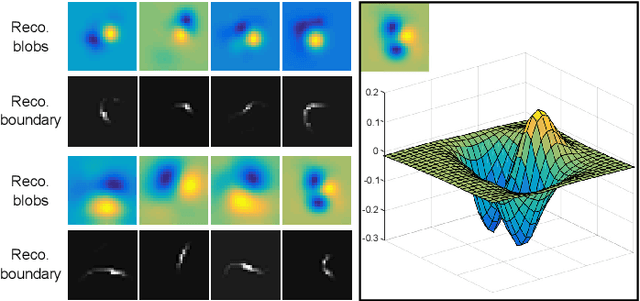
Hierarchical feature learning based on convolutional neural networks (CNN) has recently shown significant potential in various computer vision tasks. While allowing high-quality discriminative feature learning, the downside of CNNs is the lack of explicit structure in features, which often leads to overfitting, absence of reconstruction from partial observations and limited generative abilities. Explicit structure is inherent in hierarchical compositional models, however, these lack the ability to optimize a well-defined cost function. We propose a novel analytic model of a basic unit in a layered hierarchical model with both explicit compositional structure and a well-defined discriminative cost function. Our experiments on two datasets show that the proposed compositional model performs on a par with standard CNNs on discriminative tasks, while, due to explicit modeling of the structure in the feature units, affording a straight-forward visualization of parts and faster inference due to separability of the units. Actions
A Graph Theoretic Approach for Object Shape Representation in Compositional Hierarchies Using a Hybrid Generative-Descriptive Model
Jan 23, 2015



A graph theoretic approach is proposed for object shape representation in a hierarchical compositional architecture called Compositional Hierarchy of Parts (CHOP). In the proposed approach, vocabulary learning is performed using a hybrid generative-descriptive model. First, statistical relationships between parts are learned using a Minimum Conditional Entropy Clustering algorithm. Then, selection of descriptive parts is defined as a frequent subgraph discovery problem, and solved using a Minimum Description Length (MDL) principle. Finally, part compositions are constructed by compressing the internal data representation with discovered substructures. Shape representation and computational complexity properties of the proposed approach and algorithms are examined using six benchmark two-dimensional shape image datasets. Experiments show that CHOP can employ part shareability and indexing mechanisms for fast inference of part compositions using learned shape vocabularies. Additionally, CHOP provides better shape retrieval performance than the state-of-the-art shape retrieval methods.