 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning better generative models for dexterous, single-view grasping of novel objects
Paper and Code
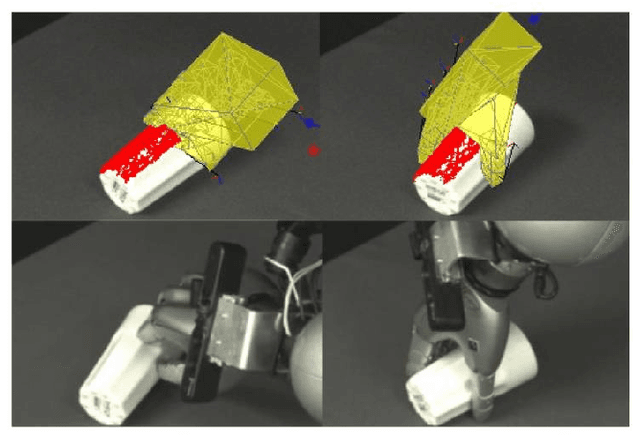
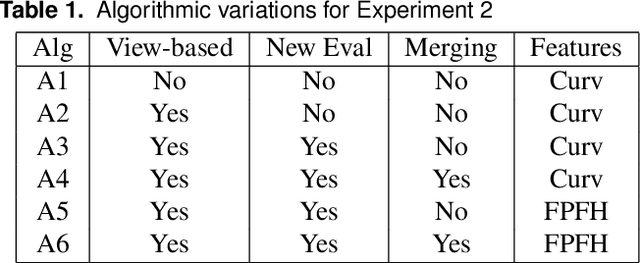


This paper concerns the problem of how to learn to grasp dexterously, so as to be able to then grasp novel objects seen only from a single view-point. Recently, progress has been made in data-efficient learning of generative grasp models which transfer well to novel objects. These generative grasp models are learned from demonstration (LfD). One weakness is that, as this paper shall show, grasp transfer under challenging single view conditions is unreliable. Second, the number of generative model elements rises linearly in the number of training examples. This, in turn, limits the potential of these generative models for generalisation and continual improvement. In this paper, it is shown how to address these problems. Several technical contributions are made: (i) a view-based model of a grasp; (ii) a method for combining and compressing multiple grasp models; (iii) a new way of evaluating contacts that is used both to generate and to score grasps. These, together, improve both grasp performance and reduce the number of models learned for grasp transfer. These advances, in turn, also allow the introduction of autonomous training, in which the robot learns from self-generated grasps. Evaluation on a challenging test set shows that, with innovations (i)-(iii) deployed, grasp transfer success rises from 55.1% to 81.6%. By adding autonomous training this rises to 87.8%. These differences are statistically significant. In total, across all experiments, 539 test grasps were executed on real objects.