 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRIS: Intersection-aware Ray-based Implicit Editable Scenes
Mar 16, 2026Neural Radiance Fields achieve high-fidelity scene representation but suffer from costly training and rendering, while 3D Gaussian splatting offers real-time performance with strong empirical results. Recently, solutions that harness the best of both worlds by using Gaussians as proxies to guide neural field evaluations, still suffer from significant computational inefficiencies. They typically rely on stochastic volumetric sampling to aggregate features, which severely limits rendering performance. To address this issue, a novel framework named IRIS (Intersection-aware Ray-based Implicit Editable Scenes) is introduced as a method designed for efficient and interactive scene editing. To overcome the limitations of standard ray marching, an analytical sampling strategy is employed that precisely identifies interaction points between rays and scene primitives, effectively eliminating empty space processing. Furthermore, to address the computational bottleneck of spatial neighbor lookups, a continuous feature aggregation mechanism is introduced that operates directly along the ray. By interpolating latent attributes from sorted intersections, costly 3D searches are bypassed, ensuring geometric consistency, enabling high-fidelity, real-time rendering, and flexible shape editing. Code can be found at https://github.com/gwilczynski95/iris.
Pointy - A Lightweight Transformer for Point Cloud Foundation Models
Mar 11, 2026Foundation models for point cloud data have recently grown in capability, often leveraging extensive representation learning from language or vision. In this work, we take a more controlled approach by introducing a lightweight transformer-based point cloud architecture. In contrast to the heavy reliance on cross-modal supervision, our model is trained only on 39k point clouds - yet it outperforms several larger foundation models trained on over 200k training samples. Interestingly, our method approaches state-of-the-art results from models that have seen over a million point clouds, images, and text samples, demonstrating the value of a carefully curated training setup and architecture. To ensure rigorous evaluation, we conduct a comprehensive replication study that standardizes the training regime and benchmarks across multiple point cloud architectures. This unified experimental framework isolates the impact of architectural choices, allowing for transparent comparisons and highlighting the benefits of our design and other tokenizer-free architectures. Our results show that simple backbones can deliver competitive results to more complex or data-rich strategies. The implementation, including code, pre-trained models, and training protocols, is available at https://github.com/KonradSzafer/Pointy.
Keyframe-based Dense Mapping with the Graph of View-Dependent Local Maps
Jan 13, 2026In this article, we propose a new keyframe-based mapping system. The proposed method updates local Normal Distribution Transform maps (NDT) using data from an RGB-D sensor. The cells of the NDT are stored in 2D view-dependent structures to better utilize the properties and uncertainty model of RGB-D cameras. This method naturally represents an object closer to the camera origin with higher precision. The local maps are stored in the pose graph which allows correcting global map after loop closure detection. We also propose a procedure that allows merging and filtering local maps to obtain a global map of the environment. Finally, we compare our method with Octomap and NDT-OM and provide example applications of the proposed mapping method.
Improving Machine Learning-Based Robot Self-Collision Checking with Input Positional Encoding
Sep 10, 2025



This manuscript investigates the integration of positional encoding -- a technique widely used in computer graphics -- into the input vector of a binary classification model for self-collision detection. The results demonstrate the benefits of incorporating positional encoding, which enhances classification accuracy by enabling the model to better capture high-frequency variations, leading to a more detailed and precise representation of complex collision patterns. The manuscript shows that machine learning-based techniques, such as lightweight multilayer perceptrons (MLPs) operating in a low-dimensional feature space, offer a faster alternative for collision checking than traditional methods that rely on geometric approaches, such as triangle-to-triangle intersection tests and Bounding Volume Hierarchies (BVH) for mesh-based models.
3D Reconstruction of non-visible surfaces of objects from a Single Depth View -- Comparative Study
Jan 27, 2025


Scene and object reconstruction is an important problem in robotics, in particular in planning collision-free trajectories or in object manipulation. This paper compares two strategies for the reconstruction of nonvisible parts of the object surface from a single RGB-D camera view. The first method, named DeepSDF predicts the Signed Distance Transform to the object surface for a given point in 3D space. The second method, named MirrorNet reconstructs the occluded objects' parts by generating images from the other side of the observed object. Experiments performed with objects from the ShapeNet dataset, show that the view-dependent MirrorNet is faster and has smaller reconstruction errors in most categories.
Informed Guided Rapidly-Exploring Random Trees*-Connect for Path Planning of Walking Robots
Mar 06, 2023
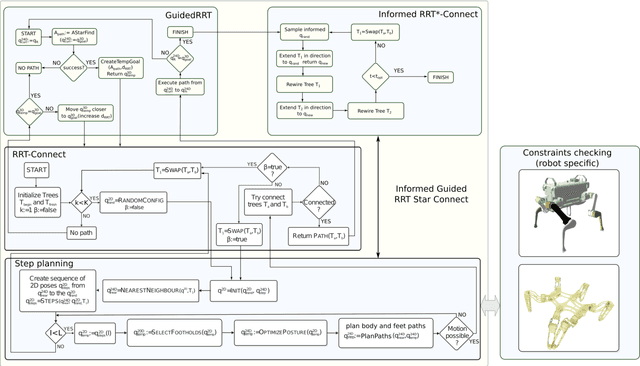
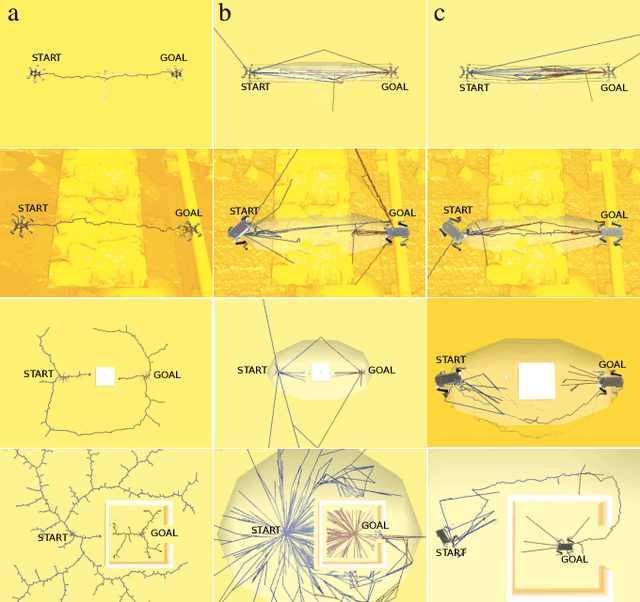
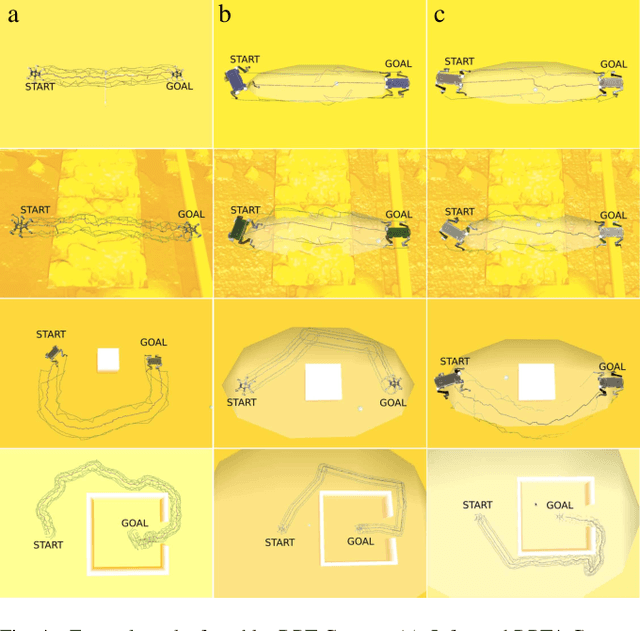
In this paper, we deal with the problem of full-body path planning for walking robots. The state of walking robots is defined in multi-dimensional space. Path planning requires defining the path of the feet and the robot's body. Moreover, the planner should check multiple constraints like static stability, self-collisions, collisions with the terrain, and the legs' workspace. As a result, checking the feasibility of the potential path is time-consuming and influences the performance of a planning method. In this paper, we verify the feasibility of sampling-based planners in the path planning task of walking robots. We identify the strengths and weaknesses of the existing planners. Finally, we propose a new planning method that improves the performance of path planning of legged robots.
Learning better generative models for dexterous, single-view grasping of novel objects
Jul 13, 2019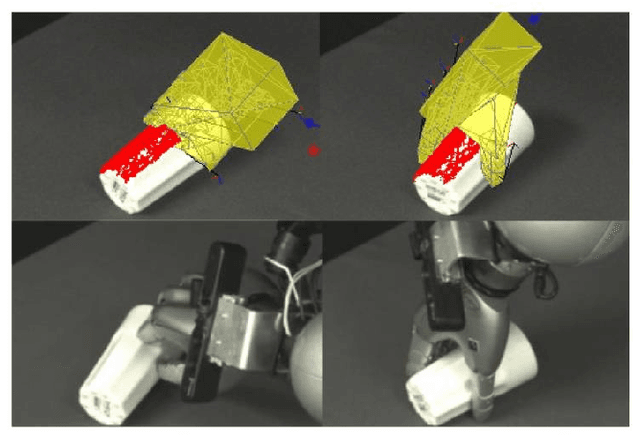


This paper concerns the problem of how to learn to grasp dexterously, so as to be able to then grasp novel objects seen only from a single view-point. Recently, progress has been made in data-efficient learning of generative grasp models which transfer well to novel objects. These generative grasp models are learned from demonstration (LfD). One weakness is that, as this paper shall show, grasp transfer under challenging single view conditions is unreliable. Second, the number of generative model elements rises linearly in the number of training examples. This, in turn, limits the potential of these generative models for generalisation and continual improvement. In this paper, it is shown how to address these problems. Several technical contributions are made: (i) a view-based model of a grasp; (ii) a method for combining and compressing multiple grasp models; (iii) a new way of evaluating contacts that is used both to generate and to score grasps. These, together, improve both grasp performance and reduce the number of models learned for grasp transfer. These advances, in turn, also allow the introduction of autonomous training, in which the robot learns from self-generated grasps. Evaluation on a challenging test set shows that, with innovations (i)-(iii) deployed, grasp transfer success rises from 55.1% to 81.6%. By adding autonomous training this rises to 87.8%. These differences are statistically significant. In total, across all experiments, 539 test grasps were executed on real objects.
Generate What You Can't See - a View-dependent Image Generation
Mar 15, 2019

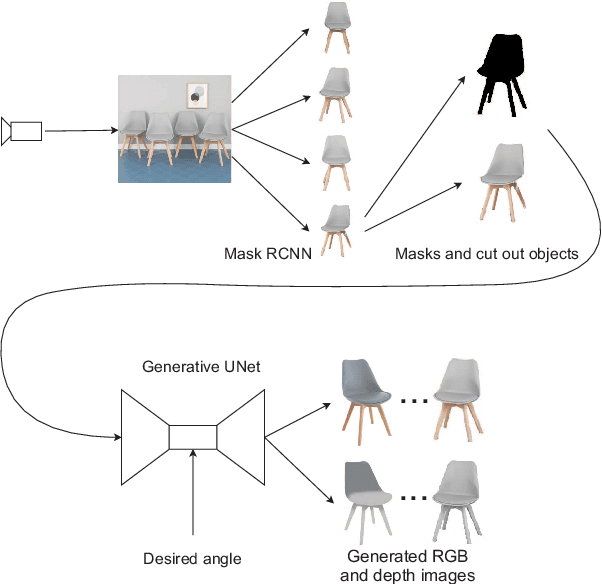
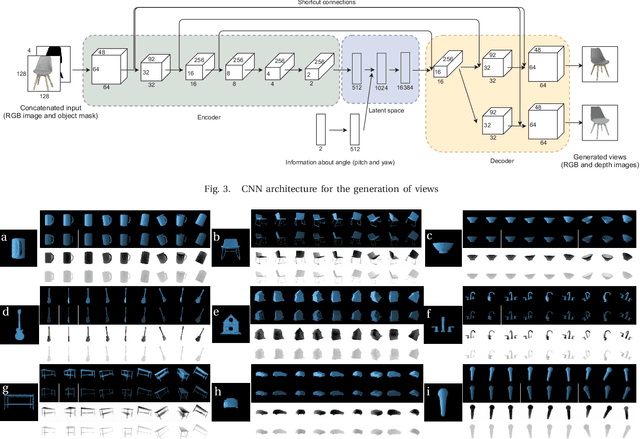
In order to operate autonomously, a robot should explore the environment and build a model of each of the surrounding objects. A common approach is to carefully scan the whole workspace. This is time-consuming. It is also often impossible to reach all the viewpoints required to acquire full knowledge about the environment. Humans can perform shape completion of occluded objects by relying on past experience. Therefore, we propose a method that generates images of an object from various viewpoints using a single input RGB image. A deep neural network is trained to imagine the object appearance from many viewpoints. We present the whole pipeline, which takes a single RGB image as input and returns a sequence of RGB and depth images of the object. The method utilizes a CNN-based object detector to extract the object from the natural scene. Then, the proposed network generates a set of RGB and depth images. We show the results both on a synthetic dataset and on real images.