 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Low-Latency Speech Enhancement with Mobile Audio Streaming Networks
Aug 17, 2020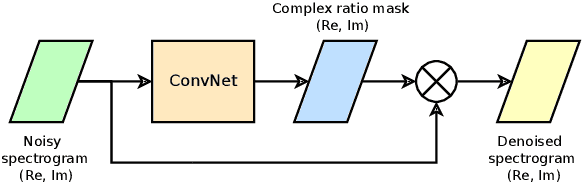
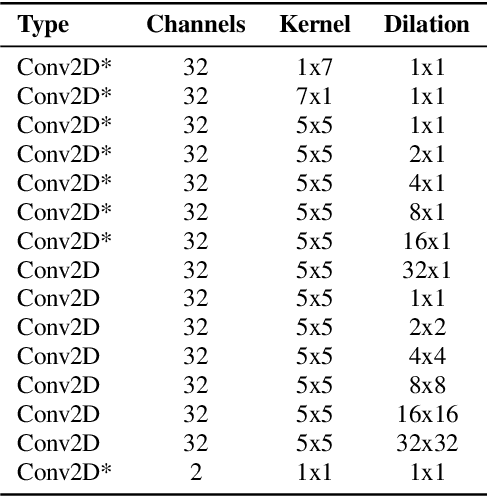
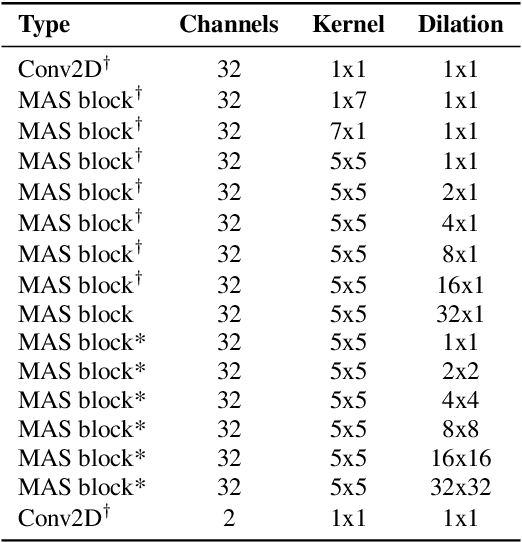
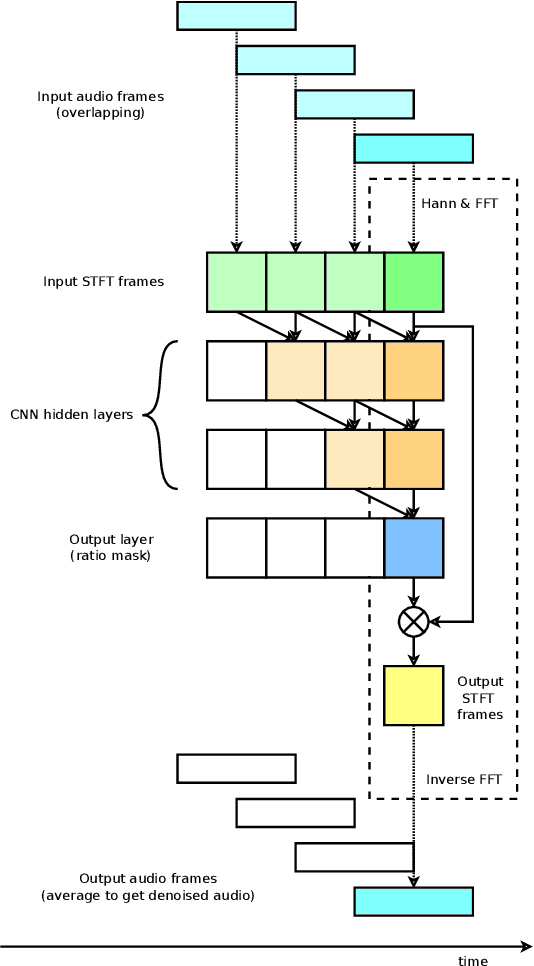
We propose Mobile Audio Streaming Networks (MASnet) for efficient low-latency speech enhancement, which is particularly suitable for mobile devices and other applications where computational capacity is a limitation. MASnet processes linear-scale spectrograms, transforming successive noisy frames into complex-valued ratio masks which are then applied to the respective noisy frames. MASnet can operate in a low-latency incremental inference mode which matches the complexity of layer-by-layer batch mode. Compared to a similar fully-convolutional architecture, MASnet incorporates depthwise and pointwise convolutions for a large reduction in fused multiply-accumulate operations per second (FMA/s), at the cost of some reduction in SNR.
StoRIR: Stochastic Room Impulse Response Generation for Audio Data Augmentation
Aug 17, 2020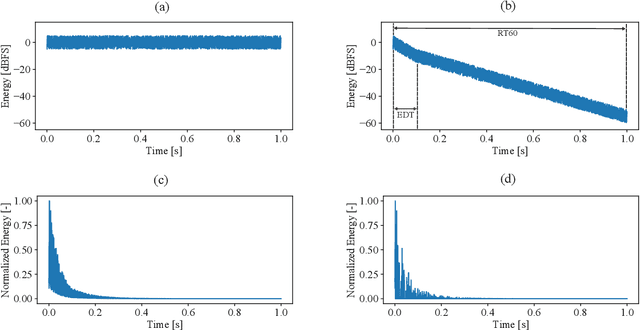
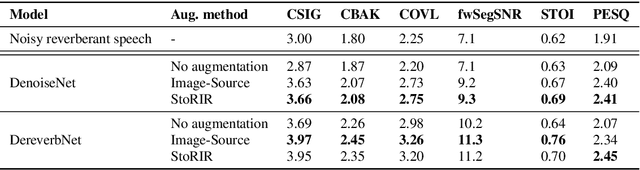
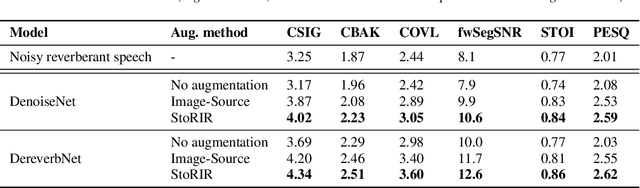
In this paper we introduce StoRIR - a stochastic room impulse response generation method dedicated to audio data augmentation in machine learning applications. This technique, in contrary to geometrical methods like image-source or ray tracing, does not require prior definition of room geometry, absorption coefficients or microphone and source placement and is dependent solely on the acoustic parameters of the room. The method is intuitive, easy to implement and allows to generate RIRs of very complicated enclosures. We show that StoRIR, when used for audio data augmentation in a speech enhancement task, allows deep learning models to achieve better results on a wide range of metrics than when using the conventional image-source method, effectively improving many of them by more than 5 %. We publish a Python implementation of StoRIR online
Generate What You Can't See - a View-dependent Image Generation
Mar 15, 2019

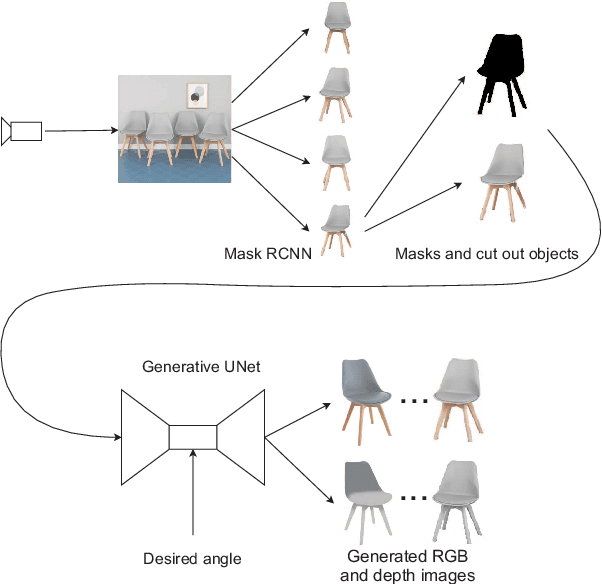
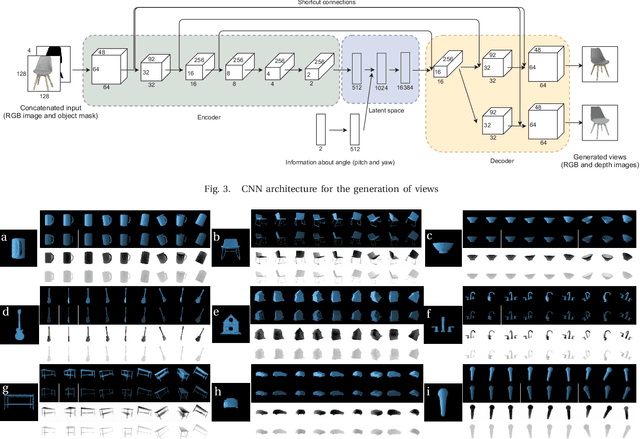
In order to operate autonomously, a robot should explore the environment and build a model of each of the surrounding objects. A common approach is to carefully scan the whole workspace. This is time-consuming. It is also often impossible to reach all the viewpoints required to acquire full knowledge about the environment. Humans can perform shape completion of occluded objects by relying on past experience. Therefore, we propose a method that generates images of an object from various viewpoints using a single input RGB image. A deep neural network is trained to imagine the object appearance from many viewpoints. We present the whole pipeline, which takes a single RGB image as input and returns a sequence of RGB and depth images of the object. The method utilizes a CNN-based object detector to extract the object from the natural scene. Then, the proposed network generates a set of RGB and depth images. We show the results both on a synthetic dataset and on real images.
Ain't Nobody Got Time For Coding: Structure-Aware Program Synthesis From Natural Language
Oct 23, 2018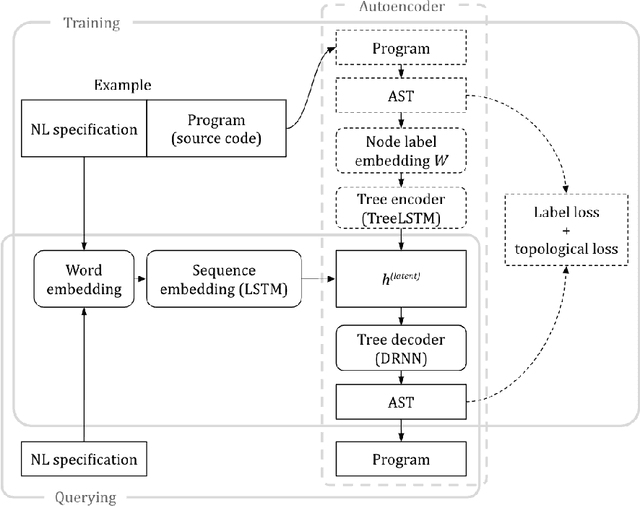


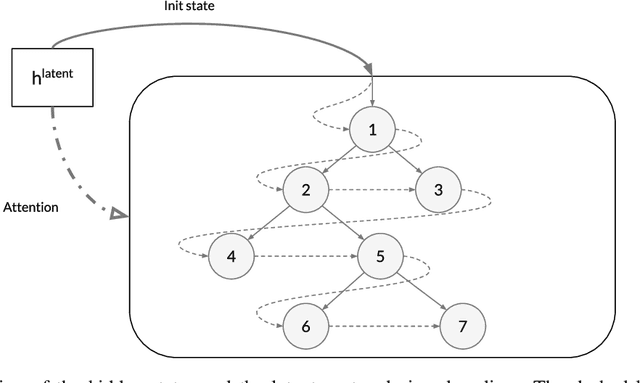
Program synthesis from natural language (NL) is practical for humans and, once technically feasible, would significantly facilitate software development and revolutionize end-user programming. We present SAPS, an end-to-end neural network capable of mapping relatively complex, multi-sentence NL specifications to snippets of executable code. The proposed architecture relies exclusively on neural components, and is built upon a tree2tree autoencoder trained on abstract syntax trees, combined with a pretrained word embedding and a bi-directional multi-layer LSTM for NL processing. The decoder features a doubly-recurrent LSTM with a novel signal propagation scheme and soft attention mechanism. When applied to a large dataset of problems proposed in a previous study, SAPS performs on par with or better than the method proposed there, producing correct programs in over 90% of cases. In contrast to other methods, it does not involve any non-neural components to post-process the resulting programs, and uses a fixed-dimensional latent representation as the only link between the NL analyzer and source code generator.