Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Low-Latency Speech Enhancement with Mobile Audio Streaming Networks
Paper and Code
Aug 17, 2020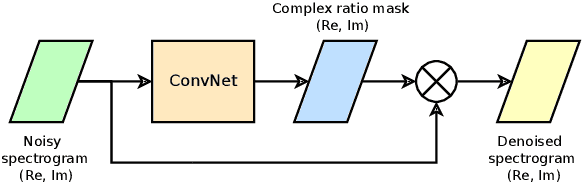
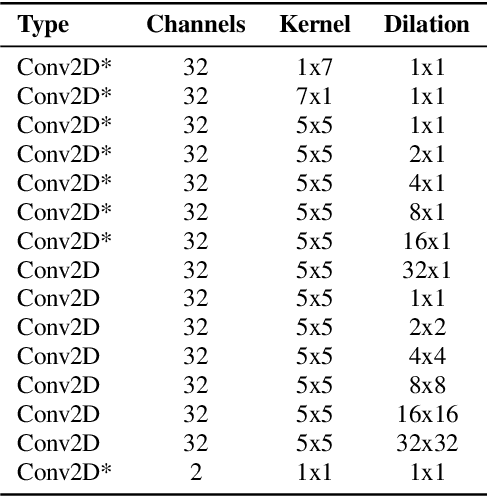
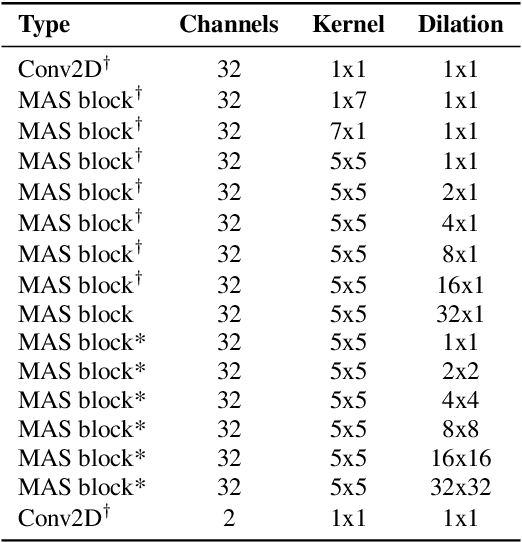
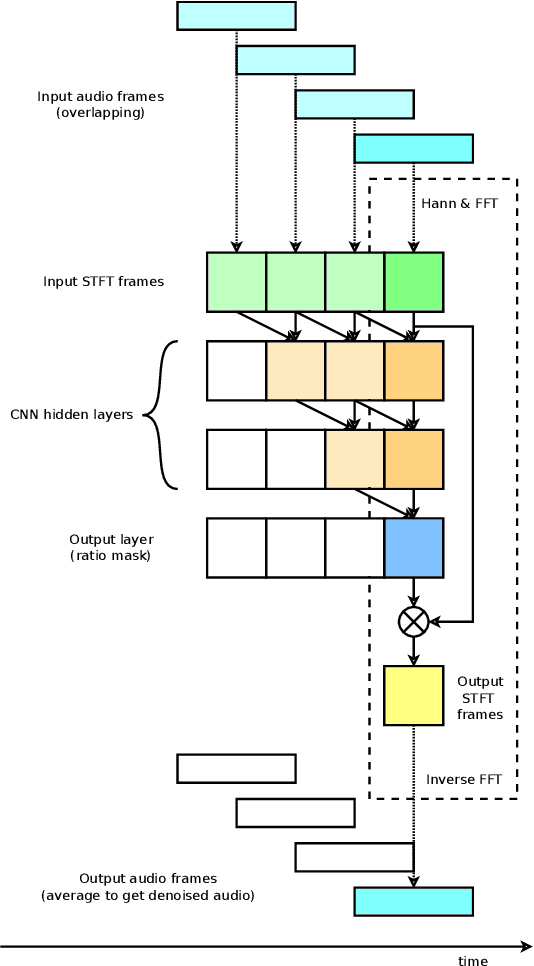
We propose Mobile Audio Streaming Networks (MASnet) for efficient low-latency speech enhancement, which is particularly suitable for mobile devices and other applications where computational capacity is a limitation. MASnet processes linear-scale spectrograms, transforming successive noisy frames into complex-valued ratio masks which are then applied to the respective noisy frames. MASnet can operate in a low-latency incremental inference mode which matches the complexity of layer-by-layer batch mode. Compared to a similar fully-convolutional architecture, MASnet incorporates depthwise and pointwise convolutions for a large reduction in fused multiply-accumulate operations per second (FMA/s), at the cost of some reduction in SNR.
* Accepted for INTERSPEECH 2020
View paper on