 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-based hard negative sampling for supervised contrastive speaker verification
Jul 23, 2025In speaker verification, contrastive learning is gaining popularity as an alternative to the traditionally used classification-based approaches. Contrastive methods can benefit from an effective use of hard negative pairs, which are different-class samples particularly challenging for a verification model due to their similarity. In this paper, we propose CHNS - a clustering-based hard negative sampling method, dedicated for supervised contrastive speaker representation learning. Our approach clusters embeddings of similar speakers, and adjusts batch composition to obtain an optimal ratio of hard and easy negatives during contrastive loss calculation. Experimental evaluation shows that CHNS outperforms a baseline supervised contrastive approach with and without loss-based hard negative sampling, as well as a state-of-the-art classification-based approach to speaker verification by as much as 18 % relative EER and minDCF on the VoxCeleb dataset using two lightweight model architectures.
Efficient Low-Latency Speech Enhancement with Mobile Audio Streaming Networks
Aug 17, 2020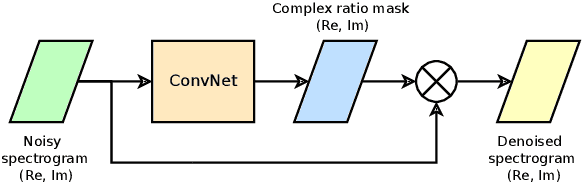
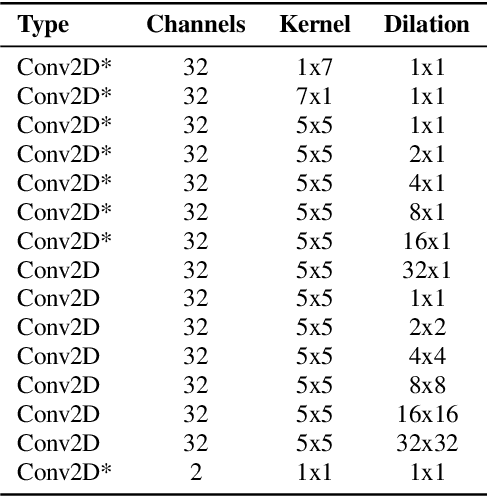
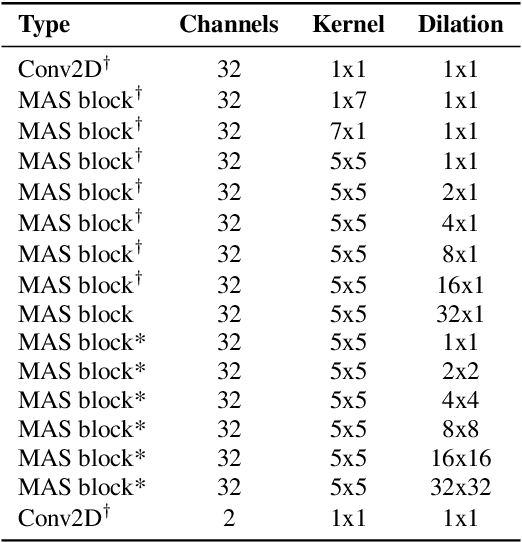
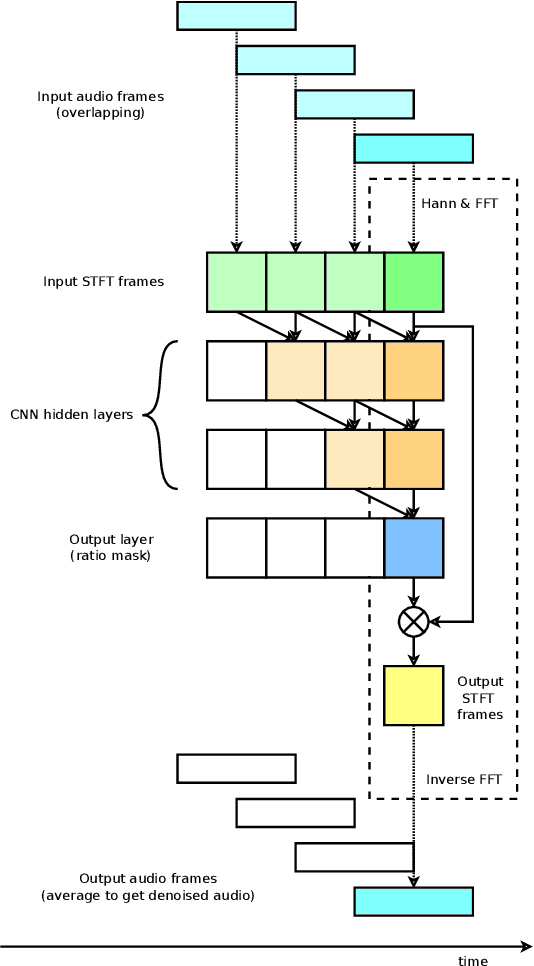
We propose Mobile Audio Streaming Networks (MASnet) for efficient low-latency speech enhancement, which is particularly suitable for mobile devices and other applications where computational capacity is a limitation. MASnet processes linear-scale spectrograms, transforming successive noisy frames into complex-valued ratio masks which are then applied to the respective noisy frames. MASnet can operate in a low-latency incremental inference mode which matches the complexity of layer-by-layer batch mode. Compared to a similar fully-convolutional architecture, MASnet incorporates depthwise and pointwise convolutions for a large reduction in fused multiply-accumulate operations per second (FMA/s), at the cost of some reduction in SNR.
StoRIR: Stochastic Room Impulse Response Generation for Audio Data Augmentation
Aug 17, 2020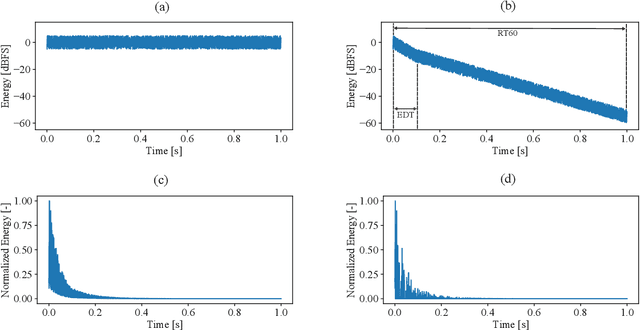
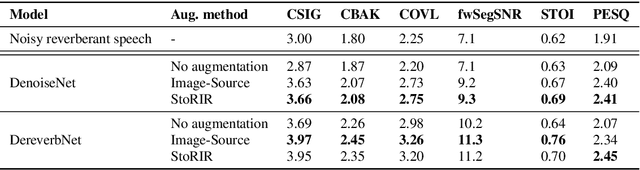
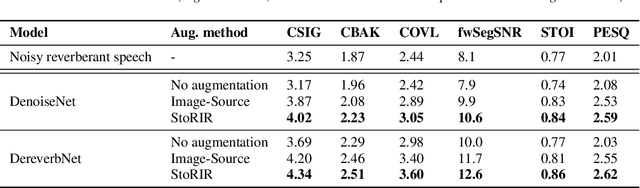
In this paper we introduce StoRIR - a stochastic room impulse response generation method dedicated to audio data augmentation in machine learning applications. This technique, in contrary to geometrical methods like image-source or ray tracing, does not require prior definition of room geometry, absorption coefficients or microphone and source placement and is dependent solely on the acoustic parameters of the room. The method is intuitive, easy to implement and allows to generate RIRs of very complicated enclosures. We show that StoRIR, when used for audio data augmentation in a speech enhancement task, allows deep learning models to achieve better results on a wide range of metrics than when using the conventional image-source method, effectively improving many of them by more than 5 %. We publish a Python implementation of StoRIR online