 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoRIR: Stochastic Room Impulse Response Generation for Audio Data Augmentation
Paper and Code
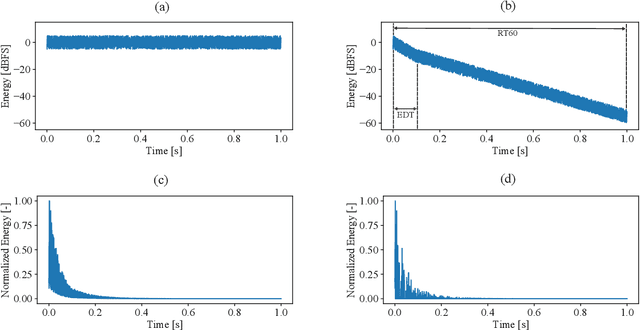
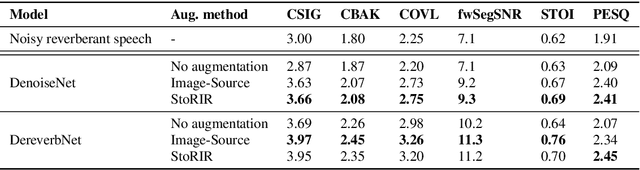
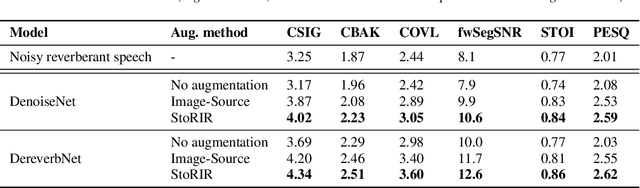
In this paper we introduce StoRIR - a stochastic room impulse response generation method dedicated to audio data augmentation in machine learning applications. This technique, in contrary to geometrical methods like image-source or ray tracing, does not require prior definition of room geometry, absorption coefficients or microphone and source placement and is dependent solely on the acoustic parameters of the room. The method is intuitive, easy to implement and allows to generate RIRs of very complicated enclosures. We show that StoRIR, when used for audio data augmentation in a speech enhancement task, allows deep learning models to achieve better results on a wide range of metrics than when using the conventional image-source method, effectively improving many of them by more than 5 %. We publish a Python implementation of StoRIR online