 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Multi-Modal Artist-Controlled Retrieval and Exploration of 3D Object Sets
Sep 01, 2022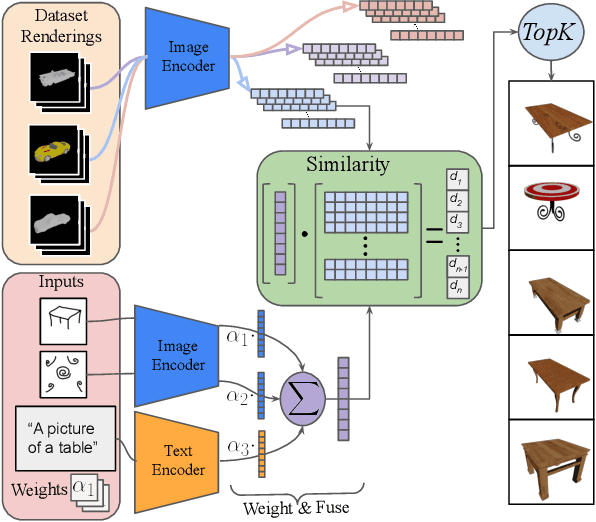

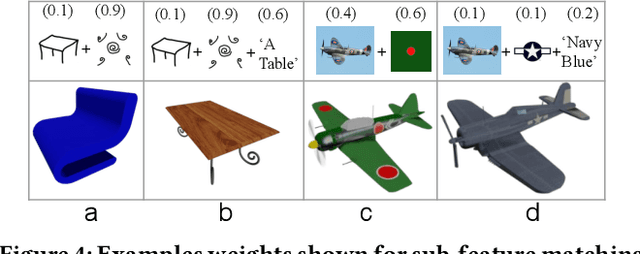
When creating 3D content, highly specialized skills are generally needed to design and generate models of objects and other assets by hand. We address this problem through high-quality 3D asset retrieval from multi-modal inputs, including 2D sketches, images and text. We use CLIP as it provides a bridge to higher-level latent features. We use these features to perform a multi-modality fusion to address the lack of artistic control that affects common data-driven approaches. Our approach allows for multi-modal conditional feature-driven retrieval through a 3D asset database, by utilizing a combination of input latent embeddings. We explore the effects of different combinations of feature embeddings across different input types and weighting methods.
Object Handovers: a Review for Robotics
Jul 25, 2020
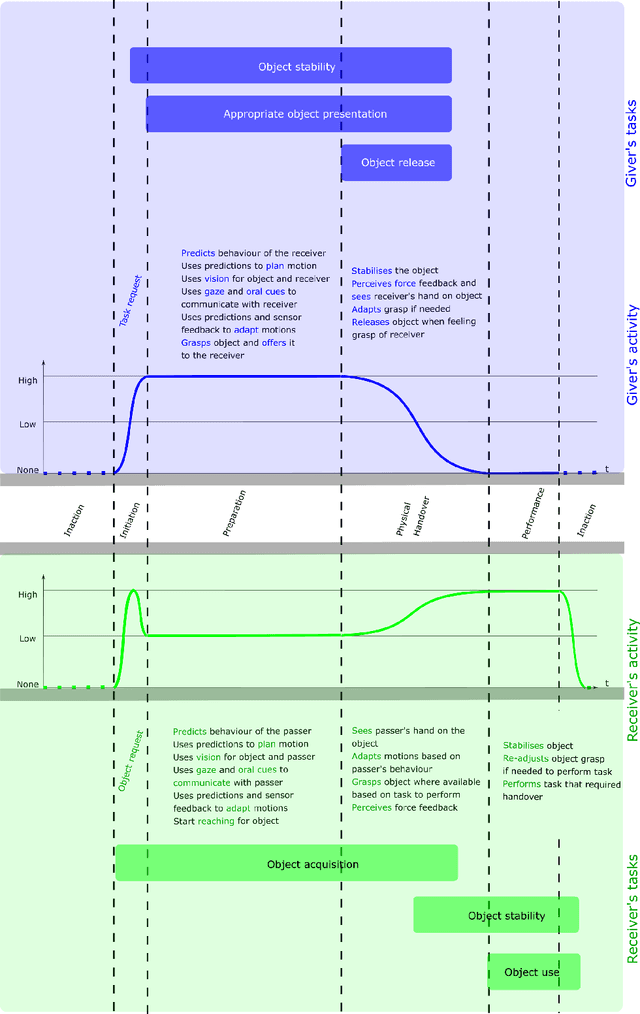
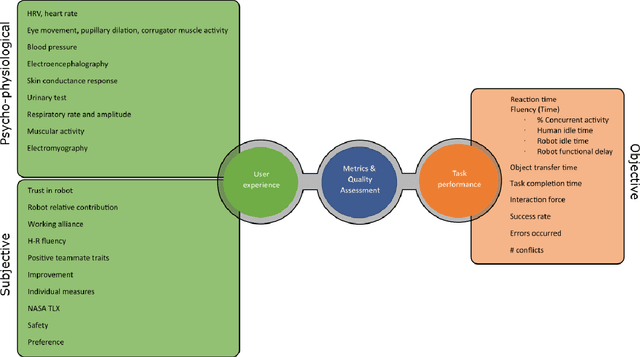
This article surveys the literature on human-robot object handovers. A handover is a collaborative joint action where an agent, the giver, gives an object to another agent, the receiver. The physical exchange starts when the receiver first contacts the object held by the giver and ends when the giver fully releases the object to the receiver. However, important cognitive and physical processes begin before the physical exchange, including initiating implicit agreement with respect to the location and timing of the exchange. From this perspective, we structure our review into the two main phases delimited by the aforementioned events: 1) a pre-handover phase, and 2) the physical exchange. We focus our analysis on the two actors (giver and receiver) and report the state of the art of robotic givers (robot-to-human handovers) and the robotic receivers (human-to-robot handovers). We report a comprehensive list of qualitative and quantitative metrics commonly used to assess the interaction. While focusing our review on the cognitive level (e.g., prediction, perception, motion planning, learning) and the physical level (e.g., motion, grasping, grip release) of the handover, we briefly discuss also the concepts of safety, social context, and ergonomics. We compare the behaviours displayed during human-to-human handovers to the state of the art of robotic assistants, and identify the major areas of improvement for robotic assistants to reach performance comparable to human interactions. Finally, we propose a minimal set of metrics that should be used in order to enable a fair comparison among the approaches.
Object-Independent Human-to-Robot Handovers using Real Time Robotic Vision
Jun 02, 2020
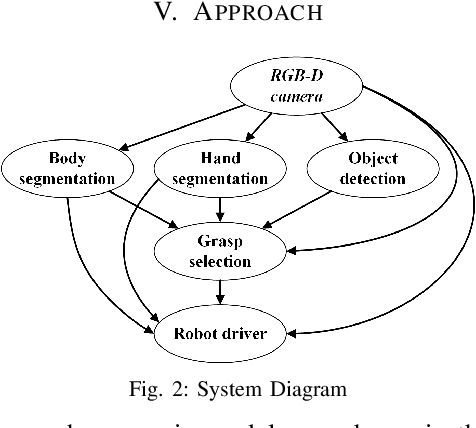
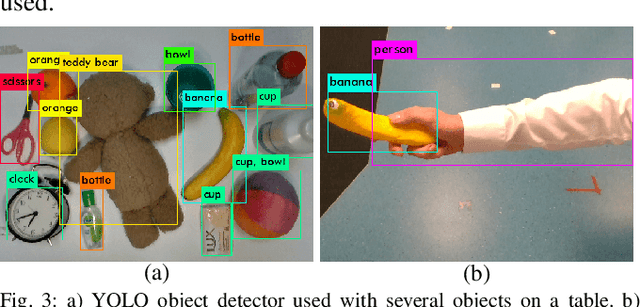

We present an approach for safe and object-independent human-to-robot handovers using real time robotic vision and manipulation. We aim for general applicability with a generic object detector, a fast grasp selection algorithm and by using a single gripper-mounted RGB-D camera, hence not relying on external sensors. The robot is controlled via visual servoing towards the object of interest. Putting a high emphasis on safety, we use two perception modules: human body part segmentation and hand/finger segmentation. Pixels that are deemed to belong to the human are filtered out from candidate grasp poses, hence ensuring that the robot safely picks the object without colliding with the human partner. The grasp selection and perception modules run concurrently in real-time, which allows monitoring of the progress. In experiments with 13 objects, the robot was able to successfully take the object from the human in 81.9% of the trials.
Model-free vision-based shaping of deformable plastic materials
Jan 30, 2020


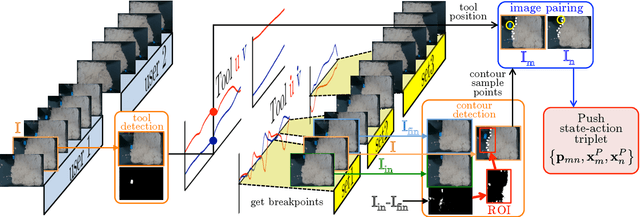
We address the problem of shaping deformable plastic materials using non-prehensile actions. Shaping plastic objects is challenging, since they are difficult to model and to track visually. We study this problem, by using kinetic sand, a plastic toy material which mimics the physical properties of wet sand. Inspired by a pilot study where humans shape kinetic sand, we define two types of actions: \textit{pushing} the material from the sides and \textit{tapping} from above. The chosen actions are executed with a robotic arm using image-based visual servoing. From the current and desired view of the material, we define states based on visual features such as the outer contour shape and the pixel luminosity values. These are mapped to actions, which are repeated iteratively to reduce the image error until convergence is reached. For pushing, we propose three methods for mapping the visual state to an action. These include heuristic methods and a neural network, trained from human actions. We show that it is possible to obtain simple shapes with the kinetic sand, without explicitly modeling the material. Our approach is limited in the types of shapes it can achieve. A richer set of action types and multi-step reasoning is needed to achieve more sophisticated shapes.
Hypothesis-based Belief Planning for Dexterous Grasping
Mar 13, 2019

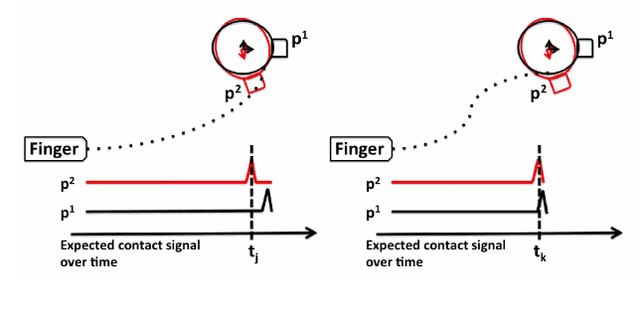

Belief space planning is a viable alternative to formalise partially observable control problems and, in the recent years, its application to robot manipulation problems has grown. However, this planning approach was tried successfully only on simplified control problems. In this paper, we apply belief space planning to the problem of planning dexterous reach-to-grasp trajectories under object pose uncertainty. In our framework, the robot perceives the object to be grasped on-the-fly as a point cloud and compute a full 6D, non-Gaussian distribution over the object's pose (our belief space). The system has no limitations on the geometry of the object, i.e., non-convex objects can be represented, nor assumes that the point cloud is a complete representation of the object. A plan in the belief space is then created to reach and grasp the object, such that the information value of expected contacts along the trajectory is maximised to compensate for the pose uncertainty. If an unexpected contact occurs when performing the action, such information is used to refine the pose distribution and triggers a re-planning. Experimental results show that our planner (IR3ne) improves grasp reliability and compensates for the pose uncertainty such that it doubles the proportion of grasps that succeed on a first attempt.