 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Multi-Modal Artist-Controlled Retrieval and Exploration of 3D Object Sets
Sep 01, 2022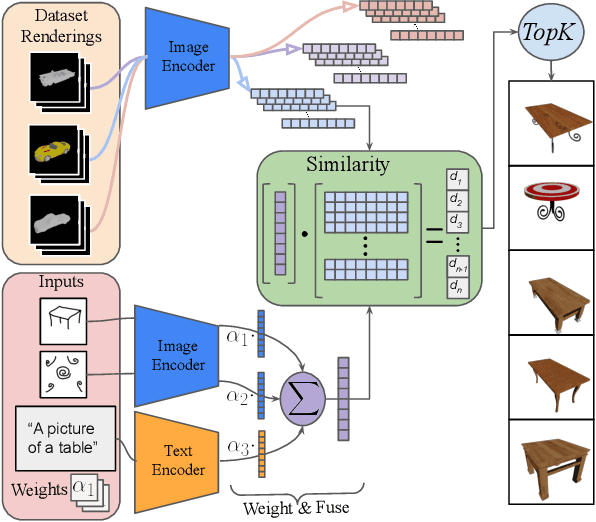

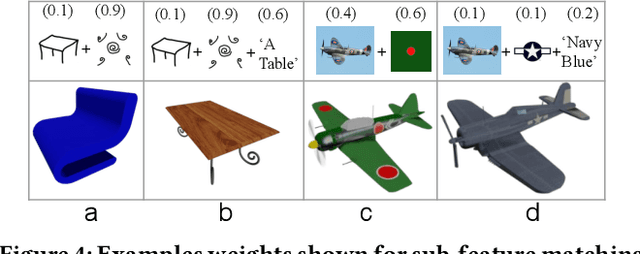
When creating 3D content, highly specialized skills are generally needed to design and generate models of objects and other assets by hand. We address this problem through high-quality 3D asset retrieval from multi-modal inputs, including 2D sketches, images and text. We use CLIP as it provides a bridge to higher-level latent features. We use these features to perform a multi-modality fusion to address the lack of artistic control that affects common data-driven approaches. Our approach allows for multi-modal conditional feature-driven retrieval through a 3D asset database, by utilizing a combination of input latent embeddings. We explore the effects of different combinations of feature embeddings across different input types and weighting methods.