 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Multi-Modal Artist-Controlled Retrieval and Exploration of 3D Object Sets
Sep 01, 2022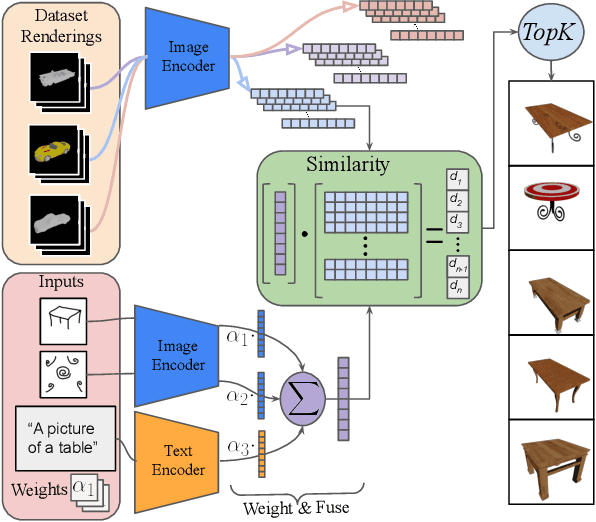

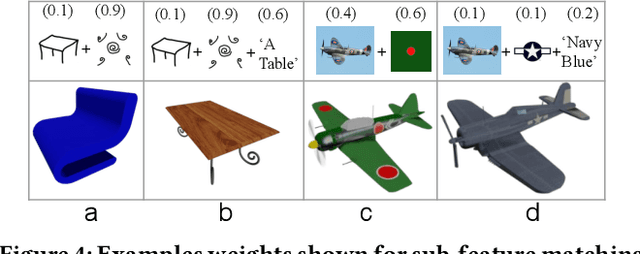
When creating 3D content, highly specialized skills are generally needed to design and generate models of objects and other assets by hand. We address this problem through high-quality 3D asset retrieval from multi-modal inputs, including 2D sketches, images and text. We use CLIP as it provides a bridge to higher-level latent features. We use these features to perform a multi-modality fusion to address the lack of artistic control that affects common data-driven approaches. Our approach allows for multi-modal conditional feature-driven retrieval through a 3D asset database, by utilizing a combination of input latent embeddings. We explore the effects of different combinations of feature embeddings across different input types and weighting methods.
Beyond Photo Realism for Domain Adaptation from Synthetic Data
Sep 04, 2019
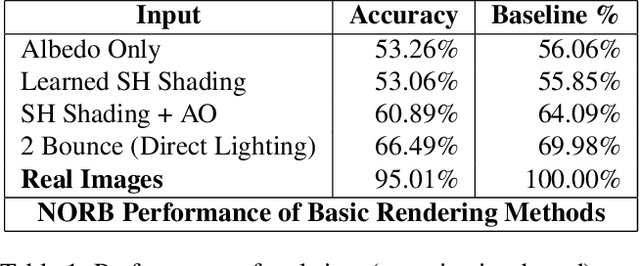
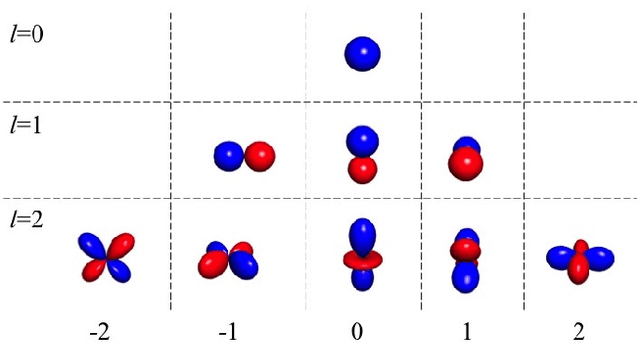
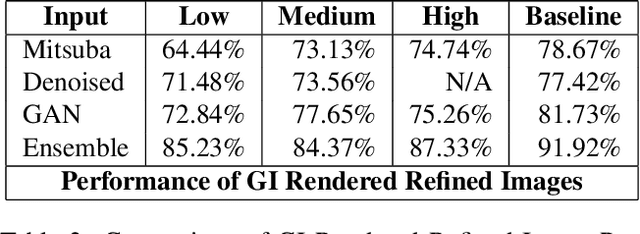
As synthetic imagery is used more frequently in training deep models, it is important to understand how different synthesis techniques impact the performance of such models. In this work, we perform a thorough evaluation of the effectiveness of several different synthesis techniques and their impact on the complexity of classifier domain adaptation to the "real" underlying data distribution that they seek to replicate. In addition, we propose a novel learned synthesis technique to better train classifier models than state-of-the-art offline graphical methods, while using significantly less computational resources. We accomplish this by learning a generative model to perform shading of synthetic geometry conditioned on a "g-buffer" representation of the scene to render, as well as a low sample Monte Carlo rendered image. The major contributions are (i) a dataset that allows comparison of real and synthetic versions of the same scene, (ii) an augmented data representation that boosts the stability of learning and improves the datasets accuracy, (iii) three different partially differentiable rendering techniques where lighting, denoising and shading are learned, and (iv) we improve a state of the art generative adversarial network (GAN) approach by using an ensemble of trained models to generate datasets that approach the performance of training on real data and surpass the performance of the full global illumination rendering.
Accelerating Eulerian Fluid Simulation With Convolutional Networks
Jun 22, 2017
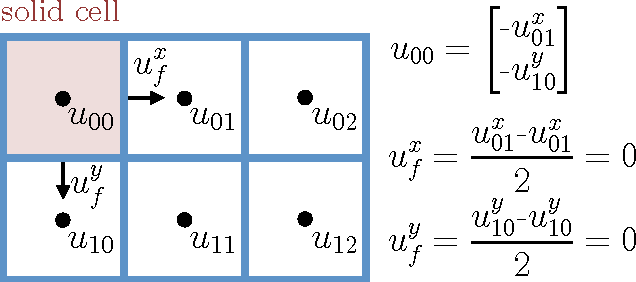
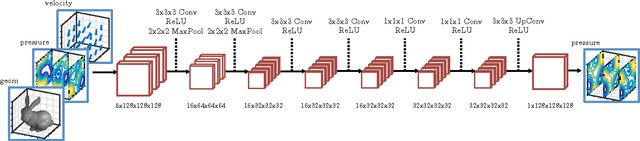
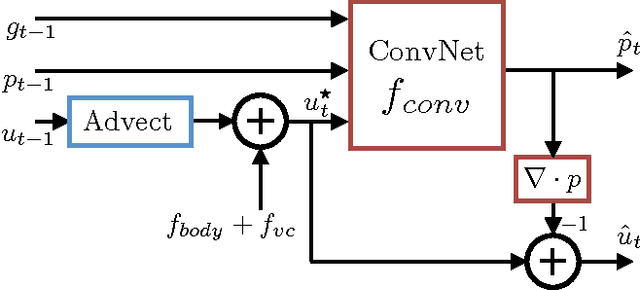
Efficient simulation of the Navier-Stokes equations for fluid flow is a long standing problem in applied mathematics, for which state-of-the-art methods require large compute resources. In this work, we propose a data-driven approach that leverages the approximation power of deep-learning with the precision of standard solvers to obtain fast and highly realistic simulations. Our method solves the incompressible Euler equations using the standard operator splitting method, in which a large sparse linear system with many free parameters must be solved. We use a Convolutional Network with a highly tailored architecture, trained using a novel unsupervised learning framework to solve the linear system. We present real-time 2D and 3D simulations that outperform recently proposed data-driven methods; the obtained results are realistic and show good generalization properties.