 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalyVFM -- Transforming Vision Foundation Models into Zero-Shot Anomaly Detectors
Jan 28, 2026Zero-shot anomaly detection aims to detect and localise abnormal regions in the image without access to any in-domain training images. While recent approaches leverage vision-language models (VLMs), such as CLIP, to transfer high-level concept knowledge, methods based on purely vision foundation models (VFMs), like DINOv2, have lagged behind in performance. We argue that this gap stems from two practical issues: (i) limited diversity in existing auxiliary anomaly detection datasets and (ii) overly shallow VFM adaptation strategies. To address both challenges, we propose AnomalyVFM, a general and effective framework that turns any pretrained VFM into a strong zero-shot anomaly detector. Our approach combines a robust three-stage synthetic dataset generation scheme with a parameter-efficient adaptation mechanism, utilising low-rank feature adapters and a confidence-weighted pixel loss. Together, these components enable modern VFMs to substantially outperform current state-of-the-art methods. More specifically, with RADIO as a backbone, AnomalyVFM achieves an average image-level AUROC of 94.1% across 9 diverse datasets, surpassing previous methods by significant 3.3 percentage points. Project Page: https://maticfuc.github.io/anomaly_vfm/
No Label Left Behind: A Unified Surface Defect Detection Model for all Supervision Regimes
Aug 26, 2025Surface defect detection is a critical task across numerous industries, aimed at efficiently identifying and localising imperfections or irregularities on manufactured components. While numerous methods have been proposed, many fail to meet industrial demands for high performance, efficiency, and adaptability. Existing approaches are often constrained to specific supervision scenarios and struggle to adapt to the diverse data annotations encountered in real-world manufacturing processes, such as unsupervised, weakly supervised, mixed supervision, and fully supervised settings. To address these challenges, we propose SuperSimpleNet, a highly efficient and adaptable discriminative model built on the foundation of SimpleNet. SuperSimpleNet incorporates a novel synthetic anomaly generation process, an enhanced classification head, and an improved learning procedure, enabling efficient training in all four supervision scenarios, making it the first model capable of fully leveraging all available data annotations. SuperSimpleNet sets a new standard for performance across all scenarios, as demonstrated by its results on four challenging benchmark datasets. Beyond accuracy, it is very fast, achieving an inference time below 10 ms. With its ability to unify diverse supervision paradigms while maintaining outstanding speed and reliability, SuperSimpleNet represents a promising step forward in addressing real-world manufacturing challenges and bridging the gap between academic research and industrial applications. Code: https://github.com/blaz-r/SuperSimpleNet
Patherea: Cell Detection and Classification for the 2020s
Dec 21, 2024This paper presents a Patherea, a framework for point-based cell detection and classification that provides a complete solution for developing and evaluating state-of-the-art approaches. We introduce a large-scale dataset collected to directly replicate a clinical workflow for Ki-67 proliferation index estimation and use it to develop an efficient point-based approach that directly predicts point-based predictions, without the need for intermediate representations. The proposed approach effectively utilizes point proposal candidates with the hybrid Hungarian matching strategy and a flexible architecture that enables the usage of various backbones and (pre)training strategies. We report state-of-the-art results on existing public datasets - Lizard, BRCA-M2C, BCData, and the newly proposed Patherea dataset. We show that the performance on existing public datasets is saturated and that the newly proposed Patherea dataset represents a significantly harder challenge for the recently proposed approaches. We also demonstrate the effectiveness of recently proposed pathology foundational models that our proposed approach can natively utilize and benefit from. We also revisit the evaluation protocol that is used in the broader field of cell detection and classification and identify the erroneous calculation of performance metrics. Patherea provides a benchmarking utility that addresses the identified issues and enables a fair comparison of different approaches. The dataset and the code will be publicly released upon acceptance.
Dense Center-Direction Regression for Object Counting and Localization with Point Supervision
Aug 26, 2024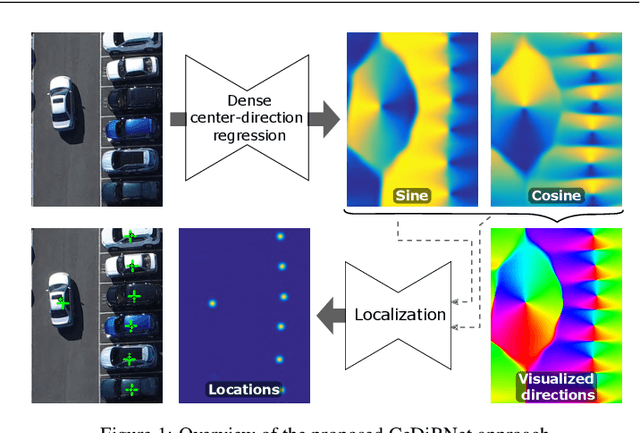



Object counting and localization problems are commonly addressed with point supervised learning, which allows the use of less labor-intensive point annotations. However, learning based on point annotations poses challenges due to the high imbalance between the sets of annotated and unannotated pixels, which is often treated with Gaussian smoothing of point annotations and focal loss. However, these approaches still focus on the pixels in the immediate vicinity of the point annotations and exploit the rest of the data only indirectly. In this work, we propose a novel approach termed CeDiRNet for point-supervised learning that uses a dense regression of directions pointing towards the nearest object centers, i.e. center-directions. This provides greater support for each center point arising from many surrounding pixels pointing towards the object center. We propose a formulation of center-directions that allows the problem to be split into the domain-specific dense regression of center-directions and the final localization task based on a small, lightweight, and domain-agnostic localization network that can be trained with synthetic data completely independent of the target domain. We demonstrate the performance of the proposed method on six different datasets for object counting and localization, and show that it outperforms the existing state-of-the-art methods. The code is accessible on GitHub at https://github.com/vicoslab/CeDiRNet.git.
Center Direction Network for Grasping Point Localization on Cloths
Aug 26, 2024



Object grasping is a fundamental challenge in robotics and computer vision, critical for advancing robotic manipulation capabilities. Deformable objects, like fabrics and cloths, pose additional challenges due to their non-rigid nature. In this work, we introduce CeDiRNet-3DoF, a deep-learning model for grasp point detection, with a particular focus on cloth objects. CeDiRNet-3DoF employs center direction regression alongside a localization network, attaining first place in the perception task of ICRA 2023's Cloth Manipulation Challenge. Recognizing the lack of standardized benchmarks in the literature that hinder effective method comparison, we present the ViCoS Towel Dataset. This extensive benchmark dataset comprises 8,000 real and 12,000 synthetic images, serving as a robust resource for training and evaluating contemporary data-driven deep-learning approaches. Extensive evaluation revealed CeDiRNet-3DoF's robustness in real-world performance, outperforming state-of-the-art methods, including the latest transformer-based models. Our work bridges a crucial gap, offering a robust solution and benchmark for cloth grasping in computer vision and robotics. Code and dataset are available at: https://github.com/vicoslab/CeDiRNet-3DoF
SuperSimpleNet: Unifying Unsupervised and Supervised Learning for Fast and Reliable Surface Defect Detection
Aug 06, 2024The aim of surface defect detection is to identify and localise abnormal regions on the surfaces of captured objects, a task that's increasingly demanded across various industries. Current approaches frequently fail to fulfil the extensive demands of these industries, which encompass high performance, consistency, and fast operation, along with the capacity to leverage the entirety of the available training data. Addressing these gaps, we introduce SuperSimpleNet, an innovative discriminative model that evolved from SimpleNet. This advanced model significantly enhances its predecessor's training consistency, inference time, as well as detection performance. SuperSimpleNet operates in an unsupervised manner using only normal training images but also benefits from labelled abnormal training images when they are available. SuperSimpleNet achieves state-of-the-art results in both the supervised and the unsupervised settings, as demonstrated by experiments across four challenging benchmark datasets. Code: https://github.com/blaz-r/SuperSimpleNet .
TransFusion -- A Transparency-Based Diffusion Model for Anomaly Detection
Nov 16, 2023


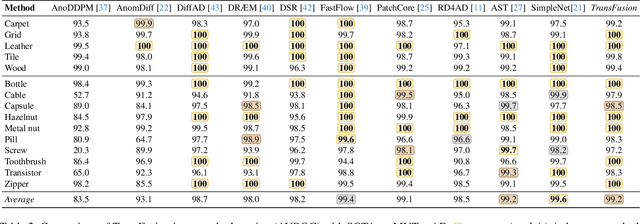
Surface anomaly detection is a vital component in manufacturing inspection. Reconstructive anomaly detection methods restore the normal appearance of an object, ideally modifying only the anomalous regions. Due to the limitations of commonly used reconstruction architectures, the produced reconstructions are often poor and either still contain anomalies or lack details in anomaly-free regions. Recent reconstructive methods adopt diffusion models, however with the standard diffusion process the problems are not adequately addressed. We propose a novel transparency-based diffusion process, where the transparency of anomalous regions is progressively increased, restoring their normal appearance accurately and maintaining the appearance of anomaly-free regions without loss of detail. We propose TRANSparency DifFUSION (TransFusion), a discriminative anomaly detection method that implements the proposed diffusion process, enabling accurate downstream anomaly detection. TransFusion achieves state-of-the-art performance on both the VisA and the MVTec AD datasets, with an image-level AUROC of 98.5% and 99.2%, respectively.
Cheating Depth: Enhancing 3D Surface Anomaly Detection via Depth Simulation
Nov 02, 2023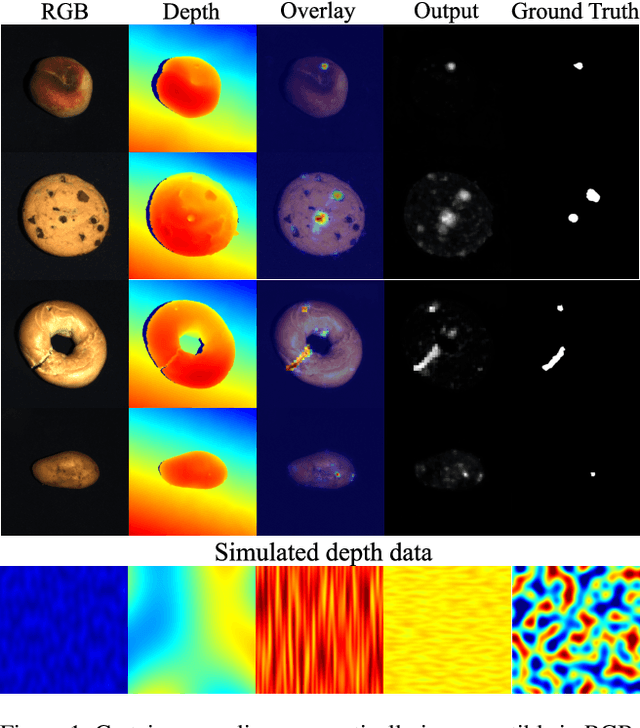
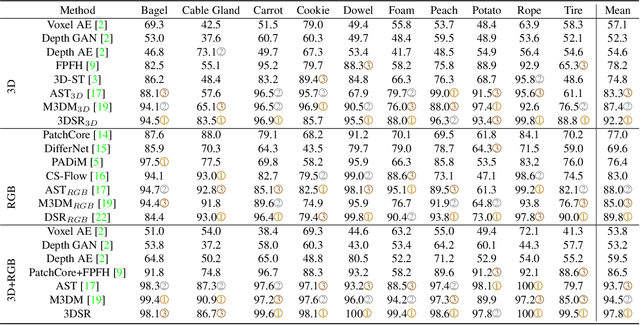
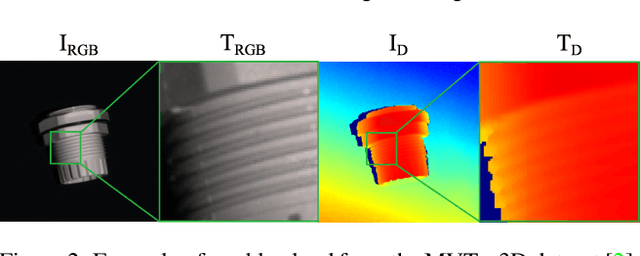
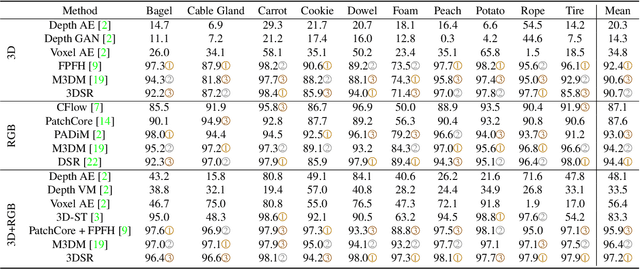
RGB-based surface anomaly detection methods have advanced significantly. However, certain surface anomalies remain practically invisible in RGB alone, necessitating the incorporation of 3D information. Existing approaches that employ point-cloud backbones suffer from suboptimal representations and reduced applicability due to slow processing. Re-training RGB backbones, designed for faster dense input processing, on industrial depth datasets is hindered by the limited availability of sufficiently large datasets. We make several contributions to address these challenges. (i) We propose a novel Depth-Aware Discrete Autoencoder (DADA) architecture, that enables learning a general discrete latent space that jointly models RGB and 3D data for 3D surface anomaly detection. (ii) We tackle the lack of diverse industrial depth datasets by introducing a simulation process for learning informative depth features in the depth encoder. (iii) We propose a new surface anomaly detection method 3DSR, which outperforms all existing state-of-the-art on the challenging MVTec3D anomaly detection benchmark, both in terms of accuracy and processing speed. The experimental results validate the effectiveness and efficiency of our approach, highlighting the potential of utilizing depth information for improved surface anomaly detection.
DSR -- A dual subspace re-projection network for surface anomaly detection
Aug 02, 2022



The state-of-the-art in discriminative unsupervised surface anomaly detection relies on external datasets for synthesizing anomaly-augmented training images. Such approaches are prone to failure on near-in-distribution anomalies since these are difficult to be synthesized realistically due to their similarity to anomaly-free regions. We propose an architecture based on quantized feature space representation with dual decoders, DSR, that avoids the image-level anomaly synthesis requirement. Without making any assumptions about the visual properties of anomalies, DSR generates the anomalies at the feature level by sampling the learned quantized feature space, which allows a controlled generation of near-in-distribution anomalies. DSR achieves state-of-the-art results on the KSDD2 and MVTec anomaly detection datasets. The experiments on the challenging real-world KSDD2 dataset show that DSR significantly outperforms other unsupervised surface anomaly detection methods, improving the previous top-performing methods by 10% AP in anomaly detection and 35% AP in anomaly localization.
Segmentation of Multiple Myeloma Plasma Cells in Microscopy Images with Noisy Labels
Nov 08, 2021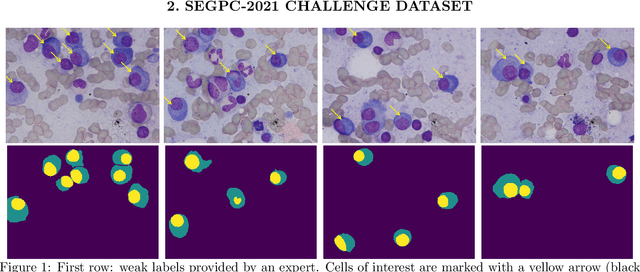
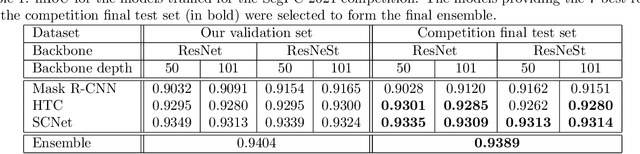
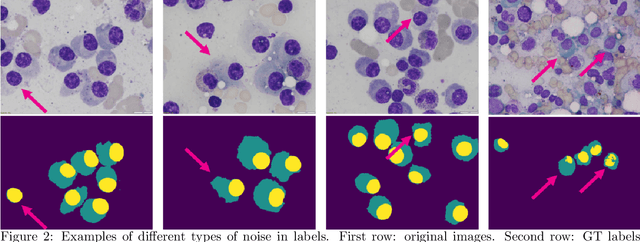

A key component towards an improved and fast cancer diagnosis is the development of computer-assisted tools. In this article, we present the solution that won the SegPC-2021 competition for the segmentation of multiple myeloma plasma cells in microscopy images. The labels used in the competition dataset were generated semi-automatically and presented noise. To deal with it, a heavy image augmentation procedure was carried out and predictions from several models were combined using a custom ensemble strategy. State-of-the-art feature extractors and instance segmentation architectures were used, resulting in a mean Intersection-over-Union of 0.9389 on the SegPC-2021 final test set.