 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatherea: Cell Detection and Classification for the 2020s
Dec 21, 2024This paper presents a Patherea, a framework for point-based cell detection and classification that provides a complete solution for developing and evaluating state-of-the-art approaches. We introduce a large-scale dataset collected to directly replicate a clinical workflow for Ki-67 proliferation index estimation and use it to develop an efficient point-based approach that directly predicts point-based predictions, without the need for intermediate representations. The proposed approach effectively utilizes point proposal candidates with the hybrid Hungarian matching strategy and a flexible architecture that enables the usage of various backbones and (pre)training strategies. We report state-of-the-art results on existing public datasets - Lizard, BRCA-M2C, BCData, and the newly proposed Patherea dataset. We show that the performance on existing public datasets is saturated and that the newly proposed Patherea dataset represents a significantly harder challenge for the recently proposed approaches. We also demonstrate the effectiveness of recently proposed pathology foundational models that our proposed approach can natively utilize and benefit from. We also revisit the evaluation protocol that is used in the broader field of cell detection and classification and identify the erroneous calculation of performance metrics. Patherea provides a benchmarking utility that addresses the identified issues and enables a fair comparison of different approaches. The dataset and the code will be publicly released upon acceptance.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Segmentation of Multiple Myeloma Plasma Cells in Microscopy Images with Noisy Labels
Nov 08, 2021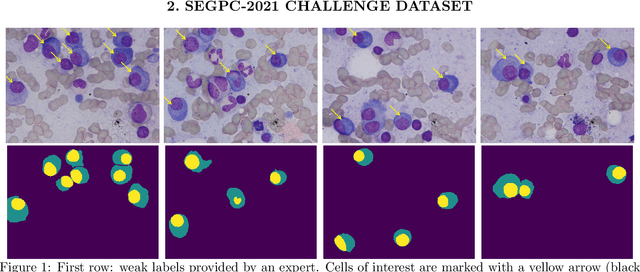
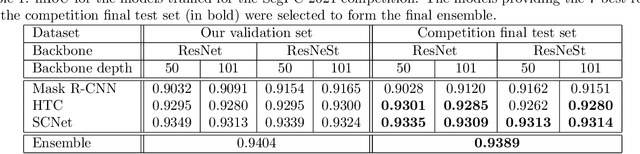
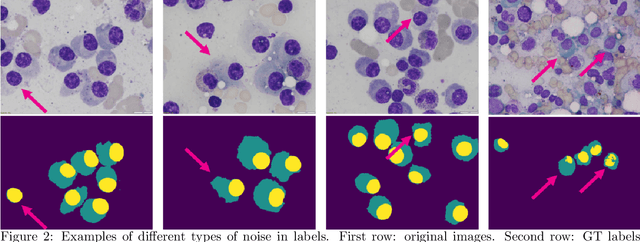

A key component towards an improved and fast cancer diagnosis is the development of computer-assisted tools. In this article, we present the solution that won the SegPC-2021 competition for the segmentation of multiple myeloma plasma cells in microscopy images. The labels used in the competition dataset were generated semi-automatically and presented noise. To deal with it, a heavy image augmentation procedure was carried out and predictions from several models were combined using a custom ensemble strategy. State-of-the-art feature extractors and instance segmentation architectures were used, resulting in a mean Intersection-over-Union of 0.9389 on the SegPC-2021 final test set.
Influence of segmentation on deep iris recognition performance
Jan 29, 2019

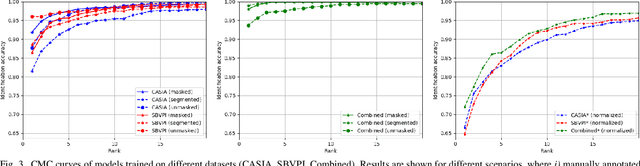

Despite the rise of deep learning in numerous areas of computer vision and image processing, iris recognition has not benefited considerably from these trends so far. Most of the existing research on deep iris recognition is focused on new models for generating discriminative and robust iris representations and relies on methodologies akin to traditional iris recognition pipelines. Hence, the proposed models do not approach iris recognition in an end-to-end manner, but rather use standard heuristic iris segmentation (and unwrapping) techniques to produce normalized inputs for the deep learning models. However, because deep learning is able to model very complex data distributions and nonlinear data changes, an obvious question arises. How important is the use of traditional segmentation methods in a deep learning setting? To answer this question, we present in this paper an empirical analysis of the impact of iris segmentation on the performance of deep learning models using a simple two stage pipeline consisting of a segmentation and a recognition step. We evaluate how the accuracy of segmentation influences recognition performance but also examine if segmentation is needed at all. We use the CASIA Thousand and SBVPI datasets for the experiments and report several interesting findings.
Training Convolutional Neural Networks with Limited Training Data for Ear Recognition in the Wild
Nov 27, 2017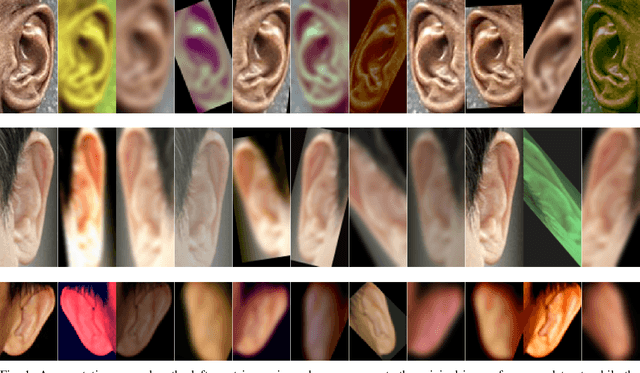
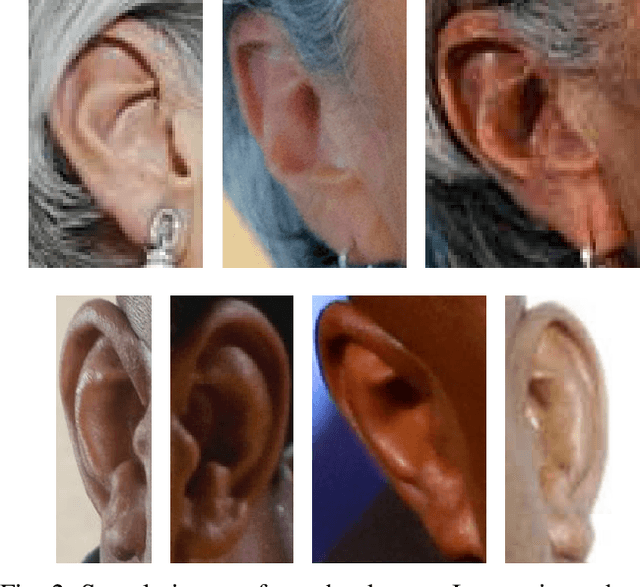
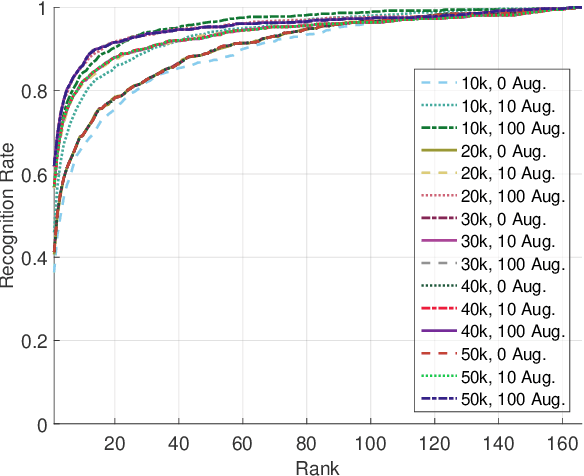
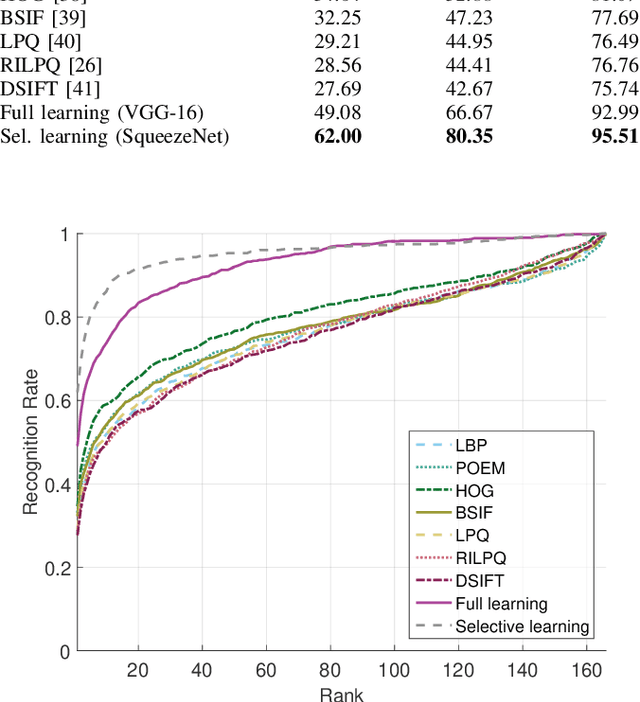
Identity recognition from ear images is an active field of research within the biometric community. The ability to capture ear images from a distance and in a covert manner makes ear recognition technology an appealing choice for surveillance and security applications as well as related application domains. In contrast to other biometric modalities, where large datasets captured in uncontrolled settings are readily available, datasets of ear images are still limited in size and mostly of laboratory-like quality. As a consequence, ear recognition technology has not benefited yet from advances in deep learning and convolutional neural networks (CNNs) and is still lacking behind other modalities that experienced significant performance gains owing to deep recognition technology. In this paper we address this problem and aim at building a CNNbased ear recognition model. We explore different strategies towards model training with limited amounts of training data and show that by selecting an appropriate model architecture, using aggressive data augmentation and selective learning on existing (pre-trained) models, we are able to learn an effective CNN-based model using a little more than 1300 training images. The result of our work is the first CNN-based approach to ear recognition that is also made publicly available to the research community. With our model we are able to improve on the rank one recognition rate of the previous state-of-the-art by more than 25% on a challenging dataset of ear images captured from the web (a.k.a. in the wild).
The Unconstrained Ear Recognition Challenge
Aug 23, 2017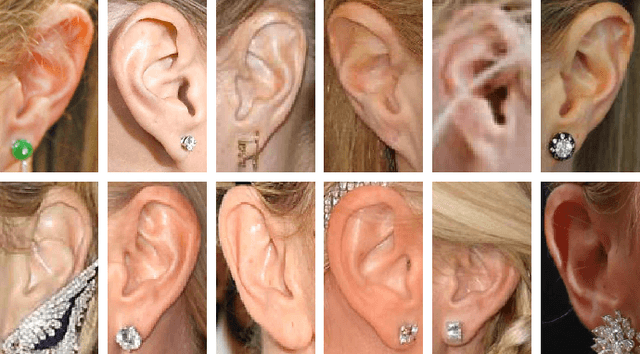


In this paper we present the results of the Unconstrained Ear Recognition Challenge (UERC), a group benchmarking effort centered around the problem of person recognition from ear images captured in uncontrolled conditions. The goal of the challenge was to assess the performance of existing ear recognition techniques on a challenging large-scale dataset and identify open problems that need to be addressed in the future. Five groups from three continents participated in the challenge and contributed six ear recognition techniques for the evaluation, while multiple baselines were made available for the challenge by the UERC organizers. A comprehensive analysis was conducted with all participating approaches addressing essential research questions pertaining to the sensitivity of the technology to head rotation, flipping, gallery size, large-scale recognition and others. The top performer of the UERC was found to ensure robust performance on a smaller part of the dataset (with 180 subjects) regardless of image characteristics, but still exhibited a significant performance drop when the entire dataset comprising 3,704 subjects was used for testing.