 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIU: Proximity-guided Identity Unlearning in ID-Conditioned Diffusion Models
May 21, 2026Identity-conditioned diffusion models enable high-quality and identity-consistent face generation, but they also raise severe privacy concerns, as models may continue to synthesize individuals despite their right to be forgotten. While machine unlearning has been extensively studied for concept and data removal, identity unlearning remains largely unexplored, particularly in models conditioned directly on identity embeddings rather than text prompts. In this work, we study identity unlearning in Arc2Face, a state-of-the-art identity-conditioned latent diffusion model for face generation, and introduce Proximity-guided Identity Unlearning (PIU), an anchor-guided framework for identity unlearning. Specifically, we formulate identity removal as an identity replacement objective that reassigns the source identity to a selected anchor identity in the learned identity space, and we complement it with a proximity-based anchor selection strategy motivated by the geometry of ArcFace representations. We further show that effective unlearning can be achieved through localized fine-tuning of a small subset of identity-sensitive cross-attention layers. Experiments across many target identities show that our framework effectively suppresses generation of the target identity while preserving realism and identity consistency for retained identities, as validated by improved performance on unlearning and image-quality metrics, together with qualitative evaluation. The source code for the PIU framework is publicly available at https://github.com/edgarcancinoe/piu_unlearning .
Second Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
ID-Booth: Identity-consistent Face Generation with Diffusion Models
Apr 10, 2025Recent advances in generative modeling have enabled the generation of high-quality synthetic data that is applicable in a variety of domains, including face recognition. Here, state-of-the-art generative models typically rely on conditioning and fine-tuning of powerful pretrained diffusion models to facilitate the synthesis of realistic images of a desired identity. Yet, these models often do not consider the identity of subjects during training, leading to poor consistency between generated and intended identities. In contrast, methods that employ identity-based training objectives tend to overfit on various aspects of the identity, and in turn, lower the diversity of images that can be generated. To address these issues, we present in this paper a novel generative diffusion-based framework, called ID-Booth. ID-Booth consists of a denoising network responsible for data generation, a variational auto-encoder for mapping images to and from a lower-dimensional latent space and a text encoder that allows for prompt-based control over the generation procedure. The framework utilizes a novel triplet identity training objective and enables identity-consistent image generation while retaining the synthesis capabilities of pretrained diffusion models. Experiments with a state-of-the-art latent diffusion model and diverse prompts reveal that our method facilitates better intra-identity consistency and inter-identity separability than competing methods, while achieving higher image diversity. In turn, the produced data allows for effective augmentation of small-scale datasets and training of better-performing recognition models in a privacy-preserving manner. The source code for the ID-Booth framework is publicly available at https://github.com/dariant/ID-Booth.
SelfMAD: Enhancing Generalization and Robustness in Morphing Attack Detection via Self-Supervised Learning
Apr 07, 2025With the continuous advancement of generative models, face morphing attacks have become a significant challenge for existing face verification systems due to their potential use in identity fraud and other malicious activities. Contemporary Morphing Attack Detection (MAD) approaches frequently rely on supervised, discriminative models trained on examples of bona fide and morphed images. These models typically perform well with morphs generated with techniques seen during training, but often lead to sub-optimal performance when subjected to novel unseen morphing techniques. While unsupervised models have been shown to perform better in terms of generalizability, they typically result in higher error rates, as they struggle to effectively capture features of subtle artifacts. To address these shortcomings, we present SelfMAD, a novel self-supervised approach that simulates general morphing attack artifacts, allowing classifiers to learn generic and robust decision boundaries without overfitting to the specific artifacts induced by particular face morphing methods. Through extensive experiments on widely used datasets, we demonstrate that SelfMAD significantly outperforms current state-of-the-art MADs, reducing the detection error by more than 64% in terms of EER when compared to the strongest unsupervised competitor, and by more than 66%, when compared to the best performing discriminative MAD model, tested in cross-morph settings. The source code for SelfMAD is available at https://github.com/LeonTodorov/SelfMAD.
EdgeEar: Efficient and Accurate Ear Recognition for Edge Devices
Feb 11, 2025Ear recognition is a contactless and unobtrusive biometric technique with applications across various domains. However, deploying high-performing ear recognition models on resource-constrained devices is challenging, limiting their applicability and widespread adoption. This paper introduces EdgeEar, a lightweight model based on a proposed hybrid CNN-transformer architecture to solve this problem. By incorporating low-rank approximations into specific linear layers, EdgeEar reduces its parameter count by a factor of 50 compared to the current state-of-the-art, bringing it below two million while maintaining competitive accuracy. Evaluation on the Unconstrained Ear Recognition Challenge (UERC2023) benchmark shows that EdgeEar achieves the lowest EER while significantly reducing computational costs. These findings demonstrate the feasibility of efficient and accurate ear recognition, which we believe will contribute to the wider adoption of ear biometrics.
MADation: Face Morphing Attack Detection with Foundation Models
Jan 08, 2025Despite the considerable performance improvements of face recognition algorithms in recent years, the same scientific advances responsible for this progress can also be used to create efficient ways to attack them, posing a threat to their secure deployment. Morphing attack detection (MAD) systems aim to detect a specific type of threat, morphing attacks, at an early stage, preventing them from being considered for verification in critical processes. Foundation models (FM) learn from extensive amounts of unlabeled data, achieving remarkable zero-shot generalization to unseen domains. Although this generalization capacity might be weak when dealing with domain-specific downstream tasks such as MAD, FMs can easily adapt to these settings while retaining the built-in knowledge acquired during pre-training. In this work, we recognize the potential of FMs to perform well in the MAD task when properly adapted to its specificities. To this end, we adapt FM CLIP architectures with LoRA weights while simultaneously training a classification header. The proposed framework, MADation surpasses our alternative FM and transformer-based frameworks and constitutes the first adaption of FMs to the MAD task. MADation presents competitive results with current MAD solutions in the literature and even surpasses them in several evaluation scenarios. To encourage reproducibility and facilitate further research in MAD, we publicly release the implementation of MADation at https: //github.com/gurayozgur/MADation
DiCTI: Diffusion-based Clothing Designer via Text-guided Input
Jul 04, 2024


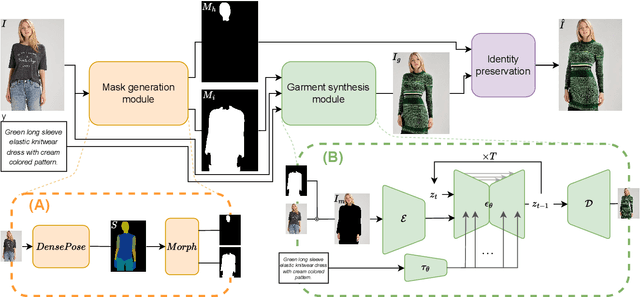
Recent developments in deep generative models have opened up a wide range of opportunities for image synthesis, leading to significant changes in various creative fields, including the fashion industry. While numerous methods have been proposed to benefit buyers, particularly in virtual try-on applications, there has been relatively less focus on facilitating fast prototyping for designers and customers seeking to order new designs. To address this gap, we introduce DiCTI (Diffusion-based Clothing Designer via Text-guided Input), a straightforward yet highly effective approach that allows designers to quickly visualize fashion-related ideas using text inputs only. Given an image of a person and a description of the desired garments as input, DiCTI automatically generates multiple high-resolution, photorealistic images that capture the expressed semantics. By leveraging a powerful diffusion-based inpainting model conditioned on text inputs, DiCTI is able to synthesize convincing, high-quality images with varied clothing designs that viably follow the provided text descriptions, while being able to process very diverse and challenging inputs, captured in completely unconstrained settings. We evaluate DiCTI in comprehensive experiments on two different datasets (VITON-HD and Fashionpedia) and in comparison to the state-of-the-art (SoTa). The results of our experiments show that DiCTI convincingly outperforms the SoTA competitor in generating higher quality images with more elaborate garments and superior text prompt adherence, both according to standard quantitative evaluation measures and human ratings, generated as part of a user study.
AI-KD: Towards Alignment Invariant Face Image Quality Assessment Using Knowledge Distillation
Apr 15, 2024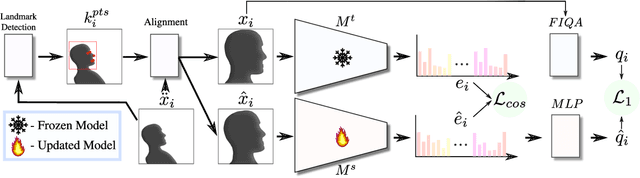
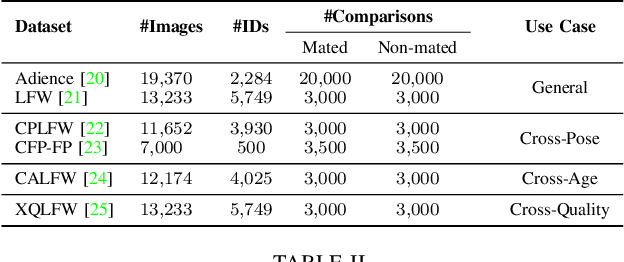
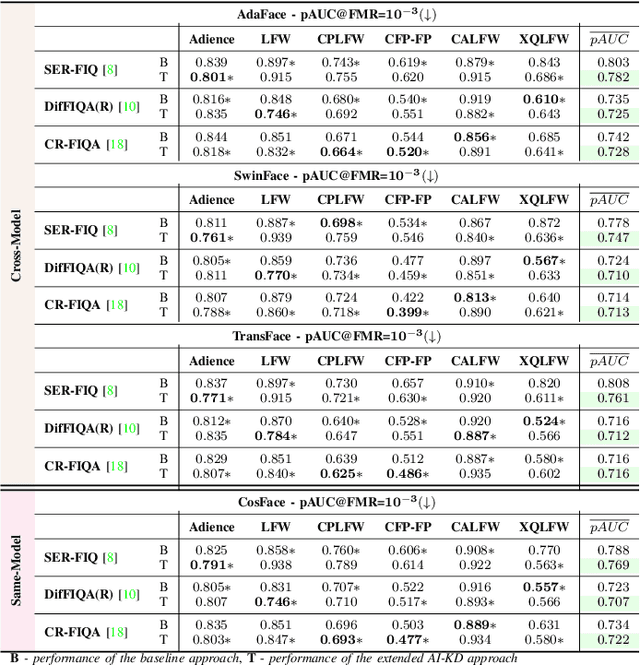
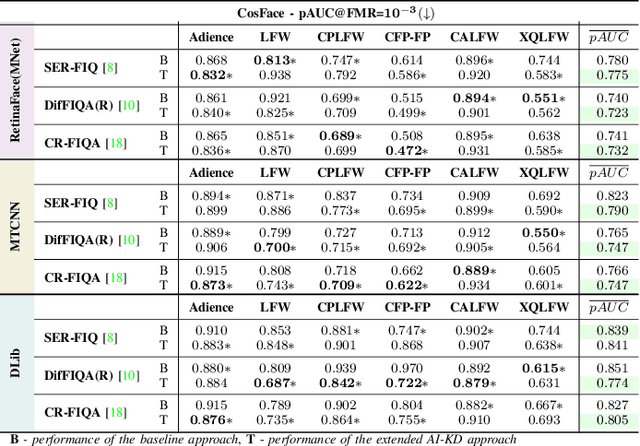
Face Image Quality Assessment (FIQA) techniques have seen steady improvements over recent years, but their performance still deteriorates if the input face samples are not properly aligned. This alignment sensitivity comes from the fact that most FIQA techniques are trained or designed using a specific face alignment procedure. If the alignment technique changes, the performance of most existing FIQA techniques quickly becomes suboptimal. To address this problem, we present in this paper a novel knowledge distillation approach, termed AI-KD that can extend on any existing FIQA technique, improving its robustness to alignment variations and, in turn, performance with different alignment procedures. To validate the proposed distillation approach, we conduct comprehensive experiments on 6 face datasets with 4 recent face recognition models and in comparison to 7 state-of-the-art FIQA techniques. Our results show that AI-KD consistently improves performance of the initial FIQA techniques not only with misaligned samples, but also with properly aligned facial images. Furthermore, it leads to a new state-of-the-art, when used with a competitive initial FIQA approach. The code for AI-KD is made publicly available from: https://github.com/LSIbabnikz/AI-KD.
Beyond Detection: Visual Realism Assessment of Deepfakes
Jun 09, 2023In the era of rapid digitalization and artificial intelligence advancements, the development of DeepFake technology has posed significant security and privacy concerns. This paper presents an effective measure to assess the visual realism of DeepFake videos. We utilize an ensemble of two Convolutional Neural Network (CNN) models: Eva and ConvNext. These models have been trained on the DeepFake Game Competition (DFGC) 2022 dataset and aim to predict Mean Opinion Scores (MOS) from DeepFake videos based on features extracted from sequences of frames. Our method secured the third place in the recent DFGC on Visual Realism Assessment held in conjunction with the 2023 International Joint Conference on Biometrics (IJCB 2023). We provide an over\-view of the models, data preprocessing, and training procedures. We also report the performance of our models against the competition's baseline model and discuss the implications of our findings.
DifFIQA: Face Image Quality Assessment Using Denoising Diffusion Probabilistic Models
May 09, 2023Modern face recognition (FR) models excel in constrained scenarios, but often suffer from decreased performance when deployed in unconstrained (real-world) environments due to uncertainties surrounding the quality of the captured facial data. Face image quality assessment (FIQA) techniques aim to mitigate these performance degradations by providing FR models with sample-quality predictions that can be used to reject low-quality samples and reduce false match errors. However, despite steady improvements, ensuring reliable quality estimates across facial images with diverse characteristics remains challenging. In this paper, we present a powerful new FIQA approach, named DifFIQA, which relies on denoising diffusion probabilistic models (DDPM) and ensures highly competitive results. The main idea behind the approach is to utilize the forward and backward processes of DDPMs to perturb facial images and quantify the impact of these perturbations on the corresponding image embeddings for quality prediction. Because the diffusion-based perturbations are computationally expensive, we also distill the knowledge encoded in DifFIQA into a regression-based quality predictor, called DifFIQA(R), that balances performance and execution time. We evaluate both models in comprehensive experiments on 7 datasets, with 4 target FR models and against 10 state-of-the-art FIQA techniques with highly encouraging results. The source code will be made publicly available.