 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIU: Proximity-guided Identity Unlearning in ID-Conditioned Diffusion Models
May 21, 2026Identity-conditioned diffusion models enable high-quality and identity-consistent face generation, but they also raise severe privacy concerns, as models may continue to synthesize individuals despite their right to be forgotten. While machine unlearning has been extensively studied for concept and data removal, identity unlearning remains largely unexplored, particularly in models conditioned directly on identity embeddings rather than text prompts. In this work, we study identity unlearning in Arc2Face, a state-of-the-art identity-conditioned latent diffusion model for face generation, and introduce Proximity-guided Identity Unlearning (PIU), an anchor-guided framework for identity unlearning. Specifically, we formulate identity removal as an identity replacement objective that reassigns the source identity to a selected anchor identity in the learned identity space, and we complement it with a proximity-based anchor selection strategy motivated by the geometry of ArcFace representations. We further show that effective unlearning can be achieved through localized fine-tuning of a small subset of identity-sensitive cross-attention layers. Experiments across many target identities show that our framework effectively suppresses generation of the target identity while preserving realism and identity consistency for retained identities, as validated by improved performance on unlearning and image-quality metrics, together with qualitative evaluation. The source code for the PIU framework is publicly available at https://github.com/edgarcancinoe/piu_unlearning .
EdgeEar: Efficient and Accurate Ear Recognition for Edge Devices
Feb 11, 2025Ear recognition is a contactless and unobtrusive biometric technique with applications across various domains. However, deploying high-performing ear recognition models on resource-constrained devices is challenging, limiting their applicability and widespread adoption. This paper introduces EdgeEar, a lightweight model based on a proposed hybrid CNN-transformer architecture to solve this problem. By incorporating low-rank approximations into specific linear layers, EdgeEar reduces its parameter count by a factor of 50 compared to the current state-of-the-art, bringing it below two million while maintaining competitive accuracy. Evaluation on the Unconstrained Ear Recognition Challenge (UERC2023) benchmark shows that EdgeEar achieves the lowest EER while significantly reducing computational costs. These findings demonstrate the feasibility of efficient and accurate ear recognition, which we believe will contribute to the wider adoption of ear biometrics.
The Unconstrained Ear Recognition Challenge 2019 - ArXiv Version With Appendix
Mar 14, 2019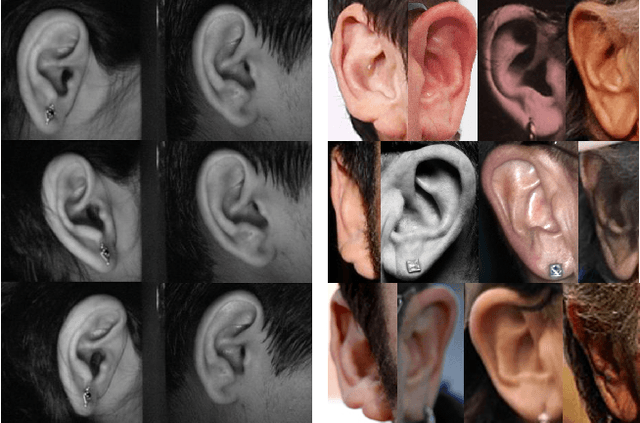

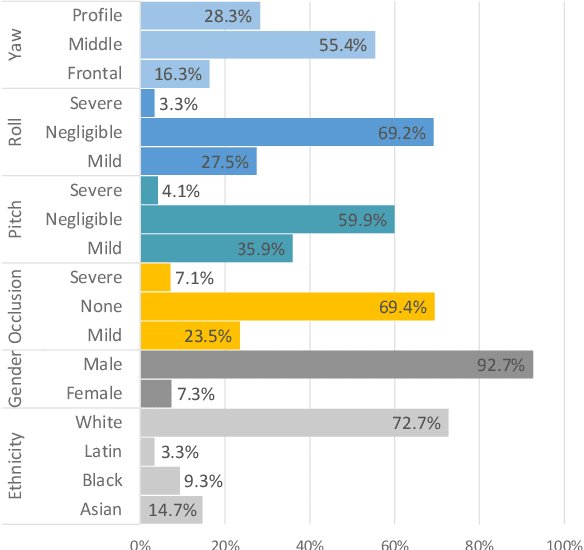
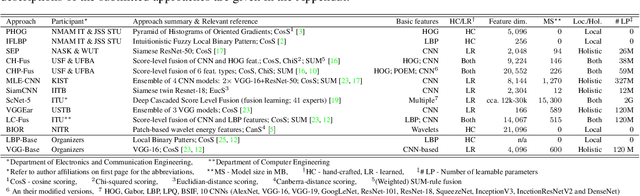
This paper presents a summary of the 2019 Unconstrained Ear Recognition Challenge (UERC), the second in a series of group benchmarking efforts centered around the problem of person recognition from ear images captured in uncontrolled settings. The goal of the challenge is to assess the performance of existing ear recognition techniques on a challenging large-scale ear dataset and to analyze performance of the technology from various viewpoints, such as generalization abilities to unseen data characteristics, sensitivity to rotations, occlusions and image resolution and performance bias on sub-groups of subjects, selected based on demographic criteria, i.e. gender and ethnicity. Research groups from 12 institutions entered the competition and submitted a total of 13 recognition approaches ranging from descriptor-based methods to deep-learning models. The majority of submissions focused on ensemble based methods combining either representations from multiple deep models or hand-crafted with learned image descriptors. Our analysis shows that methods incorporating deep learning models clearly outperform techniques relying solely on hand-crafted descriptors, even though both groups of techniques exhibit similar behaviour when it comes to robustness to various covariates, such presence of occlusions, changes in (head) pose, or variability in image resolution. The results of the challenge also show that there has been considerable progress since the first UERC in 2017, but that there is still ample room for further research in this area.
Training Convolutional Neural Networks with Limited Training Data for Ear Recognition in the Wild
Nov 27, 2017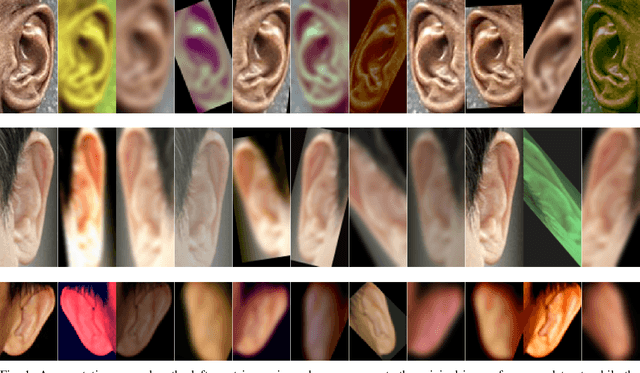
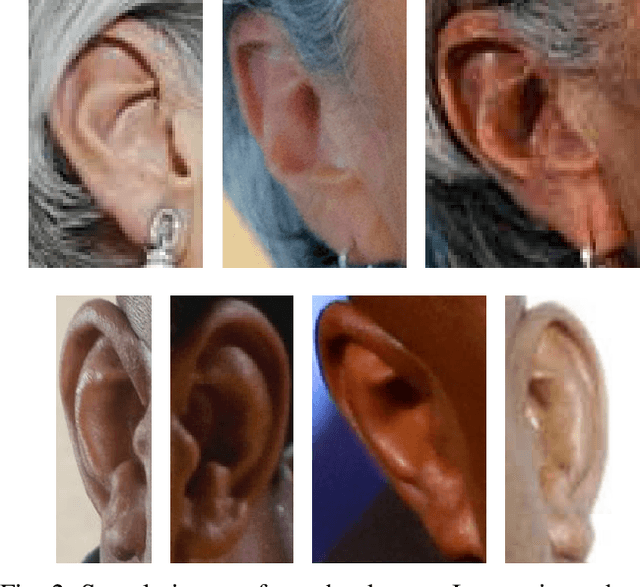
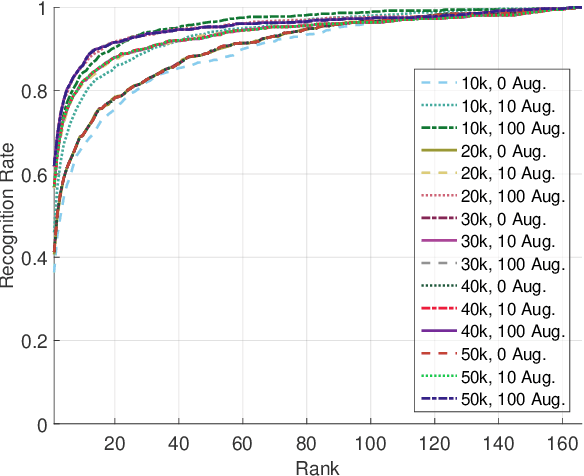
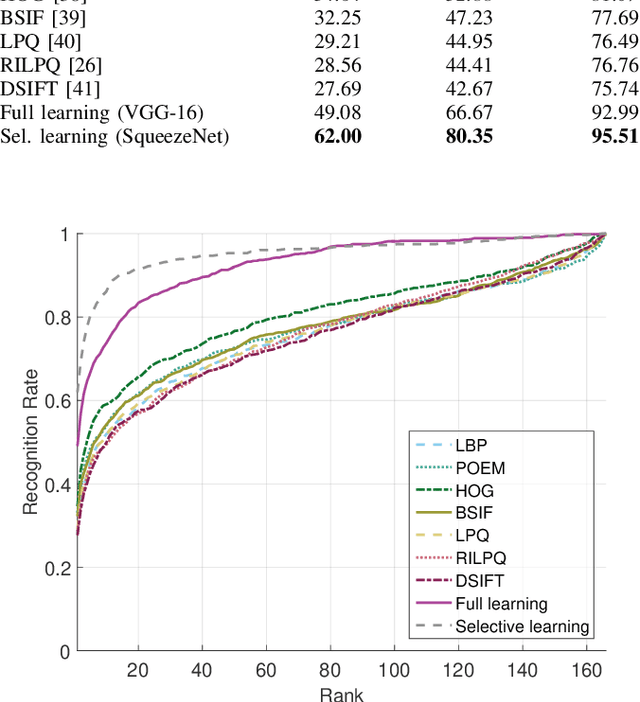
Identity recognition from ear images is an active field of research within the biometric community. The ability to capture ear images from a distance and in a covert manner makes ear recognition technology an appealing choice for surveillance and security applications as well as related application domains. In contrast to other biometric modalities, where large datasets captured in uncontrolled settings are readily available, datasets of ear images are still limited in size and mostly of laboratory-like quality. As a consequence, ear recognition technology has not benefited yet from advances in deep learning and convolutional neural networks (CNNs) and is still lacking behind other modalities that experienced significant performance gains owing to deep recognition technology. In this paper we address this problem and aim at building a CNNbased ear recognition model. We explore different strategies towards model training with limited amounts of training data and show that by selecting an appropriate model architecture, using aggressive data augmentation and selective learning on existing (pre-trained) models, we are able to learn an effective CNN-based model using a little more than 1300 training images. The result of our work is the first CNN-based approach to ear recognition that is also made publicly available to the research community. With our model we are able to improve on the rank one recognition rate of the previous state-of-the-art by more than 25% on a challenging dataset of ear images captured from the web (a.k.a. in the wild).
The Unconstrained Ear Recognition Challenge
Aug 23, 2017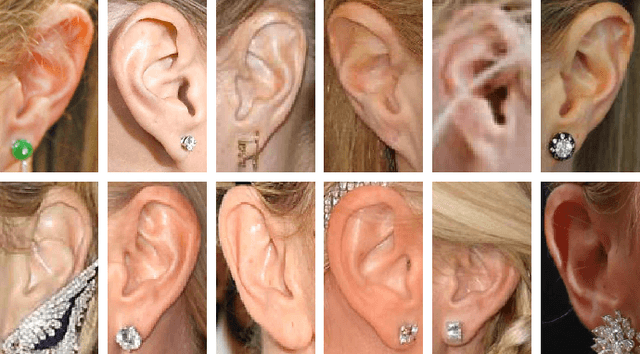


In this paper we present the results of the Unconstrained Ear Recognition Challenge (UERC), a group benchmarking effort centered around the problem of person recognition from ear images captured in uncontrolled conditions. The goal of the challenge was to assess the performance of existing ear recognition techniques on a challenging large-scale dataset and identify open problems that need to be addressed in the future. Five groups from three continents participated in the challenge and contributed six ear recognition techniques for the evaluation, while multiple baselines were made available for the challenge by the UERC organizers. A comprehensive analysis was conducted with all participating approaches addressing essential research questions pertaining to the sensitivity of the technology to head rotation, flipping, gallery size, large-scale recognition and others. The top performer of the UERC was found to ensure robust performance on a smaller part of the dataset (with 180 subjects) regardless of image characteristics, but still exhibited a significant performance drop when the entire dataset comprising 3,704 subjects was used for testing.
Pixel-wise Ear Detection with Convolutional Encoder-Decoder Networks
Feb 01, 2017
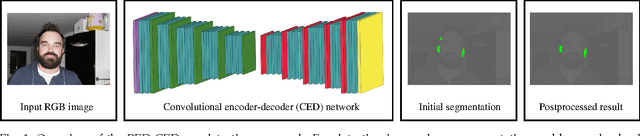
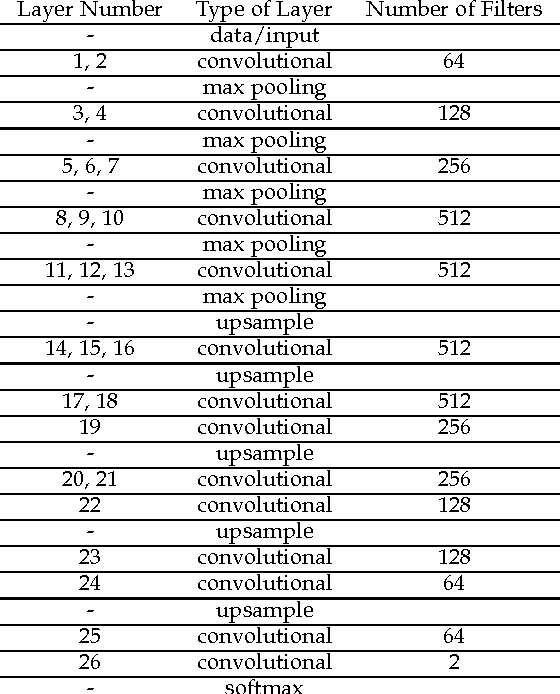
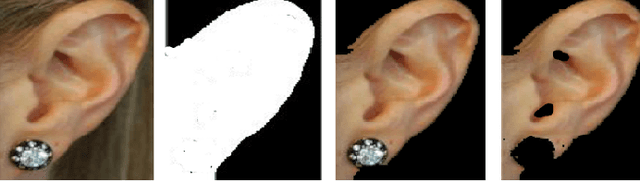
Object detection and segmentation represents the basis for many tasks in computer and machine vision. In biometric recognition systems the detection of the region-of-interest (ROI) is one of the most crucial steps in the overall processing pipeline, significantly impacting the performance of the entire recognition system. Existing approaches to ear detection, for example, are commonly susceptible to the presence of severe occlusions, ear accessories or variable illumination conditions and often deteriorate in their performance if applied on ear images captured in unconstrained settings. To address these shortcomings, we present in this paper a novel ear detection technique based on convolutional encoder-decoder networks (CEDs). For our technique, we formulate the problem of ear detection as a two-class segmentation problem and train a convolutional encoder-decoder network based on the SegNet architecture to distinguish between image-pixels belonging to either the ear or the non-ear class. The output of the network is then post-processed to further refine the segmentation result and return the final locations of the ears in the input image. Different from competing techniques from the literature, our approach does not simply return a bounding box around the detected ear, but provides detailed, pixel-wise information about the location of the ears in the image. Our experiments on a dataset gathered from the web (a.k.a. in the wild) show that the proposed technique ensures good detection results in the presence of various covariate factors and significantly outperforms the existing state-of-the-art.
Ear Recognition: More Than a Survey
Nov 18, 2016
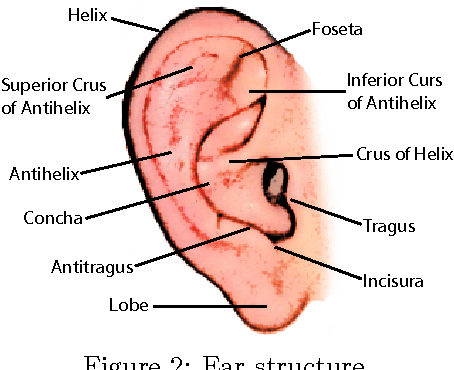
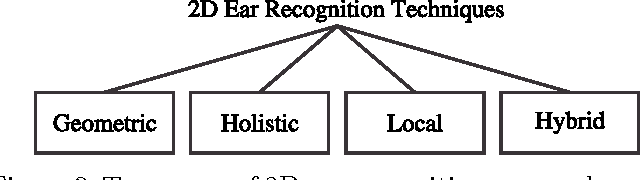
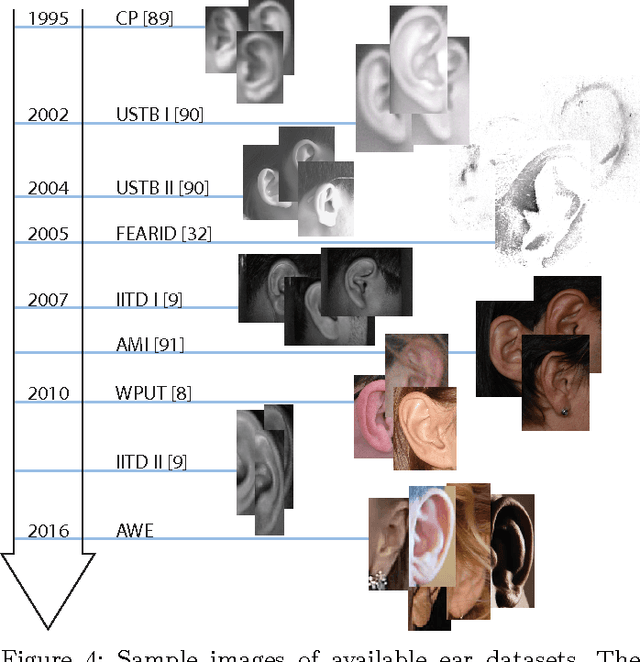
Automatic identity recognition from ear images represents an active field of research within the biometric community. The ability to capture ear images from a distance and in a covert manner makes the technology an appealing choice for surveillance and security applications as well as other application domains. Significant contributions have been made in the field over recent years, but open research problems still remain and hinder a wider (commercial) deployment of the technology. This paper presents an overview of the field of automatic ear recognition (from 2D images) and focuses specifically on the most recent, descriptor-based methods proposed in this area. Open challenges are discussed and potential research directions are outlined with the goal of providing the reader with a point of reference for issues worth examining in the future. In addition to a comprehensive review on ear recognition technology, the paper also introduces a new, fully unconstrained dataset of ear images gathered from the web and a toolbox implementing several state-of-the-art techniques for ear recognition. The dataset and toolbox are meant to address some of the open issues in the field and are made publicly available to the research community.