 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Language Learning through Technology: Introducing a New English-Azerbaijani (Arabic Script) Parallel Corpus
Jul 06, 2024This paper introduces a pioneering English-Azerbaijani (Arabic Script) parallel corpus, designed to bridge the technological gap in language learning and machine translation (MT) for under-resourced languages. Consisting of 548,000 parallel sentences and approximately 9 million words per language, this dataset is derived from diverse sources such as news articles and holy texts, aiming to enhance natural language processing (NLP) applications and language education technology. This corpus marks a significant step forward in the realm of linguistic resources, particularly for Turkic languages, which have lagged in the neural machine translation (NMT) revolution. By presenting the first comprehensive case study for the English-Azerbaijani (Arabic Script) language pair, this work underscores the transformative potential of NMT in low-resource contexts. The development and utilization of this corpus not only facilitate the advancement of machine translation systems tailored for specific linguistic needs but also promote inclusive language learning through technology. The findings demonstrate the corpus's effectiveness in training deep learning MT systems and underscore its role as an essential asset for researchers and educators aiming to foster bilingual education and multilingual communication. This research covers the way for future explorations into NMT applications for languages lacking substantial digital resources, thereby enhancing global language education frameworks. The Python package of our code is available at https://pypi.org/project/chevir-kartalol/, and we also have a website accessible at https://translate.kartalol.com/.
Transfer learning using deep neural networks for Ear Presentation Attack Detection: New Database for PAD
Dec 09, 2021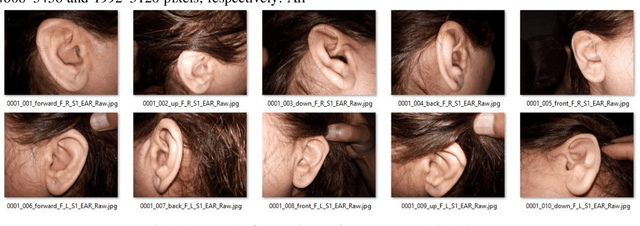
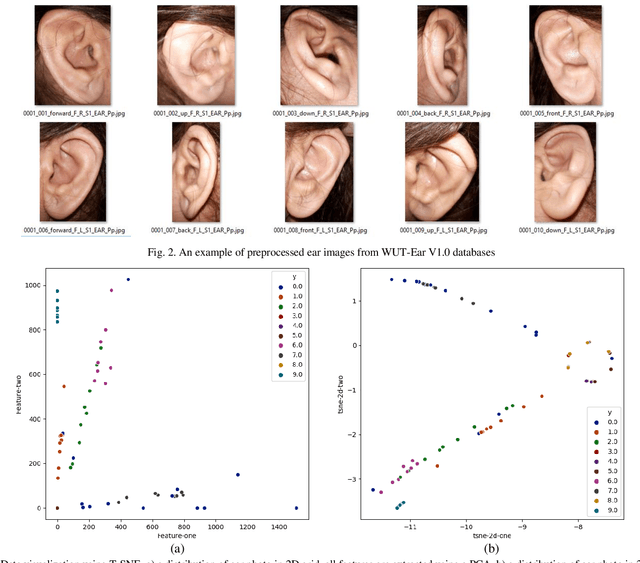
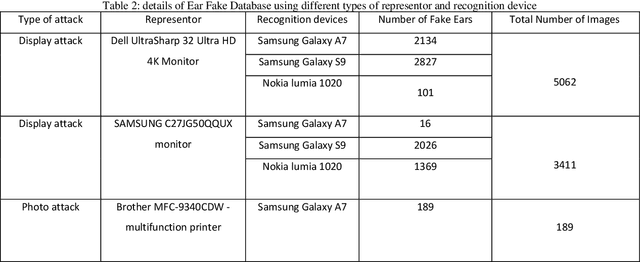
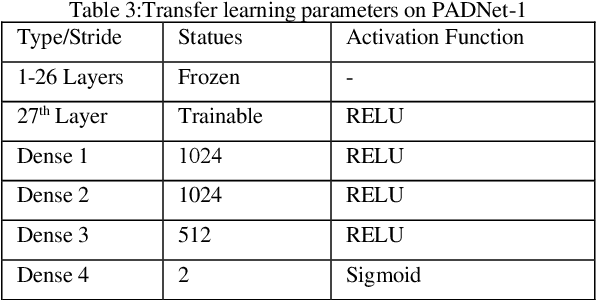
Ear recognition system has been widely studied whereas there are just a few ear presentation attack detection methods for ear recognition systems, consequently, there is no publicly available ear presentation attack detection (PAD) database. In this paper, we propose a PAD method using a pre-trained deep neural network and release a new dataset called Warsaw University of Technology Ear Dataset for Presentation Attack Detection (WUT-Ear V1.0). There is no ear database that is captured using mobile devices. Hence, we have captured more than 8500 genuine ear images from 134 subjects and more than 8500 fake ear images using. We made replay-attack and photo print attacks with 3 different mobile devices. Our approach achieves 99.83% and 0.08% for the half total error rate (HTER) and attack presentation classification error rate (APCER), respectively, on the replay-attack database. The captured data is analyzed and visualized statistically to find out its importance and make it a benchmark for further research. The experiments have been found out a secure PAD method for ear recognition system, publicly available ear image, and ear PAD dataset. The codes and evaluation results are publicly available at https://github.com/Jalilnkh/KartalOl-EAR-PAD.
KartalOl: Transfer learning using deep neural network for iris segmentation and localization: New dataset for iris segmentation
Dec 09, 2021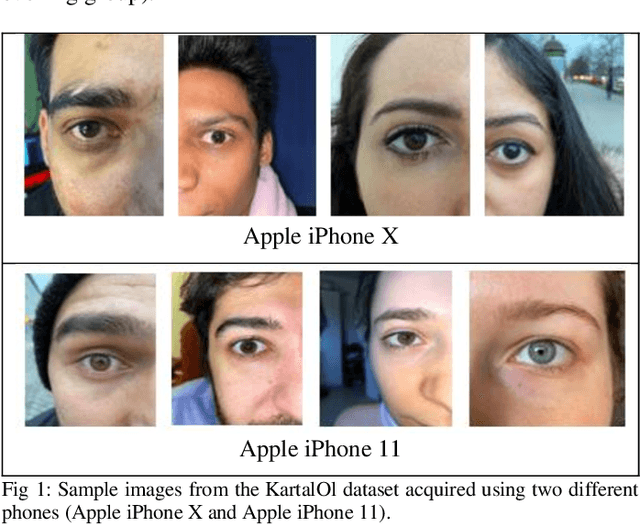

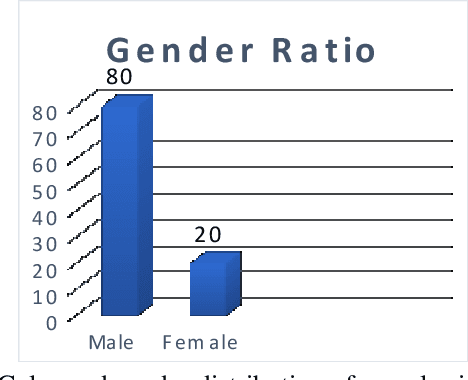

Iris segmentation and localization in unconstrained environments is challenging due to long distances, illumination variations, limited user cooperation, and moving subjects. To address this problem, we present a U-Net with a pre-trained MobileNetV2 deep neural network method. We employ the pre-trained weights given with MobileNetV2 for the ImageNet dataset and fine-tune it on the iris recognition and localization domain. Further, we have introduced a new dataset, called KartalOl, to better evaluate detectors in iris recognition scenarios. To provide domain adaptation, we fine-tune the MobileNetV2 model on the provided data for NIR-ISL 2021 from the CASIA-Iris-Asia, CASIA-Iris-M1, and CASIA-Iris-Africa and our dataset. We also augment the data by performing left-right flips, rotation, zoom, and brightness. We chose the binarization threshold for the binary masks by iterating over the images in the provided dataset. The proposed method is tested and trained in CASIA-Iris-Asia, CASIA-Iris-M1, CASIA-Iris-Africa, along the KartalOl dataset. The experimental results highlight that our method surpasses state-of-the-art methods on mobile-based benchmarks. The codes and evaluation results are publicly available at https://github.com/Jalilnkh/KartalOl-NIR-ISL2021031301.
Presentation Attack Detection Methods based on Gaze Tracking and Pupil Dynamic: A Comprehensive Survey
Dec 07, 2021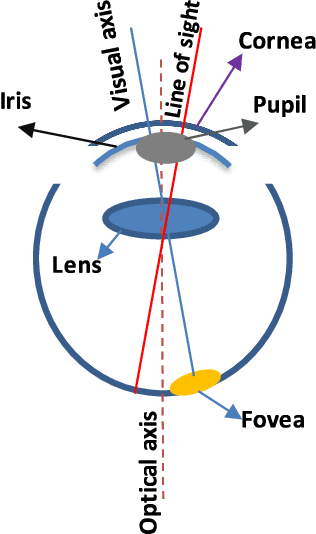
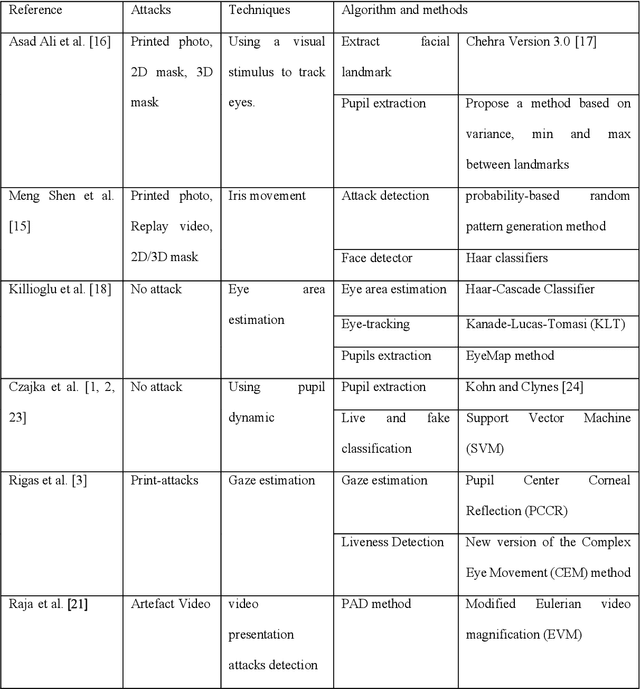


Purpose of the research: In the biometric community, visible human characteristics are popular and viable for verification and identification on mobile devices. However, imposters are able to spoof such characteristics by creating fake and artificial biometrics to fool the system. Visible biometric systems have suffered a high-security risk of presentation attack. Methods: In the meantime, challenge-based methods, in particular, gaze tracking and pupil dynamic appear to be more secure methods than others for contactless biometric systems. We review the existing work that explores gaze tracking and pupil dynamic liveness detection. The principal results: This research analyzes various aspects of gaze tracking and pupil dynamic presentation attacks, such as state-of-the-art liveness detection algorithms, various kinds of artifacts, the accessibility of public databases, and a summary of standardization in this area. In addition, we discuss future work and the open challenges to creating a secure liveness detection based on challenge-based systems.
The Unconstrained Ear Recognition Challenge 2019 - ArXiv Version With Appendix
Mar 14, 2019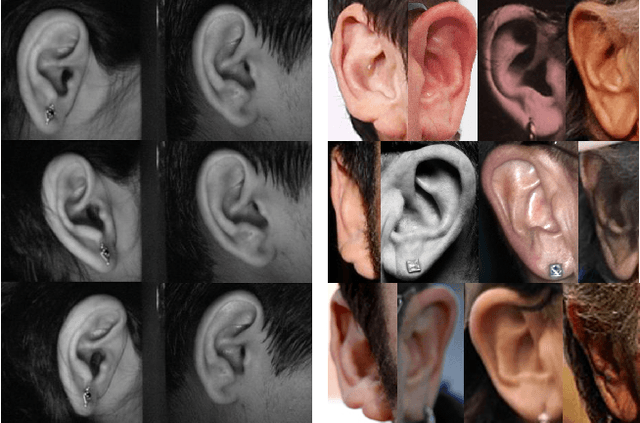

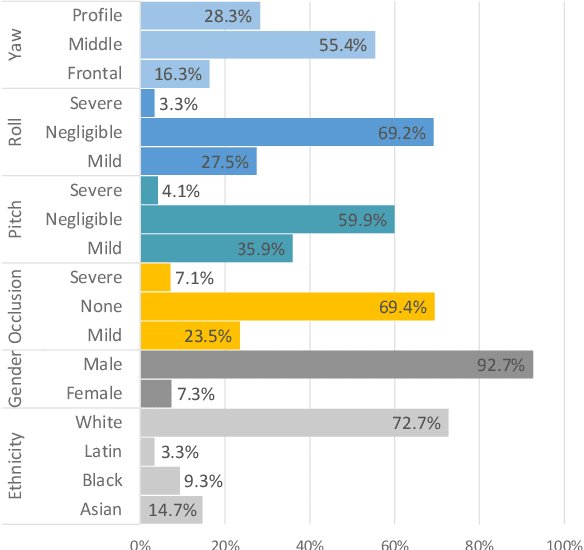
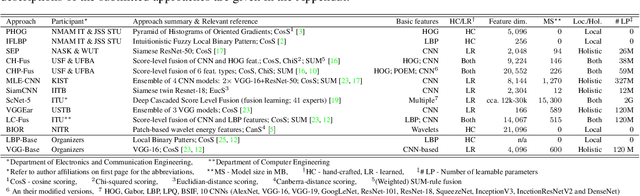
This paper presents a summary of the 2019 Unconstrained Ear Recognition Challenge (UERC), the second in a series of group benchmarking efforts centered around the problem of person recognition from ear images captured in uncontrolled settings. The goal of the challenge is to assess the performance of existing ear recognition techniques on a challenging large-scale ear dataset and to analyze performance of the technology from various viewpoints, such as generalization abilities to unseen data characteristics, sensitivity to rotations, occlusions and image resolution and performance bias on sub-groups of subjects, selected based on demographic criteria, i.e. gender and ethnicity. Research groups from 12 institutions entered the competition and submitted a total of 13 recognition approaches ranging from descriptor-based methods to deep-learning models. The majority of submissions focused on ensemble based methods combining either representations from multiple deep models or hand-crafted with learned image descriptors. Our analysis shows that methods incorporating deep learning models clearly outperform techniques relying solely on hand-crafted descriptors, even though both groups of techniques exhibit similar behaviour when it comes to robustness to various covariates, such presence of occlusions, changes in (head) pose, or variability in image resolution. The results of the challenge also show that there has been considerable progress since the first UERC in 2017, but that there is still ample room for further research in this area.