 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Attractor Models
Oct 03, 2024



Sequential memory, the ability to form and accurately recall a sequence of events or stimuli in the correct order, is a fundamental prerequisite for biological and artificial intelligence as it underpins numerous cognitive functions (e.g., language comprehension, planning, episodic memory formation, etc.) However, existing methods of sequential memory suffer from catastrophic forgetting, limited capacity, slow iterative learning procedures, low-order Markov memory, and, most importantly, the inability to represent and generate multiple valid future possibilities stemming from the same context. Inspired by biologically plausible neuroscience theories of cognition, we propose \textit{Predictive Attractor Models (PAM)}, a novel sequence memory architecture with desirable generative properties. PAM is a streaming model that learns a sequence in an online, continuous manner by observing each input \textit{only once}. Additionally, we find that PAM avoids catastrophic forgetting by uniquely representing past context through lateral inhibition in cortical minicolumns, which prevents new memories from overwriting previously learned knowledge. PAM generates future predictions by sampling from a union set of predicted possibilities; this generative ability is realized through an attractor model trained alongside the predictor. We show that PAM is trained with local computations through Hebbian plasticity rules in a biologically plausible framework. Other desirable traits (e.g., noise tolerance, CPU-based learning, capacity scaling) are discussed throughout the paper. Our findings suggest that PAM represents a significant step forward in the pursuit of biologically plausible and computationally efficient sequential memory models, with broad implications for cognitive science and artificial intelligence research.
LocaliseBot: Multi-view 3D object localisation with differentiable rendering for robot grasping
Nov 14, 2023Robot grasp typically follows five stages: object detection, object localisation, object pose estimation, grasp pose estimation, and grasp planning. We focus on object pose estimation. Our approach relies on three pieces of information: multiple views of the object, the camera's extrinsic parameters at those viewpoints, and 3D CAD models of objects. The first step involves a standard deep learning backbone (FCN ResNet) to estimate the object label, semantic segmentation, and a coarse estimate of the object pose with respect to the camera. Our novelty is using a refinement module that starts from the coarse pose estimate and refines it by optimisation through differentiable rendering. This is a purely vision-based approach that avoids the need for other information such as point cloud or depth images. We evaluate our object pose estimation approach on the ShapeNet dataset and show improvements over the state of the art. We also show that the estimated object pose results in 99.65% grasp accuracy with the ground truth grasp candidates on the Object Clutter Indoor Dataset (OCID) Grasp dataset, as computed using standard practice.
Shape-Graph Matching Network (SGM-net): Registration for Statistical Shape Analysis
Aug 14, 2023This paper focuses on the statistical analysis of shapes of data objects called shape graphs, a set of nodes connected by articulated curves with arbitrary shapes. A critical need here is a constrained registration of points (nodes to nodes, edges to edges) across objects. This, in turn, requires optimization over the permutation group, made challenging by differences in nodes (in terms of numbers, locations) and edges (in terms of shapes, placements, and sizes) across objects. This paper tackles this registration problem using a novel neural-network architecture and involves an unsupervised loss function developed using the elastic shape metric for curves. This architecture results in (1) state-of-the-art matching performance and (2) an order of magnitude reduction in the computational cost relative to baseline approaches. We demonstrate the effectiveness of the proposed approach using both simulated data and real-world 2D and 3D shape graphs. Code and data will be made publicly available after review to foster research.
Reducing Training Demands for 3D Gait Recognition with Deep Koopman Operator Constraints
Aug 14, 2023



Deep learning research has made many biometric recognition solution viable, but it requires vast training data to achieve real-world generalization. Unlike other biometric traits, such as face and ear, gait samples cannot be easily crawled from the web to form massive unconstrained datasets. As the human body has been extensively studied for different digital applications, one can rely on prior shape knowledge to overcome data scarcity. This work follows the recent trend of fitting a 3D deformable body model into gait videos using deep neural networks to obtain disentangled shape and pose representations for each frame. To enforce temporal consistency in the network, we introduce a new Linear Dynamical Systems (LDS) module and loss based on Koopman operator theory, which provides an unsupervised motion regularization for the periodic nature of gait, as well as a predictive capacity for extending gait sequences. We compare LDS to the traditional adversarial training approach and use the USF HumanID and CASIA-B datasets to show that LDS can obtain better accuracy with less training data. Finally, we also show that our 3D modeling approach is much better than other 3D gait approaches in overcoming viewpoint variation under normal, bag-carrying and clothing change conditions.
Learning Actor-centered Representations for Action Localization in Streaming Videos using Predictive Learning
Apr 29, 2021
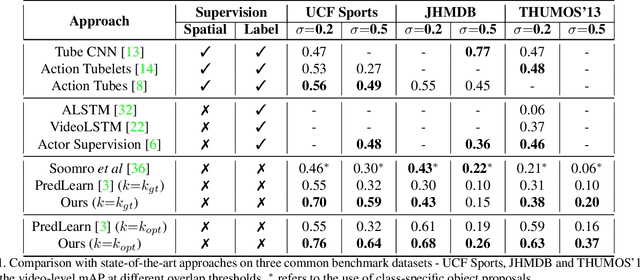

Event perception tasks such as recognizing and localizing actions in streaming videos are essential for tackling visual understanding tasks. Progress has primarily been driven by the use of large-scale, annotated training data in a supervised manner. In this work, we tackle the problem of learning \textit{actor-centered} representations through the notion of continual hierarchical predictive learning to localize actions in streaming videos without any training annotations. Inspired by cognitive theories of event perception, we propose a novel, self-supervised framework driven by the notion of hierarchical predictive learning to construct actor-centered features by attention-based contextualization. Extensive experiments on three benchmark datasets show that the approach can learn robust representations for localizing actions using only one epoch of training, i.e., we train the model continually in streaming fashion - one frame at a time, with a single pass through training videos. We show that the proposed approach outperforms unsupervised and weakly supervised baselines while offering competitive performance to fully supervised approaches. Finally, we show that the proposed model can generalize to out-of-domain data without significant loss in performance without any finetuning for both the recognition and localization tasks.
Measuring economic activity from space: a case study using flying airplanes and COVID-19
Apr 21, 2021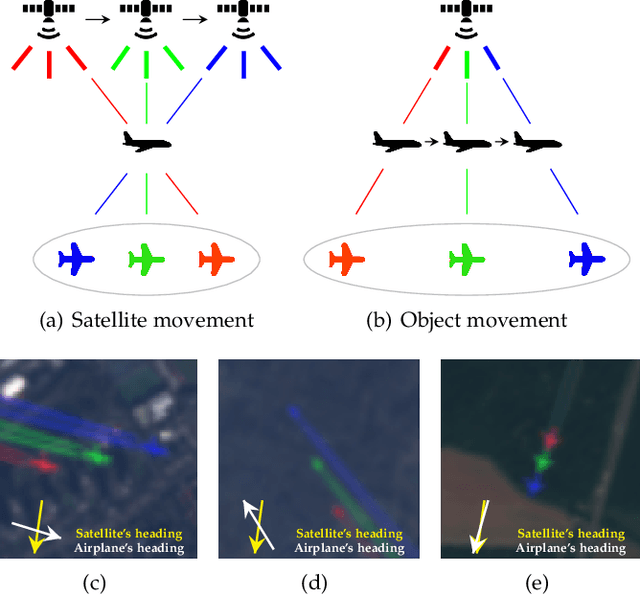
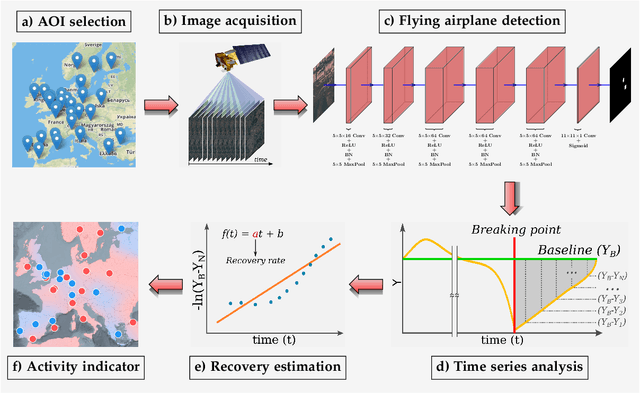
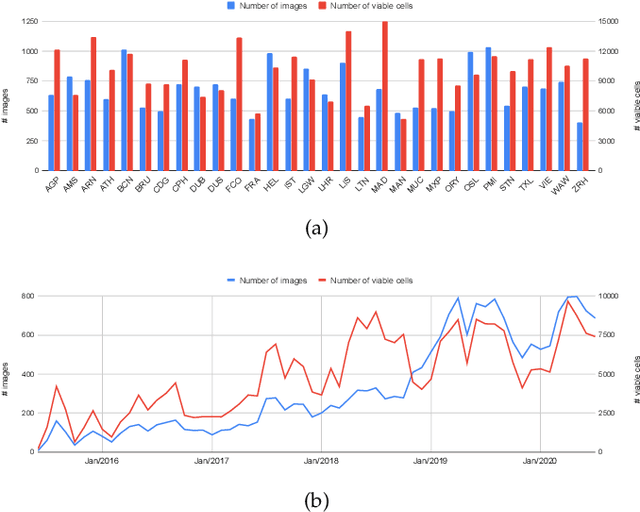
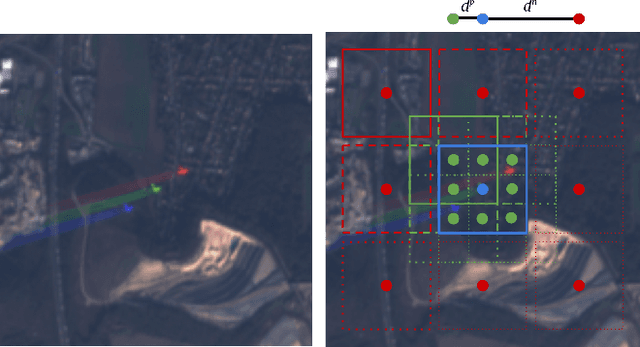
This work introduces a novel solution to measure economic activity through remote sensing for a wide range of spatial areas. We hypothesized that disturbances in human behavior caused by major life-changing events leave signatures in satellite imagery that allows devising relevant image-based indicators to estimate their impacts and support decision-makers. We present a case study for the COVID-19 coronavirus outbreak, which imposed severe mobility restrictions and caused worldwide disruptions, using flying airplane detection around the 30 busiest airports in Europe to quantify and analyze the lockdown's effects and post-lockdown recovery. Our solution won the Rapid Action Coronavirus Earth observation (RACE) upscaling challenge, sponsored by the European Space Agency and the European Commission, and now integrates the RACE dashboard. This platform combines satellite data and artificial intelligence to promote a progressive and safe reopening of essential activities. Code and CNN models are available at https://github.com/maups/covid19-custom-script-contest
Temporal Event Segmentation using Attention-based Perceptual Prediction Model for Continual Learning
May 07, 2020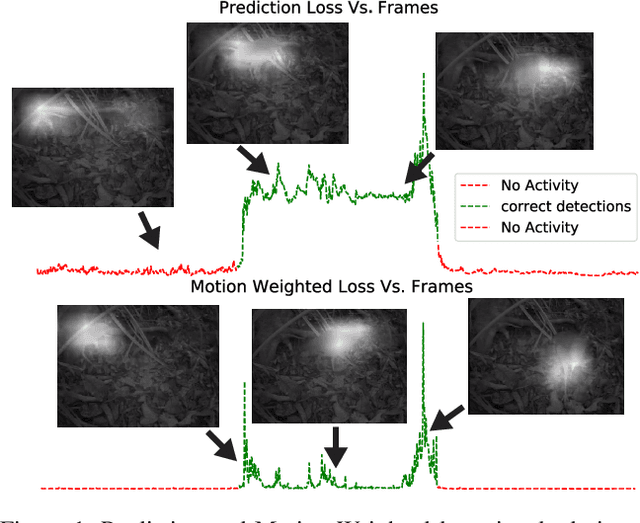


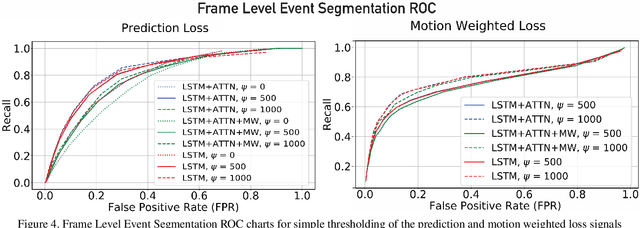
Temporal event segmentation of a long video into coherent events requires a high level understanding of activities' temporal features. The event segmentation problem has been tackled by researchers in an offline training scheme, either by providing full, or weak, supervision through manually annotated labels or by self-supervised epoch based training. In this work, we present a continual learning perceptual prediction framework (influenced by cognitive psychology) capable of temporal event segmentation through understanding of the underlying representation of objects within individual frames. Our framework also outputs attention maps which effectively localize and track events-causing objects in each frame. The model is tested on a wildlife monitoring dataset in a continual training manner resulting in $80\%$ recall rate at $20\%$ false positive rate for frame level segmentation. Activity level testing has yielded $80\%$ activity recall rate for one false activity detection every 50 minutes.
Measuring Human and Economic Activity from Satellite Imagery to Support City-Scale Decision-Making during COVID-19 Pandemic
Apr 16, 2020
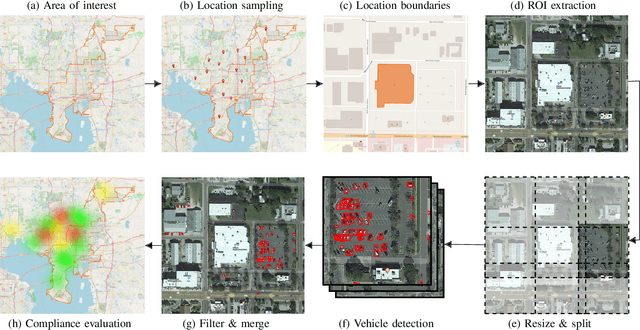
The COVID-19 outbreak forced governments worldwide to impose lockdowns and quarantines over their population to prevent virus transmission. As a consequence, there are disruptions in human and economic activities all over the globe. The recovery process is also expected to be rough. Economic activities impact social behaviors, which leave signatures in satellite images that can be automatically detected and classified. Satellite imagery can support the decision-making of analysts and policymakers by providing a different kind of visibility into the unfolding economic changes. Such information can be useful both during the crisis and also as we recover from it. In this work, we use a deep learning approach that combines strategic location sampling and an ensemble of lightweight convolutional neural networks (CNNs) to recognize specific elements in satellite images and compute economic indicators based on it, automatically. This CNN ensemble framework ranked third place in the US Department of Defense xView challenge, the most advanced benchmark for object detection in satellite images. We show the potential of our framework for temporal analysis using the US IARPA Function Map of the World (fMoW) dataset. We also show results on real examples of different sites before and after the COVID-19 outbreak to demonstrate possibilities. Among the future work is the possibility that with a satellite image dataset that samples a region at a weekly (or biweekly) frequency, we can generate more informative temporal signatures that can predict future economic states. Our code is being made available at https://github.com/maups/covid19-satellite-analysis
Action Localization through Continual Predictive Learning
Mar 26, 2020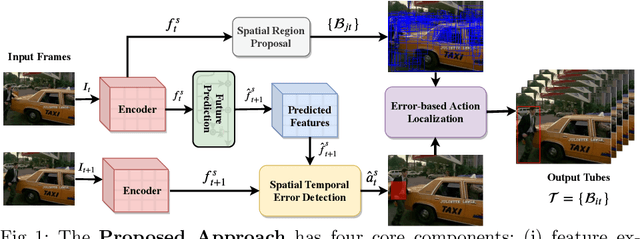

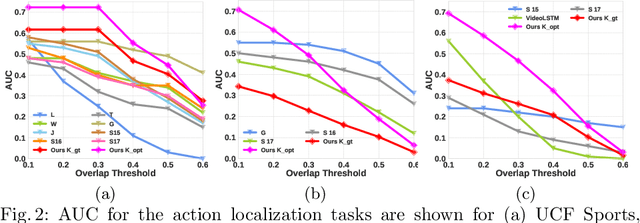
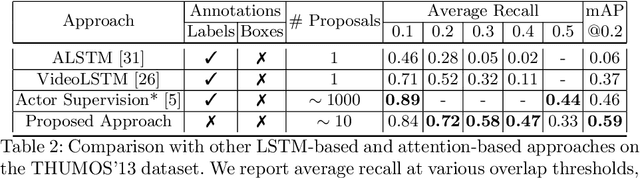
The problem of action recognition involves locating the action in the video, both over time and spatially in the image. The dominant current approaches use supervised learning to solve this problem, and require large amounts of annotated training data, in the form of frame-level bounding box annotations around the region of interest. In this paper, we present a new approach based on continual learning that uses feature-level predictions for self-supervision. It does not require any training annotations in terms of frame-level bounding boxes. The approach is inspired by cognitive models of visual event perception that propose a prediction-based approach to event understanding. We use a stack of LSTMs coupled with CNN encoder, along with novel attention mechanisms, to model the events in the video and use this model to predict high-level features for the future frames. The prediction errors are used to continuously learn the parameters of the models. This self-supervised framework is not complicated as other approaches but is very effective in learning robust visual representations for both labeling and localization. It should be noted that the approach outputs in a streaming fashion, requiring only a single pass through the video, making it amenable for real-time processing. We demonstrate this on three datasets - UCF Sports, JHMDB, and THUMOS'13 and show that the proposed approach outperforms weakly-supervised and unsupervised baselines and obtains competitive performance compared to fully supervised baselines. Finally, we show that the proposed framework can generalize to egocentric videos and obtain state-of-the-art results in unsupervised gaze prediction.
A Quotient Space Formulation for Statistical Analysis of Graphical Data
Sep 30, 2019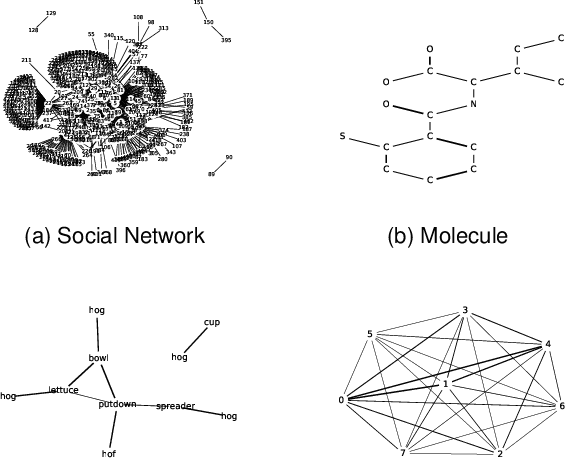

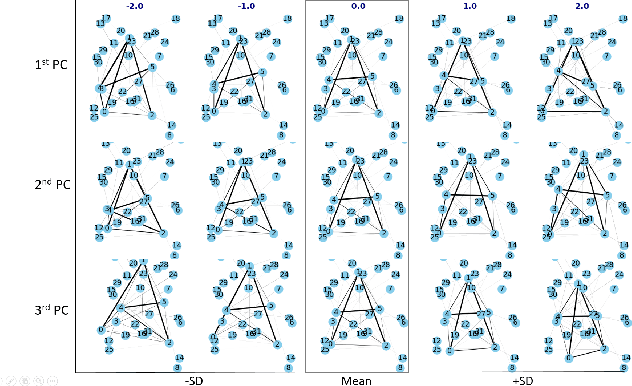
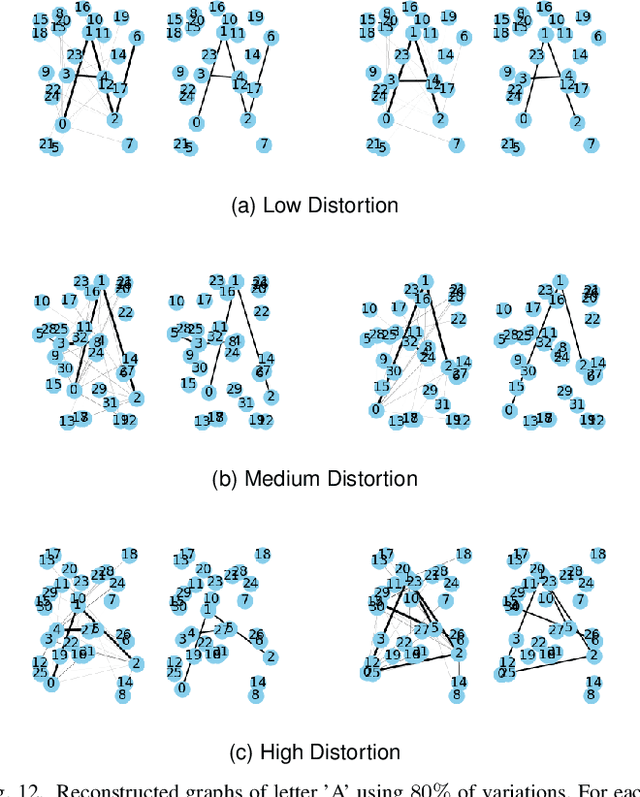
Complex analyses involving multiple, dependent random quantities often lead to graphical models: a set of nodes denoting variables of interest, and corresponding edges denoting statistical interactions between nodes. To develop statistical analyses for graphical data, one needs mathematical representations and metrics for matching and comparing graphs, and other geometrical tools, such as geodesics, means, and covariances, on representation spaces of graphs. This paper utilizes a quotient structure to develop efficient algorithms for computing these quantities, leading to useful statistical tools, including principal component analysis, linear dimension reduction, and analytical statistical modeling. The efficacy of this framework is demonstrated using datasets taken from several problem areas, including alphabets, video summaries, social networks, and biochemical structures.