 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Wise Multimodal Contrastive Learning for Remote Sensing Images
Jan 07, 2026Satellites continuously generate massive volumes of data, particularly for Earth observation, including satellite image time series (SITS). However, most deep learning models are designed to process either entire images or complete time series sequences to extract meaningful features for downstream tasks. In this study, we propose a novel multimodal approach that leverages pixel-wise two-dimensional (2D) representations to encode visual property variations from SITS more effectively. Specifically, we generate recurrence plots from pixel-based vegetation index time series (NDVI, EVI, and SAVI) as an alternative to using raw pixel values, creating more informative representations. Additionally, we introduce PIxel-wise Multimodal Contrastive (PIMC), a new multimodal self-supervision approach that produces effective encoders based on two-dimensional pixel time series representations and remote sensing imagery (RSI). To validate our approach, we assess its performance on three downstream tasks: pixel-level forecasting and classification using the PASTIS dataset, and land cover classification on the EuroSAT dataset. Moreover, we compare our results to state-of-the-art (SOTA) methods on all downstream tasks. Our experimental results show that the use of 2D representations significantly enhances feature extraction from SITS, while contrastive learning improves the quality of representations for both pixel time series and RSI. These findings suggest that our multimodal method outperforms existing models in various Earth observation tasks, establishing it as a robust self-supervision framework for processing both SITS and RSI. Code avaliable on
Data Driven Discovery of Emergent Dynamics in Reaction Diffusion Systems from Sparse and Noisy Observations
Sep 11, 2025Data-driven discovery of emergent dynamics is gaining popularity, particularly in the context of reaction-diffusion systems. These systems are widely studied across various fields, including neuroscience, ecology, epidemiology, and several other subject areas that deal with emergent dynamics. A current challenge in the discovery process relates to system identification when there is no prior knowledge of the underlying physics. We attempt to address this challenge by learning Soft Artificial Life (Soft ALife) models, such as Agent-based and Cellular Automata (CA) models, from observed data for reaction-diffusion systems. In this paper, we present findings on the applicability of a conceptual framework, the Data-driven Rulesets for Soft Artificial Life (DRSALife) model, to learn Soft ALife rulesets that accurately represent emergent dynamics in a reaction-diffusion system from observed data. This model has demonstrated promising results for Elementary CA Rule 30, Game of Life, and Vicsek Flocking problems in recent work. To our knowledge, this is one of the few studies that explore machine-based Soft ALife ruleset learning and system identification for reaction-diffusion dynamics without any prior knowledge of the underlying physics. Moreover, we provide comprehensive findings from experiments investigating the potential effects of using noisy and sparse observed datasets on learning emergent dynamics. Additionally, we successfully identify the structure and parameters of the underlying partial differential equations (PDEs) representing these dynamics. Experimental results demonstrate that the learned models are able to predict the emergent dynamics with good accuracy (74%) and exhibit quite robust performance when subjected to Gaussian noise and temporal sparsity.
Data-driven Intra-Autonomous Systems Graph Generator
Aug 09, 2023This paper introduces a novel deep-learning based generator of synthetic graphs that represent intra-Autonomous System (AS) in the Internet, named Deep-generative graphs for the Internet (DGGI). It also presents a novel massive dataset of real intra-AS graphs extracted from the project Internet Topology Data Kit (ITDK), called Internet Graphs (IGraphs). To create IGraphs, the Filtered Recurrent Multi-level (FRM) algorithm for community extraction was developed. It is shown that DGGI creates synthetic graphs which accurately reproduce the properties of centrality, clustering, assortativity, and node degree. The DGGI generator overperforms existing Internet topology generators. On average, DGGI improves the Maximum Mean Discrepancy (MMD) metric 84.4%, 95.1%, 97.9%, and 94.7% for assortativity, betweenness, clustering, and node degree, respectively.
Measuring economic activity from space: a case study using flying airplanes and COVID-19
Apr 21, 2021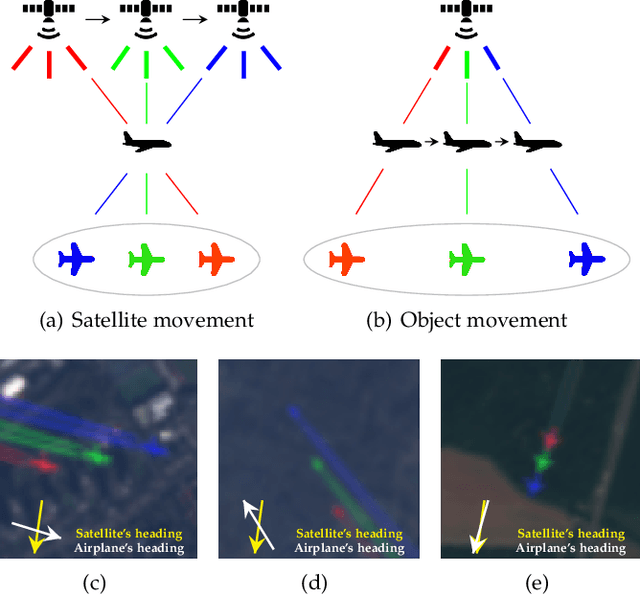
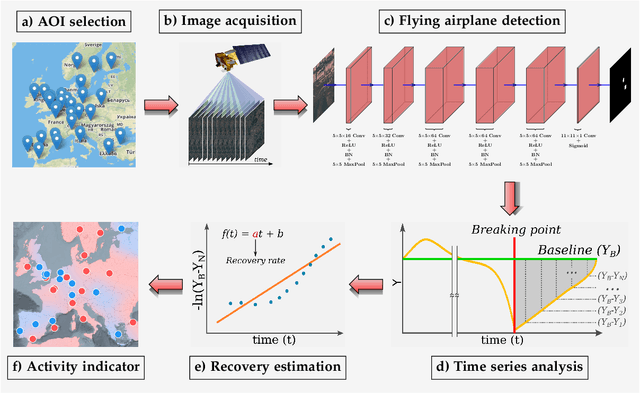
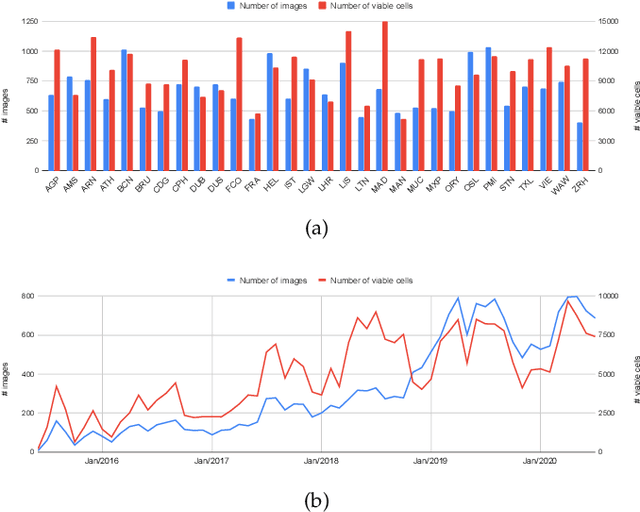
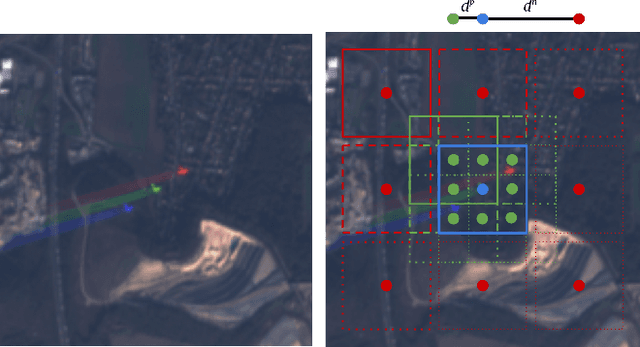
This work introduces a novel solution to measure economic activity through remote sensing for a wide range of spatial areas. We hypothesized that disturbances in human behavior caused by major life-changing events leave signatures in satellite imagery that allows devising relevant image-based indicators to estimate their impacts and support decision-makers. We present a case study for the COVID-19 coronavirus outbreak, which imposed severe mobility restrictions and caused worldwide disruptions, using flying airplane detection around the 30 busiest airports in Europe to quantify and analyze the lockdown's effects and post-lockdown recovery. Our solution won the Rapid Action Coronavirus Earth observation (RACE) upscaling challenge, sponsored by the European Space Agency and the European Commission, and now integrates the RACE dashboard. This platform combines satellite data and artificial intelligence to promote a progressive and safe reopening of essential activities. Code and CNN models are available at https://github.com/maups/covid19-custom-script-contest
Multimodal Representation Model based on Graph-Based Rank Fusion
Feb 04, 2020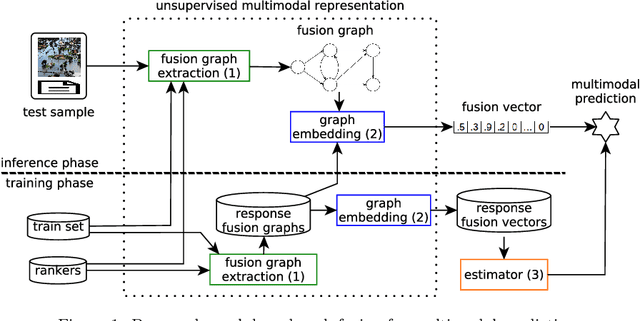

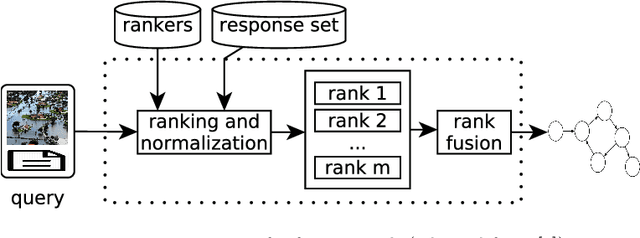
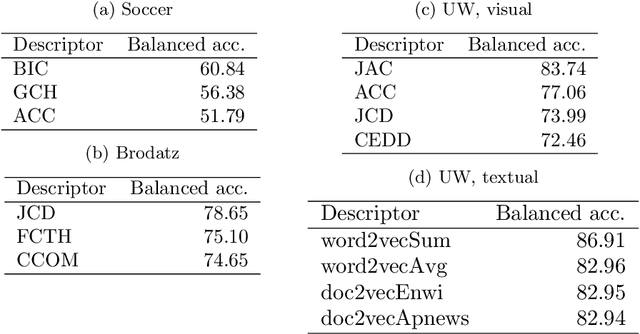
This paper proposes an unsupervised representation model, based on rank-fusion graphs, for general applicability in multimodal tasks, either unsupervised or supervised prediction. Rank-fusion graphs encode information from multiple descriptors and retrieval models, thus being able to capture underlying relationships between modalities, samples, and the collection itself. By doing so, our method is able to promote a fusion model better than either early-fusion and late-fusion alternatives. The solution is based on the encoding of multiple ranks of a query, defined according to different criteria, into a graph. Later, we embed the generated graph into a feature space, creating fusion vectors. Those embeddings are employed to build an estimator that infers whether an input (even multimodal) object refers to a class (or event) or not. Performed experiments in the context of multiple multimodal and visual datasets, evaluated on several descriptors and retrieval models, demonstrate that our representation model is highly effective for different detection scenarios involving visual, textual, and multimodal features, yielding better detection results than state-of-the-art methods.
Fusion vectors: Embedding Graph Fusions for Efficient Unsupervised Rank Aggregation
Jul 02, 2019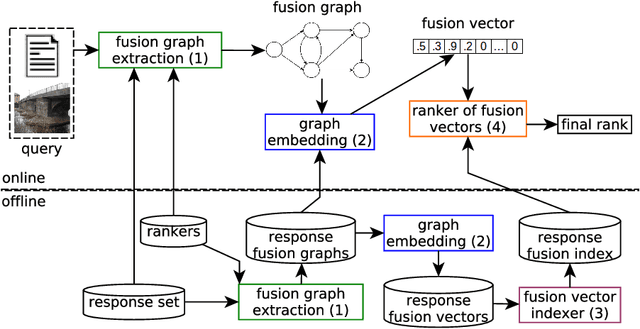

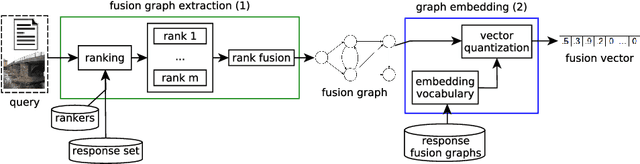

The vast increase in amount and complexity of digital content led to a wide interest in ad-hoc retrieval systems in recent years. Complementary, the existence of heterogeneous data sources and retrieval models stimulated the proliferation of increasingly ingenious and effective rank aggregation functions. Although recently proposed rank aggregation functions are promising with respect to effectiveness, existing proposals in the area usually overlook efficiency aspects. We propose an innovative rank aggregation function that is unsupervised, intrinsically multimodal, and targeted for fast retrieval and top effectiveness performance. We introduce the concepts of embedding and indexing of graph-based rank-aggregation representation models, and their application for search tasks. Embedding formulations are also proposed for graph-based rank representations. We introduce the concept of fusion vectors, a late-fusion representation of objects based on ranks, from which an intrinsically rank-aggregation retrieval model is defined. Next, we present an approach for fast retrieval based on fusion vectors, thus promoting an efficient rank aggregation system. Our method presents top effectiveness performance among state-of-the-art related work, while bringing novel aspects of multimodality and effectiveness. Consistent speedups are achieved against the recent baselines in all datasets considered.
Unsupervised Graph-based Rank Aggregation for Improved Retrieval
Jan 17, 2019
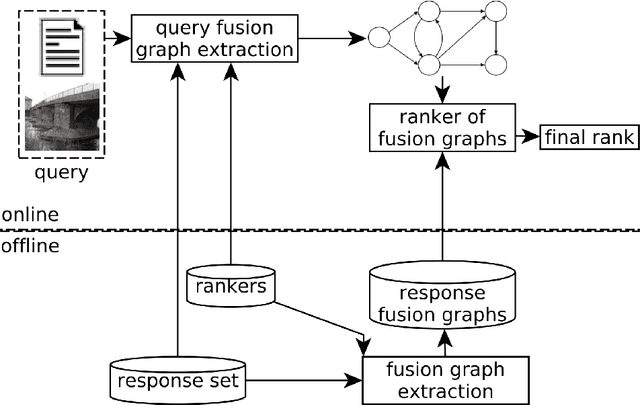
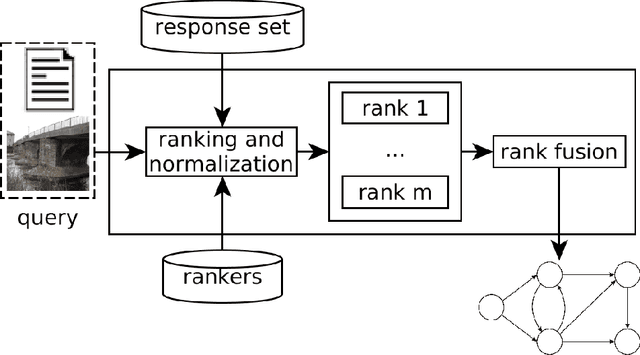
This paper presents a robust and comprehensive graph-based rank aggregation approach, used to combine results of isolated ranker models in retrieval tasks. The method follows an unsupervised scheme, which is independent of how the isolated ranks are formulated. Our approach is able to combine arbitrary models, defined in terms of different ranking criteria, such as those based on textual, image or hybrid content representations. We reformulate the ad-hoc retrieval problem as a document retrieval of their fusion graph, which we propose as a new unified representation model capable of merging multiple ranks and expressing inter-relationships of retrieval results automatically. By doing so, we claim that the retrieval system can benefit from learning the manifold structure of datasets, thus leading to more effective results. Another contribution is that our graph-based aggregation formulation, unlike existing approaches, allows for encapsulating contextual information encoded from multiple ranks, which can be directly used for ranking, without further computations and processing steps over the graphs. Based on the graphs, a novel similarity retrieval score is formulated using an efficient computation of minimum common subgraphs. Finally, another benefit over existing approaches is the absence of hyperparameters. A comprehensive experimental evaluation was conducted considering diverse well-known public datasets, composed of textual, image, and multimodal documents. Performed experiments demonstrate that our method reaches top performance, yielding better effectiveness scores than state-of-the-art baseline methods and promoting large gains over the rankers being fused, thus showing the successful capability of the proposal in representing queries based on a unified graph-based model of rank fusions.
Bayesian approach for near-duplicate image detection
Apr 25, 2011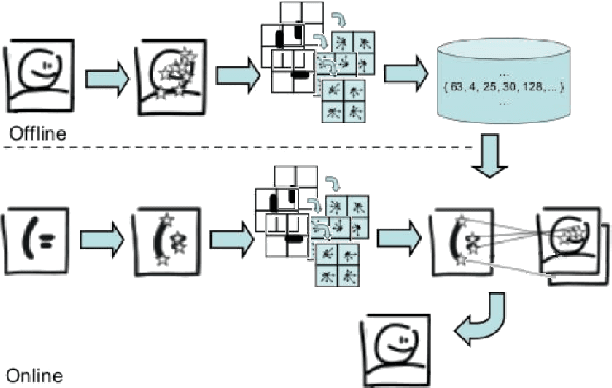
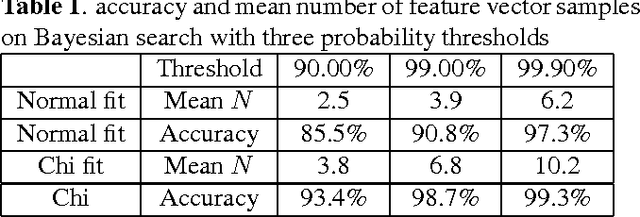


In this paper we propose a bayesian approach for near-duplicate image detection, and investigate how different probabilistic models affect the performance obtained. The task of identifying an image whose metadata are missing is often demanded for a myriad of applications: metadata retrieval in cultural institutions, detection of copyright violations, investigation of latent cross-links in archives and libraries, duplicate elimination in storage management, etc. The majority of current solutions are based either on voting algorithms, which are very precise, but expensive; either on the use of visual dictionaries, which are efficient, but less precise. Our approach, uses local descriptors in a novel way, which by a careful application of decision theory, allows a very fine control of the compromise between precision and efficiency. In addition, the method attains a great compromise between those two axes, with more than 99% accuracy with less than 10 database operations.