 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Representation Model based on Graph-Based Rank Fusion
Feb 04, 2020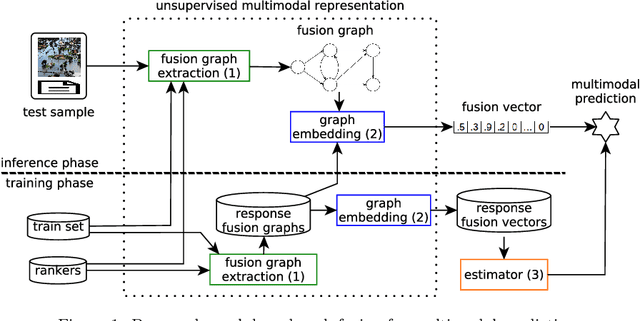

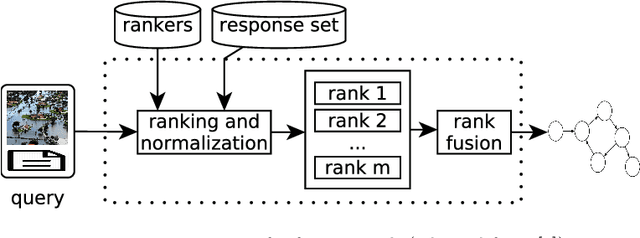
This paper proposes an unsupervised representation model, based on rank-fusion graphs, for general applicability in multimodal tasks, either unsupervised or supervised prediction. Rank-fusion graphs encode information from multiple descriptors and retrieval models, thus being able to capture underlying relationships between modalities, samples, and the collection itself. By doing so, our method is able to promote a fusion model better than either early-fusion and late-fusion alternatives. The solution is based on the encoding of multiple ranks of a query, defined according to different criteria, into a graph. Later, we embed the generated graph into a feature space, creating fusion vectors. Those embeddings are employed to build an estimator that infers whether an input (even multimodal) object refers to a class (or event) or not. Performed experiments in the context of multiple multimodal and visual datasets, evaluated on several descriptors and retrieval models, demonstrate that our representation model is highly effective for different detection scenarios involving visual, textual, and multimodal features, yielding better detection results than state-of-the-art methods.