 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multinational License Plate Recognition Through Synthetic and Real Data Fusion: A Comprehensive Evaluation
Jan 12, 2026Automatic License Plate Recognition is a frequent research topic due to its wide-ranging practical applications. While recent studies use synthetic images to improve License Plate Recognition (LPR) results, there remain several limitations in these efforts. This work addresses these constraints by comprehensively exploring the integration of real and synthetic data to enhance LPR performance. We subject 16 Optical Character Recognition (OCR) models to a benchmarking process involving 12 public datasets acquired from various regions. Several key findings emerge from our investigation. Primarily, the massive incorporation of synthetic data substantially boosts model performance in both intra- and cross-dataset scenarios. We examine three distinct methodologies for generating synthetic data: template-based generation, character permutation, and utilizing a Generative Adversarial Network (GAN) model, each contributing significantly to performance enhancement. The combined use of these methodologies demonstrates a notable synergistic effect, leading to end-to-end results that surpass those reached by state-of-the-art methods and established commercial systems. Our experiments also underscore the efficacy of synthetic data in mitigating challenges posed by limited training data, enabling remarkable results to be achieved even with small fractions of the original training data. Finally, we investigate the trade-off between accuracy and speed among different models, identifying those that strike the optimal balance in each intra-dataset and cross-dataset settings.
Do Multimodal LLMs See Sentiment?
Aug 23, 2025Understanding how visual content communicates sentiment is critical in an era where online interaction is increasingly dominated by this kind of media on social platforms. However, this remains a challenging problem, as sentiment perception is closely tied to complex, scene-level semantics. In this paper, we propose an original framework, MLLMsent, to investigate the sentiment reasoning capabilities of Multimodal Large Language Models (MLLMs) through three perspectives: (1) using those MLLMs for direct sentiment classification from images; (2) associating them with pre-trained LLMs for sentiment analysis on automatically generated image descriptions; and (3) fine-tuning the LLMs on sentiment-labeled image descriptions. Experiments on a recent and established benchmark demonstrate that our proposal, particularly the fine-tuned approach, achieves state-of-the-art results outperforming Lexicon-, CNN-, and Transformer-based baselines by up to 30.9%, 64.8%, and 42.4%, respectively, across different levels of evaluators' agreement and sentiment polarity categories. Remarkably, in a cross-dataset test, without any training on these new data, our model still outperforms, by up to 8.26%, the best runner-up, which has been trained directly on them. These results highlight the potential of the proposed visual reasoning scheme for advancing affective computing, while also establishing new benchmarks for future research.
Leveraging Model Fusion for Improved License Plate Recognition
Sep 08, 2023License Plate Recognition (LPR) plays a critical role in various applications, such as toll collection, parking management, and traffic law enforcement. Although LPR has witnessed significant advancements through the development of deep learning, there has been a noticeable lack of studies exploring the potential improvements in results by fusing the outputs from multiple recognition models. This research aims to fill this gap by investigating the combination of up to 12 different models using straightforward approaches, such as selecting the most confident prediction or employing majority vote-based strategies. Our experiments encompass a wide range of datasets, revealing substantial benefits of fusion approaches in both intra- and cross-dataset setups. Essentially, fusing multiple models reduces considerably the likelihood of obtaining subpar performance on a particular dataset/scenario. We also found that combining models based on their speed is an appealing approach. Specifically, for applications where the recognition task can tolerate some additional time, though not excessively, an effective strategy is to combine 4-6 models. These models may not be the most accurate individually, but their fusion strikes an optimal balance between accuracy and speed.
Do We Train on Test Data? The Impact of Near-Duplicates on License Plate Recognition
Apr 10, 2023This work draws attention to the large fraction of near-duplicates in the training and test sets of datasets widely adopted in License Plate Recognition (LPR) research. These duplicates refer to images that, although different, show the same license plate. Our experiments, conducted on the two most popular datasets in the field, show a substantial decrease in recognition rate when six well-known models are trained and tested under fair splits, that is, in the absence of duplicates in the training and test sets. Moreover, in one of the datasets, the ranking of models changed considerably when they were trained and tested under duplicate-free splits. These findings suggest that such duplicates have significantly biased the evaluation and development of deep learning-based models for LPR. The list of near-duplicates we have found and proposals for fair splits are publicly available for further research at https://raysonlaroca.github.io/supp/lpr-train-on-test/
Measuring economic activity from space: a case study using flying airplanes and COVID-19
Apr 21, 2021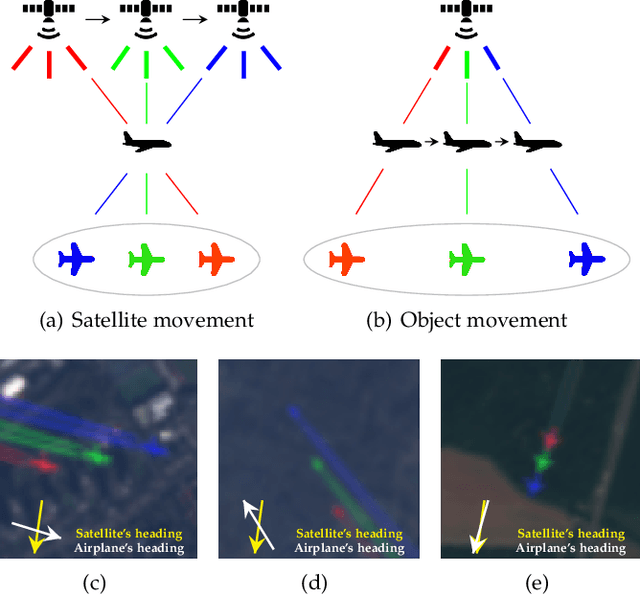
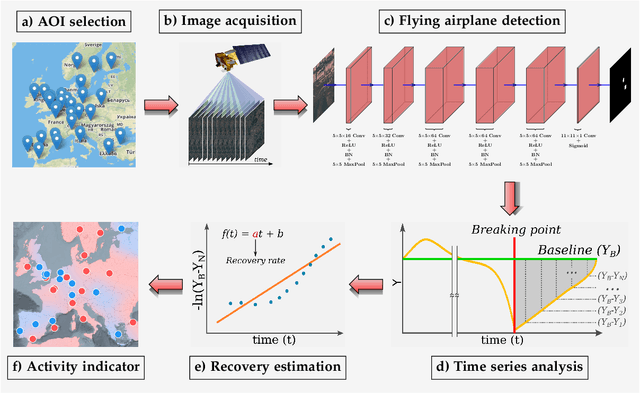
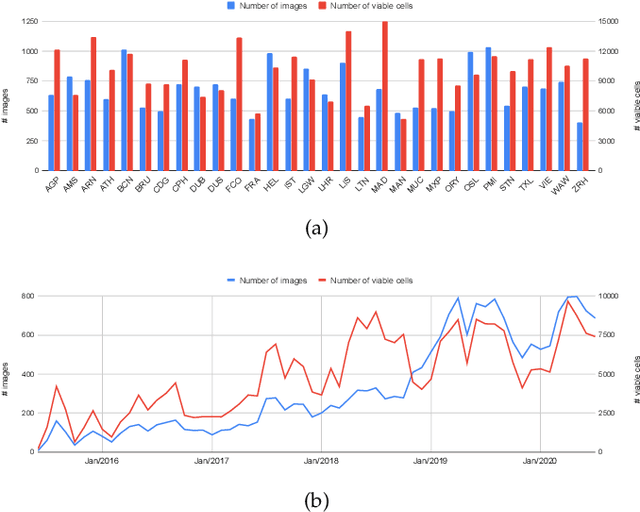
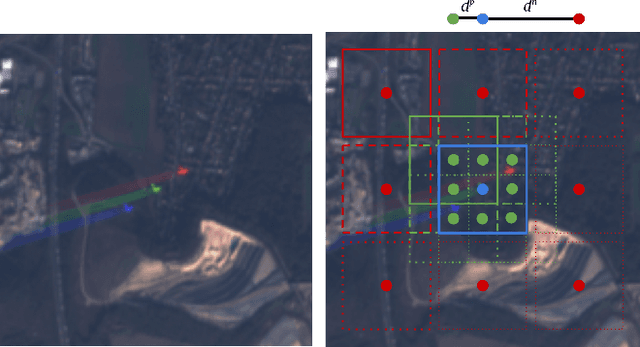
This work introduces a novel solution to measure economic activity through remote sensing for a wide range of spatial areas. We hypothesized that disturbances in human behavior caused by major life-changing events leave signatures in satellite imagery that allows devising relevant image-based indicators to estimate their impacts and support decision-makers. We present a case study for the COVID-19 coronavirus outbreak, which imposed severe mobility restrictions and caused worldwide disruptions, using flying airplane detection around the 30 busiest airports in Europe to quantify and analyze the lockdown's effects and post-lockdown recovery. Our solution won the Rapid Action Coronavirus Earth observation (RACE) upscaling challenge, sponsored by the European Space Agency and the European Commission, and now integrates the RACE dashboard. This platform combines satellite data and artificial intelligence to promote a progressive and safe reopening of essential activities. Code and CNN models are available at https://github.com/maups/covid19-custom-script-contest
Active Fire Detection in Landsat-8 Imagery: a Large-Scale Dataset and a Deep-Learning Study
Jan 09, 2021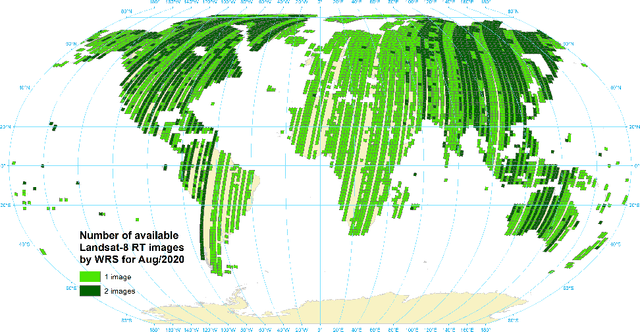
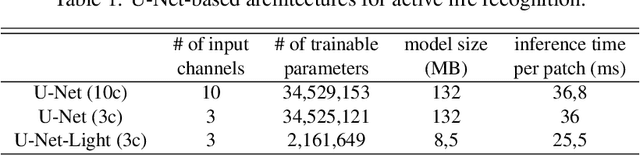

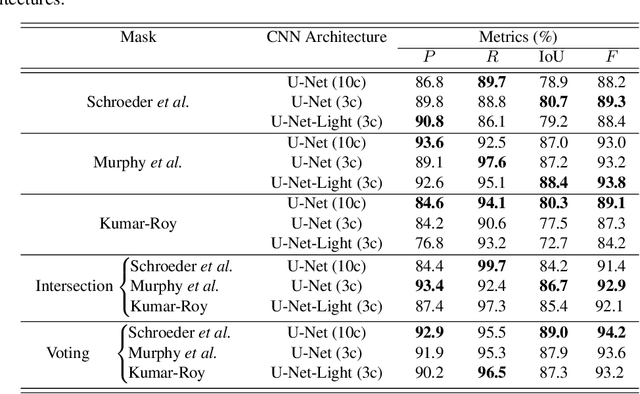
Active fire detection in satellite imagery is of critical importance to the management of environmental conservation policies, supporting decision-making and law enforcement. This is a well established field, with many techniques being proposed over the years, usually based on pixel or region-level comparisons involving sensor-specific thresholds and neighborhood statistics. In this paper, we address the problem of active fire detection using deep learning techniques. In recent years, deep learning techniques have been enjoying an enormous success in many fields, but their use for active fire detection is relatively new, with open questions and demand for datasets and architectures for evaluation. This paper addresses these issues by introducing a new large-scale dataset for active fire detection, with over 150,000 image patches (more than 200 GB of data) extracted from Landsat-8 images captured around the world in August and September 2020, containing wildfires in several locations. The dataset was split in two parts, and contains 10-band spectral images with associated outputs, produced by three well known handcrafted algorithms for active fire detection in the first part, and manually annotated masks in the second part. We also present a study on how different convolutional neural network architectures can be used to approximate these handcrafted algorithms, and how models trained on automatically segmented patches can be combined to achieve better performance than the original algorithms - with the best combination having 87.2% precision and 92.4% recall on our manually annotated dataset. The proposed dataset, source codes and trained models are available on Github (https://github.com/pereira-gha/activefire), creating opportunities for further advances in the field
Measuring Human and Economic Activity from Satellite Imagery to Support City-Scale Decision-Making during COVID-19 Pandemic
Apr 16, 2020
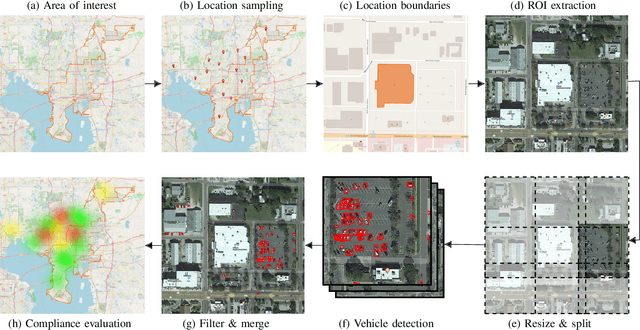
The COVID-19 outbreak forced governments worldwide to impose lockdowns and quarantines over their population to prevent virus transmission. As a consequence, there are disruptions in human and economic activities all over the globe. The recovery process is also expected to be rough. Economic activities impact social behaviors, which leave signatures in satellite images that can be automatically detected and classified. Satellite imagery can support the decision-making of analysts and policymakers by providing a different kind of visibility into the unfolding economic changes. Such information can be useful both during the crisis and also as we recover from it. In this work, we use a deep learning approach that combines strategic location sampling and an ensemble of lightweight convolutional neural networks (CNNs) to recognize specific elements in satellite images and compute economic indicators based on it, automatically. This CNN ensemble framework ranked third place in the US Department of Defense xView challenge, the most advanced benchmark for object detection in satellite images. We show the potential of our framework for temporal analysis using the US IARPA Function Map of the World (fMoW) dataset. We also show results on real examples of different sites before and after the COVID-19 outbreak to demonstrate possibilities. Among the future work is the possibility that with a satellite image dataset that samples a region at a weekly (or biweekly) frequency, we can generate more informative temporal signatures that can predict future economic states. Our code is being made available at https://github.com/maups/covid19-satellite-analysis
Vehicle Re-identification: exploring feature fusion using multi-stream convolutional networks
Nov 13, 2019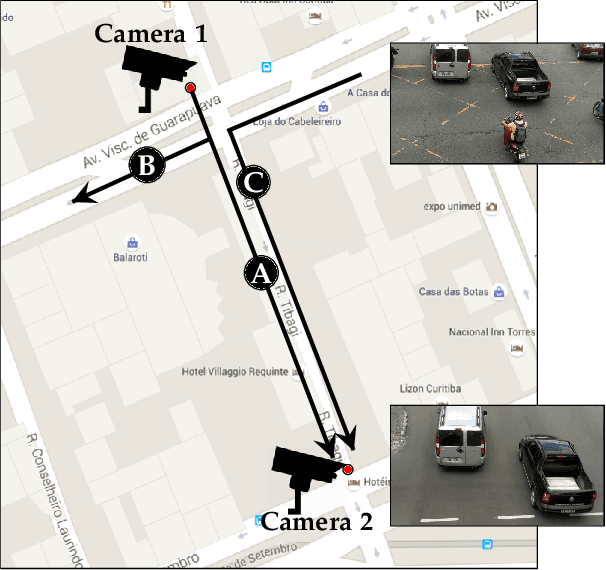

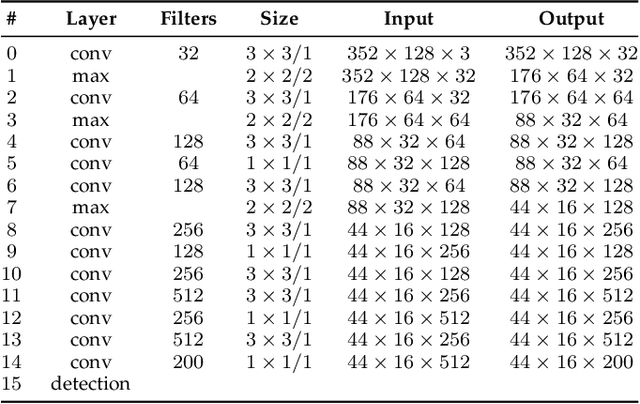
This work addresses the problem of vehicle re-identification through a network of non-overlapping cameras. As our main contribution, we propose a novel two-stream convolutional neural network (CNN) that simultaneously uses two of the most distinctive and persistent features available: the vehicle appearance and its license plate. This is an attempt to tackle a major problem, false alarms caused by vehicles with similar design or by very close license plate identifiers. In the first network stream, shape similarities are identified by a Siamese CNN that uses a pair of low-resolution vehicle patches recorded by two different cameras. In the second stream, we use a CNN for optical character recognition (OCR) to extract textual information, confidence scores, and string similarities from a pair of high-resolution license plate patches. Then, features from both streams are merged by a sequence of fully connected layers for decision. As part of this work, we created an important dataset for vehicle re-identification with more than three hours of videos spanning almost 3,000 vehicles. In our experiments, we achieved a precision, recall and F -score values of 99.6%, 99.2% and 99.4%, respectively. As another contribution, we discuss and compare three alternative architectures that explore the same features but using additional streams and temporal information. The proposed architectures, trained models, and dataset are publicly available at https://github.com/icarofua/vehicle-ReId .
OutdoorSent: Sentiment Analysis of Urban Outdoor Images by Using Semantic and Deep Features
Jun 08, 2019
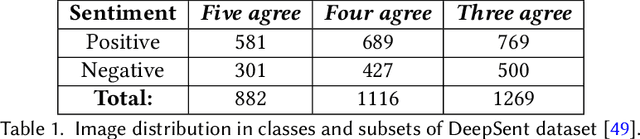
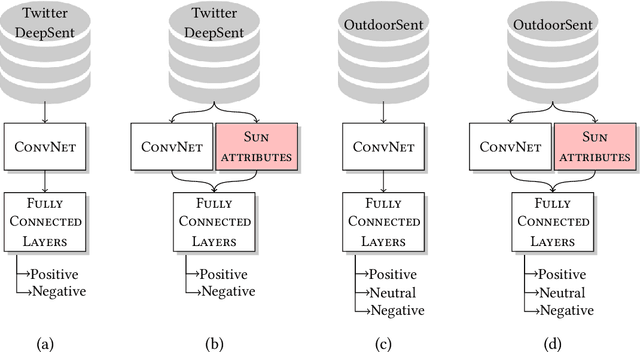
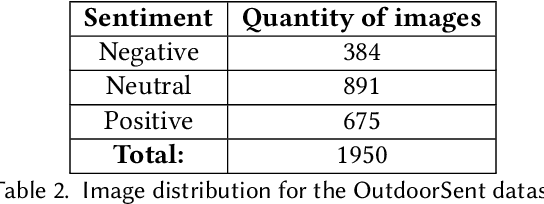
Opinion mining in outdoor images posted by users during day-to-day or leisure activities, for example, can provide valuable information to better understand urban areas. In this work, we propose a framework to classify the sentiment of outdoor images shared by users on social networks. We compare the performance of state-of-the-art ConvNet architectures, namely, VGG-16, Resnet50, and InceptionV3, as well as one specifically designed for sentiment analysis. The combination of such classifiers, a strategy known as ensemble, is also considered. We also use different experimental setups to evaluate how the merging of deep features and semantic information derived from the scene attributes can improve classification performance. The evaluation explores a novel dataset, namely OutdoorSent, of geolocalized urban outdoor images extracted from Instagram related to three sentiment polarities (positive, negative, and neutral), as well as another dataset publicly available (DeepSent). We observe that the incorporation of knowledge related to semantics features tend to improve the accuracy of low-complex ConvNet architectures. Furthermore, we also demonstrated the applicability of our results in the city of Chicago, United States, showing that they can help to understand the subjective characteristics of different areas of the city. For instance, particular areas of the city tend to concentrate more images of a specific class of sentiment. The ConvNet architectures, trained models, and the proposed outdoor image dataset will be publicly available at http://dainf.ct.utfpr.edu.br/outdoorsent.
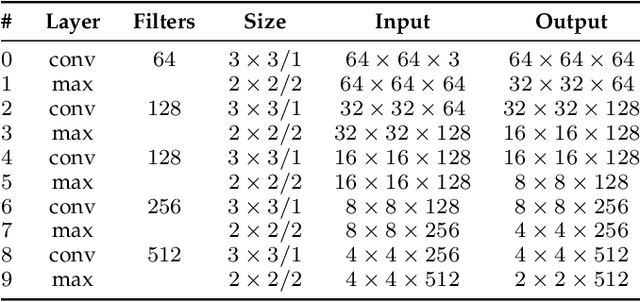
A Two-Stream Siamese Neural Network for Vehicle Re-Identification by Using Non-Overlapping Cameras
Apr 04, 2019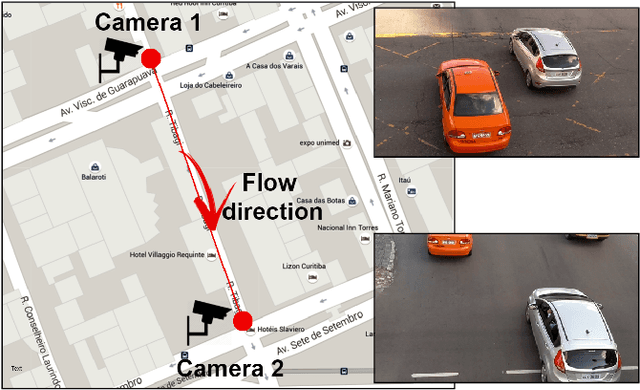
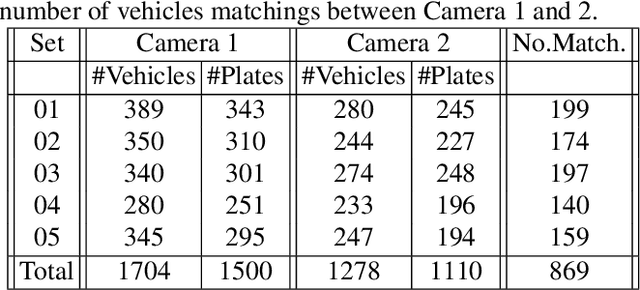
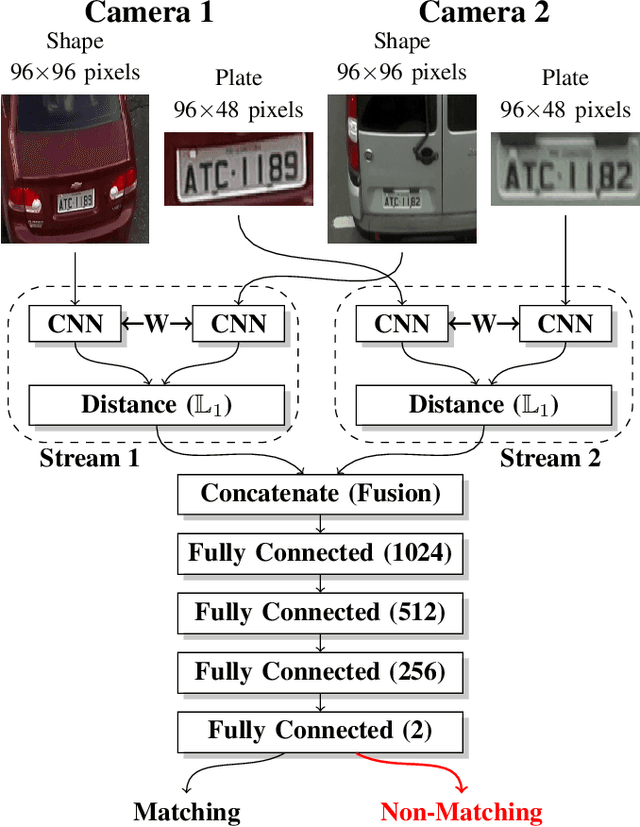
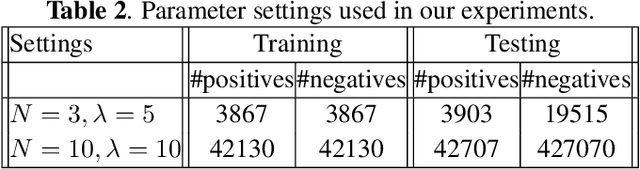
We describe in this paper a Two-Stream Siamese Neural Network for vehicle re-identification. The proposed network is fed simultaneously with small coarse patches of the vehicle shape's, with 96 x 96 pixels, in one stream, and fine features extracted from license plate patches, easily readable by humans, with 96 x 48 pixels, in the other one. Then, we combined the strengths of both streams by merging the Siamese distance descriptors with a sequence of fully connected layers, as an attempt to tackle a major problem in the field, false alarms caused by a huge number of car design and models with nearly the same appearance or by similar license plate strings. In our experiments, with 2 hours of videos containing 2982 vehicles, extracted from two low-cost cameras in the same roadway, 546 ft away, we achieved a F-measure and accuracy of 92.6% and 98.7%, respectively. We show that the proposed network, available at https://github.com/icarofua/siamese-two-stream, outperforms other One-Stream architectures, even if they use higher resolution image features.