 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multinational License Plate Recognition Through Synthetic and Real Data Fusion: A Comprehensive Evaluation
Jan 12, 2026Automatic License Plate Recognition is a frequent research topic due to its wide-ranging practical applications. While recent studies use synthetic images to improve License Plate Recognition (LPR) results, there remain several limitations in these efforts. This work addresses these constraints by comprehensively exploring the integration of real and synthetic data to enhance LPR performance. We subject 16 Optical Character Recognition (OCR) models to a benchmarking process involving 12 public datasets acquired from various regions. Several key findings emerge from our investigation. Primarily, the massive incorporation of synthetic data substantially boosts model performance in both intra- and cross-dataset scenarios. We examine three distinct methodologies for generating synthetic data: template-based generation, character permutation, and utilizing a Generative Adversarial Network (GAN) model, each contributing significantly to performance enhancement. The combined use of these methodologies demonstrates a notable synergistic effect, leading to end-to-end results that surpass those reached by state-of-the-art methods and established commercial systems. Our experiments also underscore the efficacy of synthetic data in mitigating challenges posed by limited training data, enabling remarkable results to be achieved even with small fractions of the original training data. Finally, we investigate the trade-off between accuracy and speed among different models, identifying those that strike the optimal balance in each intra-dataset and cross-dataset settings.
Less is more: concatenating videos for Sign Language Translation from a small set of signs
Sep 03, 2024The limited amount of labeled data for training the Brazilian Sign Language (Libras) to Portuguese Translation models is a challenging problem due to video collection and annotation costs. This paper proposes generating sign language content by concatenating short clips containing isolated signals for training Sign Language Translation models. We employ the V-LIBRASIL dataset, composed of 4,089 sign videos for 1,364 signs, interpreted by at least three persons, to create hundreds of thousands of sentences with their respective Libras translation, and then, to feed the model. More specifically, we propose several experiments varying the vocabulary size and sentence structure, generating datasets with approximately 170K, 300K, and 500K videos. Our results achieve meaningful scores of 9.2% and 26.2% for BLEU-4 and METEOR, respectively. Our technique enables the creation or extension of existing datasets at a much lower cost than the collection and annotation of thousands of sentences providing clear directions for future works.
Leveraging Model Fusion for Improved License Plate Recognition
Sep 08, 2023License Plate Recognition (LPR) plays a critical role in various applications, such as toll collection, parking management, and traffic law enforcement. Although LPR has witnessed significant advancements through the development of deep learning, there has been a noticeable lack of studies exploring the potential improvements in results by fusing the outputs from multiple recognition models. This research aims to fill this gap by investigating the combination of up to 12 different models using straightforward approaches, such as selecting the most confident prediction or employing majority vote-based strategies. Our experiments encompass a wide range of datasets, revealing substantial benefits of fusion approaches in both intra- and cross-dataset setups. Essentially, fusing multiple models reduces considerably the likelihood of obtaining subpar performance on a particular dataset/scenario. We also found that combining models based on their speed is an appealing approach. Specifically, for applications where the recognition task can tolerate some additional time, though not excessively, an effective strategy is to combine 4-6 models. These models may not be the most accurate individually, but their fusion strikes an optimal balance between accuracy and speed.
Do We Train on Test Data? The Impact of Near-Duplicates on License Plate Recognition
Apr 10, 2023



This work draws attention to the large fraction of near-duplicates in the training and test sets of datasets widely adopted in License Plate Recognition (LPR) research. These duplicates refer to images that, although different, show the same license plate. Our experiments, conducted on the two most popular datasets in the field, show a substantial decrease in recognition rate when six well-known models are trained and tested under fair splits, that is, in the absence of duplicates in the training and test sets. Moreover, in one of the datasets, the ranking of models changed considerably when they were trained and tested under duplicate-free splits. These findings suggest that such duplicates have significantly biased the evaluation and development of deep learning-based models for LPR. The list of near-duplicates we have found and proposals for fair splits are publicly available for further research at https://raysonlaroca.github.io/supp/lpr-train-on-test/
Global Semantic Descriptors for Zero-Shot Action Recognition
Sep 24, 2022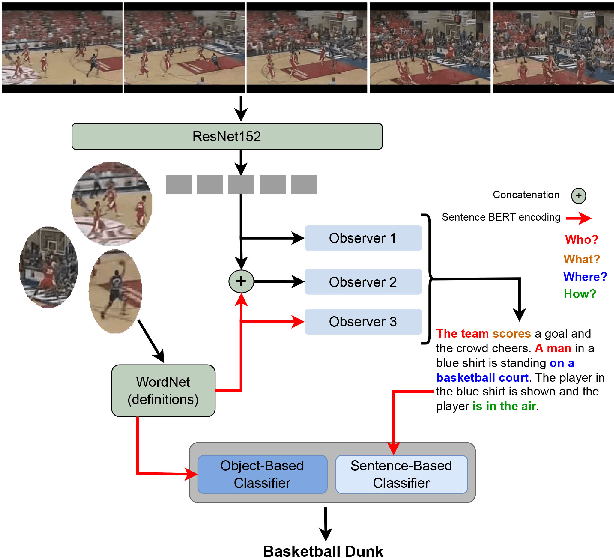
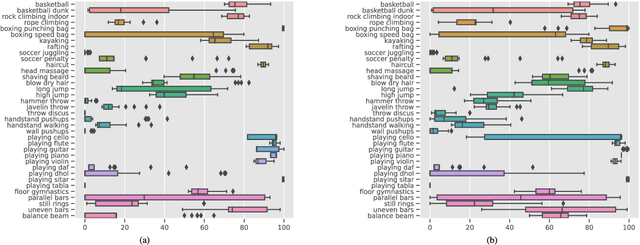

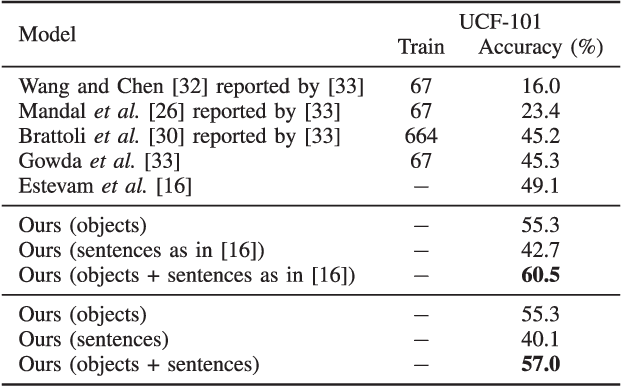
The success of Zero-shot Action Recognition (ZSAR) methods is intrinsically related to the nature of semantic side information used to transfer knowledge, although this aspect has not been primarily investigated in the literature. This work introduces a new ZSAR method based on the relationships of actions-objects and actions-descriptive sentences. We demonstrate that representing all object classes using descriptive sentences generates an accurate object-action affinity estimation when a paraphrase estimation method is used as an embedder. We also show how to estimate probabilities over the set of action classes based only on a set of sentences without hard human labeling. In our method, the probabilities from these two global classifiers (i.e., which use features computed over the entire video) are combined, producing an efficient transfer knowledge model for action classification. Our results are state-of-the-art in the Kinetics-400 dataset and are competitive on UCF-101 under the ZSAR evaluation. Our code is available at https://github.com/valterlej/objsentzsar
A First Look at Dataset Bias in License Plate Recognition
Aug 23, 2022



Public datasets have played a key role in advancing the state of the art in License Plate Recognition (LPR). Although dataset bias has been recognized as a severe problem in the computer vision community, it has been largely overlooked in the LPR literature. LPR models are usually trained and evaluated separately on each dataset. In this scenario, they have often proven robust in the dataset they were trained in but showed limited performance in unseen ones. Therefore, this work investigates the dataset bias problem in the LPR context. We performed experiments on eight datasets, four collected in Brazil and four in mainland China, and observed that each dataset has a unique, identifiable "signature" since a lightweight classification model predicts the source dataset of a license plate (LP) image with more than 95% accuracy. In our discussion, we draw attention to the fact that most LPR models are probably exploiting such signatures to improve the results achieved in each dataset at the cost of losing generalization capability. These results emphasize the importance of evaluating LPR models in cross-dataset setups, as they provide a better indication of generalization (hence real-world performance) than within-dataset ones.
On the Cross-dataset Generalization in License Plate Recognition
Jan 04, 2022
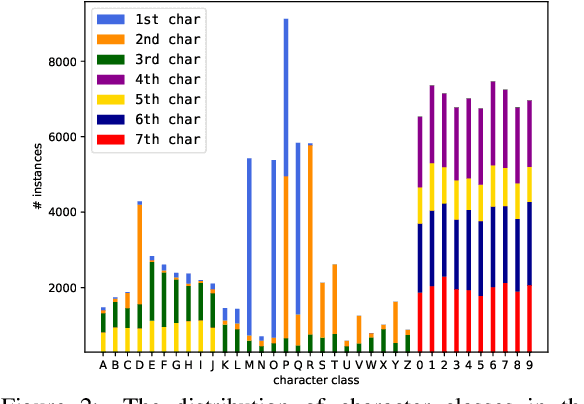
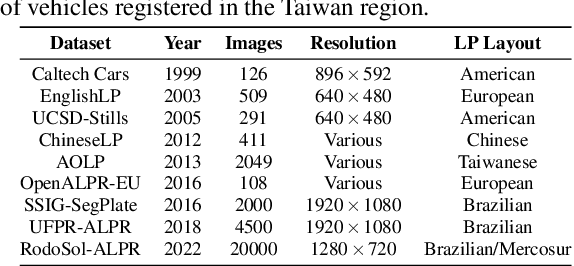
Automatic License Plate Recognition (ALPR) systems have shown remarkable performance on license plates (LPs) from multiple regions due to advances in deep learning and the increasing availability of datasets. The evaluation of deep ALPR systems is usually done within each dataset; therefore, it is questionable if such results are a reliable indicator of generalization ability. In this paper, we propose a traditional-split versus leave-one-dataset-out experimental setup to empirically assess the cross-dataset generalization of 12 Optical Character Recognition (OCR) models applied to LP recognition on nine publicly available datasets with a great variety in several aspects (e.g., acquisition settings, image resolution, and LP layouts). We also introduce a public dataset for end-to-end ALPR that is the first to contain images of vehicles with Mercosur LPs and the one with the highest number of motorcycle images. The experimental results shed light on the limitations of the traditional-split protocol for evaluating approaches in the ALPR context, as there are significant drops in performance for most datasets when training and testing the models in a leave-one-dataset-out fashion.
Tell me what you see: A zero-shot action recognition method based on natural language descriptions
Dec 18, 2021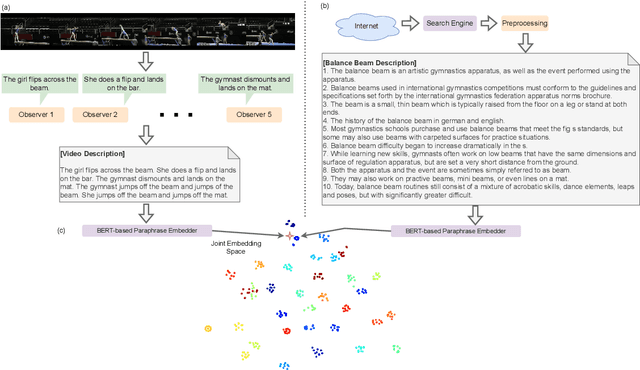
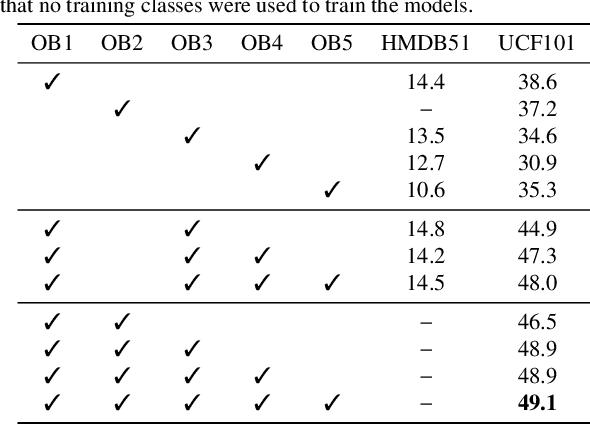

Recently, several approaches have explored the detection and classification of objects in videos to perform Zero-Shot Action Recognition with remarkable results. In these methods, class-object relationships are used to associate visual patterns with the semantic side information because these relationships also tend to appear in texts. Therefore, word vector methods would reflect them in their latent representations. Inspired by these methods and by video captioning's ability to describe events not only with a set of objects but with contextual information, we propose a method in which video captioning models, called observers, provide different and complementary descriptive sentences. We demonstrate that representing videos with descriptive sentences instead of deep features, in ZSAR, is viable and naturally alleviates the domain adaptation problem, as we reached state-of-the-art (SOTA) performance on the UCF101 dataset and competitive performance on HMDB51 without their training sets. We also demonstrate that word vectors are unsuitable for building the semantic embedding space of our descriptions. Thus, we propose to represent the classes with sentences extracted from documents acquired with search engines on the Internet, without any human evaluation on the quality of descriptions. Lastly, we build a shared semantic space employing BERT-based embedders pre-trained in the paraphrasing task on multiple text datasets. We show that this pre-training is essential for bridging the semantic gap. The projection onto this space is straightforward for both types of information, visual and semantic, because they are sentences, enabling the classification with nearest neighbour rule in this shared space. Our code is available at https://github.com/valterlej/zsarcap.
Dense Video Captioning Using Unsupervised Semantic Information
Dec 15, 2021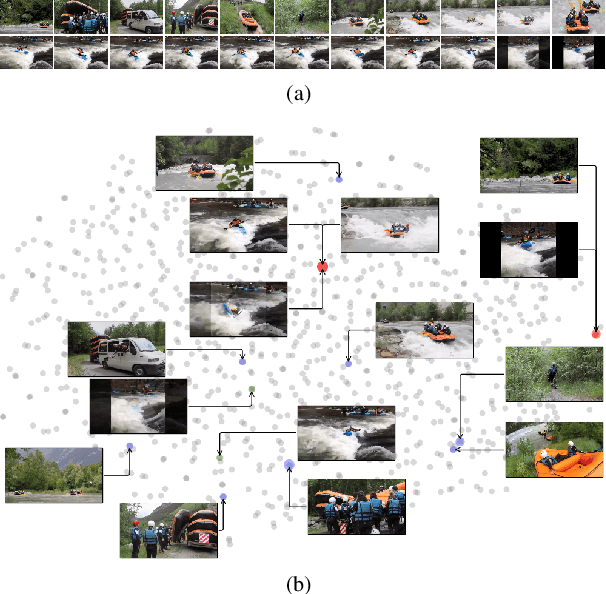
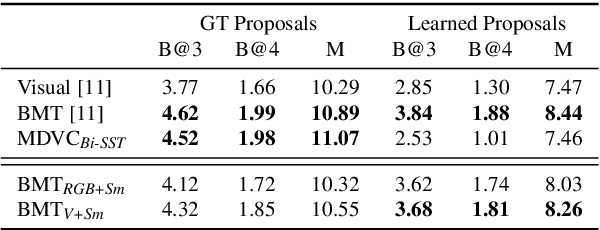
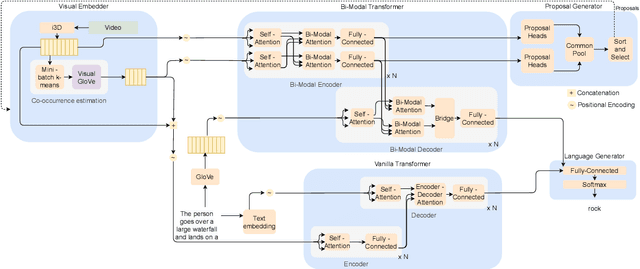

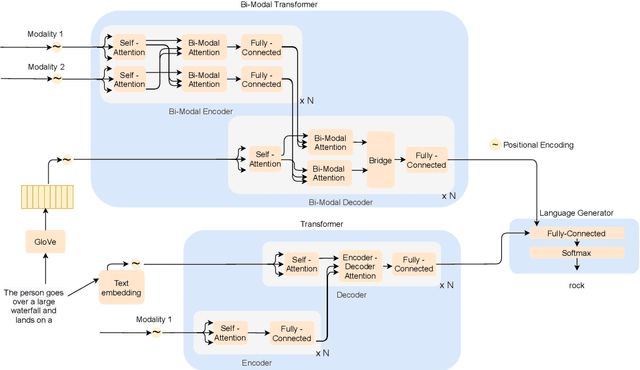
We introduce a method to learn unsupervised semantic visual information based on the premise that complex events (e.g., minutes) can be decomposed into simpler events (e.g., a few seconds), and that these simple events are shared across several complex events. We split a long video into short frame sequences to extract their latent representation with three-dimensional convolutional neural networks. A clustering method is used to group representations producing a visual codebook (i.e., a long video is represented by a sequence of integers given by the cluster labels). A dense representation is learned by encoding the co-occurrence probability matrix for the codebook entries. We demonstrate how this representation can leverage the performance of the dense video captioning task in a scenario with only visual features. As a result of this approach, we are able to replace the audio signal in the Bi-Modal Transformer (BMT) method and produce temporal proposals with comparable performance. Furthermore, we concatenate the visual signal with our descriptor in a vanilla transformer method to achieve state-of-the-art performance in captioning compared to the methods that explore only visual features, as well as a competitive performance with multi-modal methods. Our code is available at https://github.com/valterlej/dvcusi.