 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Vehicle Color Recognition in Long-Tailed Surveillance Scenarios
Jun 11, 2026Vehicle color recognition is an important cue for vehicle identification in surveillance systems, especially when license plates are illegible due to low resolution, occlusion, motion blur, or poor illumination. However, real-world vehicle color distributions are highly imbalanced, making overall accuracy insufficient to assess performance on rare but operationally relevant colors. This paper presents a comprehensive study of vehicle color recognition under severe class imbalance using UFPR-VeSV, a challenging real-world surveillance dataset. We investigate synthetic minority-class augmentation through two off-the-shelf generative strategies: text-conditioned image generation with RunDiffusion/JuggernautXL and image-conditioned color editing with Gemini 2.0 Flash. The curated synthetic data are combined with modern visual representations, loss reweighting, learning-rate scheduling, color-safe augmentation, foreground-aware preprocessing, and ensemble fusion. The bestperforming approach achieves 94.6% micro accuracy and 79.7% macro accuracy, improving macro accuracy by 8.2 percentage points over recent literature. A manual error analysis further shows that many remaining failures are visually ambiguous even for human annotators, highlighting the practical limits of color-based vehicle identification in unconstrained surveillance imagery. The generated images and source code are publicly available at https://github.com/viniciusorru/vcr-synthetic
ICPR 2026 Competition on Low-Resolution License Plate Recognition
Apr 24, 2026Low-Resolution License Plate Recognition (LRLPR) remains a challenging problem in real-world surveillance scenarios, where long capture distances, compression artifacts, and adverse imaging conditions can severely degrade license plate legibility. To promote progress in this area, we organized the ICPR 2026 Competition on Low-Resolution License Plate Recognition, the first competition specifically dedicated to LRLPR using real low-quality data collected under operationally relevant conditions. The competition was based on the LRLPR-26 dataset, which comprises 20,000 training tracks and 3,000 test tracks; each training track contains five low-resolution and five high-resolution images of the same license plate. Notably, a total of 269 teams from 41 countries registered for the competition, and 99 teams submitted valid entries in the Blind Test Phase. The winning team achieved a Recognition Rate of 82.13%, and four teams surpassed the 80% mark, highlighting both the high level of competition at the top of the leaderboard and the continued difficulty of the task. In addition to presenting the competition design, evaluation protocol, and main results, this paper summarizes the methods adopted by the top-5 teams and discusses current trends and promising directions for future research on LRLPR. The competition webpage is available at https://icpr26lrlpr.github.io/
LPLCv2: An Expanded Dataset for Fine-Grained License Plate Legibility Classification
Apr 09, 2026Modern Automatic License Plate Recognition (ALPR) systems achieve outstanding performance in controlled, well-defined scenarios. However, large-scale real-world usage remains challenging due to low-quality imaging devices, compression artifacts, and suboptimal camera installation. Identifying illegible license plates (LPs) has recently become feasible through a dedicated benchmark; however, its impact has been limited by its small size and annotation errors. In this work, we expand the original benchmark to over three times the size with two extra capture days, revise its annotations and introduce novel labels. LP-level annotations include bounding boxes, text, and legibility level, while vehicle-level annotations comprise make, model, type, and color. Image-level annotations feature camera identity, capture conditions (e.g., rain and faulty cameras), acquisition time, and day ID. We present a novel training procedure featuring an Exponential Moving Average-based loss function and a refined learning rate scheduler, addressing common mistakes in testing. These improvements enable a baseline model to achieve an 89.5% F1-score on the test set, considerably surpassing the previous state of the art. We further introduce a novel protocol to explicitly addresses camera contamination between training and evaluation splits, where results show a small impact. Dataset and code are publicly available at https://github.com/lmlwojcik/LPLCv2-Dataset.
Toward Unified Fine-Grained Vehicle Classification and Automatic License Plate Recognition
Apr 07, 2026Extracting vehicle information from surveillance images is essential for intelligent transportation systems, enabling applications such as traffic monitoring and criminal investigations. While Automatic License Plate Recognition (ALPR) is widely used, Fine-Grained Vehicle Classification (FGVC) offers a complementary approach by identifying vehicles based on attributes such as color, make, model, and type. Although there have been advances in this field, existing studies often assume well-controlled conditions, explore limited attributes, and overlook FGVC integration with ALPR. To address these gaps, we introduce UFPR-VeSV, a dataset comprising 24,945 images of 16,297 unique vehicles with annotations for 13 colors, 26 makes, 136 models, and 14 types. Collected from the Military Police of Paraná (Brazil) surveillance system, the dataset captures diverse real-world conditions, including partial occlusions, nighttime infrared imaging, and varying lighting. All FGVC annotations were validated using license plate information, with text and corner annotations also being provided. A qualitative and quantitative comparison with established datasets confirmed the challenging nature of our dataset. A benchmark using five deep learning models further validated this, revealing specific challenges such as handling multicolored vehicles, infrared images, and distinguishing between vehicle models that share a common platform. Additionally, we apply two optical character recognition models to license plate recognition and explore the joint use of FGVC and ALPR. The results highlight the potential of integrating these complementary tasks for real-world applications. The UFPR-VeSV dataset is publicly available at: https://github.com/Lima001/UFPR-VeSV-Dataset.
Advancing Multinational License Plate Recognition Through Synthetic and Real Data Fusion: A Comprehensive Evaluation
Jan 12, 2026Automatic License Plate Recognition is a frequent research topic due to its wide-ranging practical applications. While recent studies use synthetic images to improve License Plate Recognition (LPR) results, there remain several limitations in these efforts. This work addresses these constraints by comprehensively exploring the integration of real and synthetic data to enhance LPR performance. We subject 16 Optical Character Recognition (OCR) models to a benchmarking process involving 12 public datasets acquired from various regions. Several key findings emerge from our investigation. Primarily, the massive incorporation of synthetic data substantially boosts model performance in both intra- and cross-dataset scenarios. We examine three distinct methodologies for generating synthetic data: template-based generation, character permutation, and utilizing a Generative Adversarial Network (GAN) model, each contributing significantly to performance enhancement. The combined use of these methodologies demonstrates a notable synergistic effect, leading to end-to-end results that surpass those reached by state-of-the-art methods and established commercial systems. Our experiments also underscore the efficacy of synthetic data in mitigating challenges posed by limited training data, enabling remarkable results to be achieved even with small fractions of the original training data. Finally, we investigate the trade-off between accuracy and speed among different models, identifying those that strike the optimal balance in each intra-dataset and cross-dataset settings.
Toward Advancing License Plate Super-Resolution in Real-World Scenarios: A Dataset and Benchmark
May 09, 2025Recent advancements in super-resolution for License Plate Recognition (LPR) have sought to address challenges posed by low-resolution (LR) and degraded images in surveillance, traffic monitoring, and forensic applications. However, existing studies have relied on private datasets and simplistic degradation models. To address this gap, we introduce UFPR-SR-Plates, a novel dataset containing 10,000 tracks with 100,000 paired low and high-resolution license plate images captured under real-world conditions. We establish a benchmark using multiple sequential LR and high-resolution (HR) images per vehicle -- five of each -- and two state-of-the-art models for super-resolution of license plates. We also investigate three fusion strategies to evaluate how combining predictions from a leading Optical Character Recognition (OCR) model for multiple super-resolved license plates enhances overall performance. Our findings demonstrate that super-resolution significantly boosts LPR performance, with further improvements observed when applying majority vote-based fusion techniques. Specifically, the Layout-Aware and Character-Driven Network (LCDNet) model combined with the Majority Vote by Character Position (MVCP) strategy led to the highest recognition rates, increasing from 1.7% with low-resolution images to 31.1% with super-resolution, and up to 44.7% when combining OCR outputs from five super-resolved images. These findings underscore the critical role of super-resolution and temporal information in enhancing LPR accuracy under real-world, adverse conditions. The proposed dataset is publicly available to support further research and can be accessed at: https://valfride.github.io/nascimento2024toward/
Improving Small Drone Detection Through Multi-Scale Processing and Data Augmentation
Apr 27, 2025


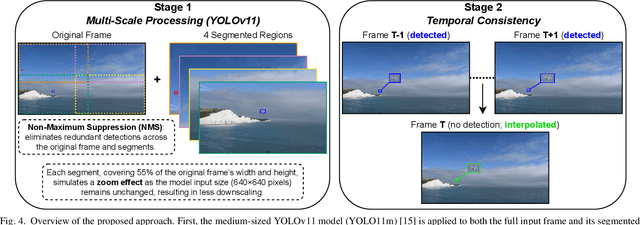
Detecting small drones, often indistinguishable from birds, is crucial for modern surveillance. This work introduces a drone detection methodology built upon the medium-sized YOLOv11 object detection model. To enhance its performance on small targets, we implemented a multi-scale approach in which the input image is processed both as a whole and in segmented parts, with subsequent prediction aggregation. We also utilized a copy-paste data augmentation technique to enrich the training dataset with diverse drone and bird examples. Finally, we implemented a post-processing technique that leverages frame-to-frame consistency to mitigate missed detections. The proposed approach attained a top-3 ranking in the 8th WOSDETC Drone-vsBird Detection Grand Challenge, held at the 2025 International Joint Conference on Neural Networks (IJCNN), showcasing its capability to detect drones in complex environments effectively.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Watchlist Challenge: 3rd Open-set Face Detection and Identification
Sep 11, 2024In the current landscape of biometrics and surveillance, the ability to accurately recognize faces in uncontrolled settings is paramount. The Watchlist Challenge addresses this critical need by focusing on face detection and open-set identification in real-world surveillance scenarios. This paper presents a comprehensive evaluation of participating algorithms, using the enhanced UnConstrained College Students (UCCS) dataset with new evaluation protocols. In total, four participants submitted four face detection and nine open-set face recognition systems. The evaluation demonstrates that while detection capabilities are generally robust, closed-set identification performance varies significantly, with models pre-trained on large-scale datasets showing superior performance. However, open-set scenarios require further improvement, especially at higher true positive identification rates, i.e., lower thresholds.
Less is more: concatenating videos for Sign Language Translation from a small set of signs
Sep 03, 2024The limited amount of labeled data for training the Brazilian Sign Language (Libras) to Portuguese Translation models is a challenging problem due to video collection and annotation costs. This paper proposes generating sign language content by concatenating short clips containing isolated signals for training Sign Language Translation models. We employ the V-LIBRASIL dataset, composed of 4,089 sign videos for 1,364 signs, interpreted by at least three persons, to create hundreds of thousands of sentences with their respective Libras translation, and then, to feed the model. More specifically, we propose several experiments varying the vocabulary size and sentence structure, generating datasets with approximately 170K, 300K, and 500K videos. Our results achieve meaningful scores of 9.2% and 26.2% for BLEU-4 and METEOR, respectively. Our technique enables the creation or extension of existing datasets at a much lower cost than the collection and annotation of thousands of sentences providing clear directions for future works.