 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMB-FHE: Adaptive Multi-biometric Fusion with Fully Homomorphic Encryption
Mar 31, 2025



Biometric systems strive to balance security and usability. The use of multi-biometric systems combining multiple biometric modalities is usually recommended for high-security applications. However, the presentation of multiple biometric modalities can impair the user-friendliness of the overall system and might not be necessary in all cases. In this work, we present a simple but flexible approach to increase the privacy protection of homomorphically encrypted multi-biometric reference templates while enabling adaptation to security requirements at run-time: An adaptive multi-biometric fusion with fully homomorphic encryption (AMB-FHE). AMB-FHE is benchmarked against a bimodal biometric database consisting of the CASIA iris and MCYT fingerprint datasets using deep neural networks for feature extraction. Our contribution is easy to implement and increases the flexibility of biometric authentication while offering increased privacy protection through joint encryption of templates from multiple modalities.
Deep Learning-based Compression Detection for explainable Face Image Quality Assessment
Jan 07, 2025



The assessment of face image quality is crucial to ensure reliable face recognition. In order to provide data subjects and operators with explainable and actionable feedback regarding captured face images, relevant quality components have to be measured. Quality components that are known to negatively impact the utility of face images include JPEG and JPEG 2000 compression artefacts, among others. Compression can result in a loss of important image details which may impair the recognition performance. In this work, deep neural networks are trained to detect the compression artefacts in a face images. For this purpose, artefact-free facial images are compressed with the JPEG and JPEG 2000 compression algorithms. Subsequently, the PSNR and SSIM metrics are employed to obtain training labels based on which neural networks are trained using a single network to detect JPEG and JPEG 2000 artefacts, respectively. The evaluation of the proposed method shows promising results: in terms of detection accuracy, error rates of 2-3% are obtained for utilizing PSNR labels during training. In addition, we show that error rates of different open-source and commercial face recognition systems can be significantly reduced by discarding face images exhibiting severe compression artefacts. To minimize resource consumption, EfficientNetV2 serves as basis for the presented algorithm, which is available as part of the OFIQ software.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Fairness measures for biometric quality assessment
Aug 21, 2024
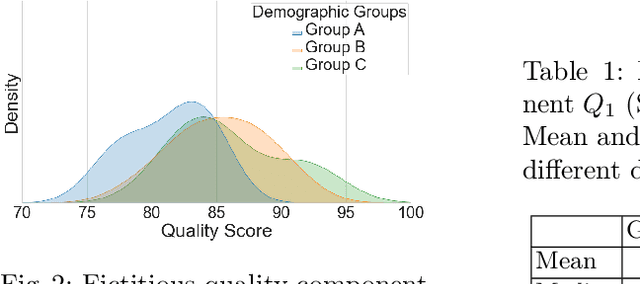


Quality assessment algorithms measure the quality of a captured biometric sample. Since the sample quality strongly affects the recognition performance of a biometric system, it is essential to only process samples of sufficient quality and discard samples of low-quality. Even though quality assessment algorithms are not intended to yield very different quality scores across demographic groups, quality score discrepancies are possible, resulting in different discard ratios. To ensure that quality assessment algorithms do not take demographic characteristics into account when assessing sample quality and consequently to ensure that the quality algorithms perform equally for all individuals, it is crucial to develop a fairness measure. In this work we propose and compare multiple fairness measures for evaluating quality components across demographic groups. Proposed measures, could be used as potential candidates for an upcoming standard in this important field.
Testing the Performance of Face Recognition for People with Down Syndrome
May 18, 2024



The fairness of biometric systems, in particular facial recognition, is often analysed for larger demographic groups, e.g. female vs. male or black vs. white. In contrast to this, minority groups are commonly ignored. This paper investigates the performance of facial recognition algorithms on individuals with Down syndrome, a common chromosomal abnormality that affects approximately one in 1,000 births per year. To do so, a database of 98 individuals with Down syndrome, each represented by at least five facial images, is semi-automatically collected from YouTube. Subsequently, two facial image quality assessment algorithms and five recognition algorithms are evaluated on the newly collected database and on the public facial image databases CelebA and FRGCv2. The results show that the quality scores of facial images for individuals with Down syndrome are comparable to those of individuals without Down syndrome captured under similar conditions. Furthermore, it is observed that face recognition performance decreases significantly for individuals with Down syndrome, which is largely attributed to the increased likelihood of false matches.
TattTRN: Template Reconstruction Network for Tattoo Retrieval
May 13, 2024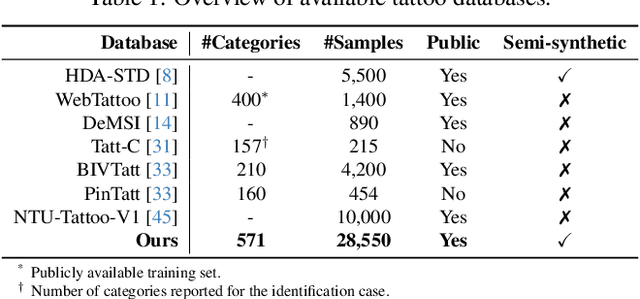
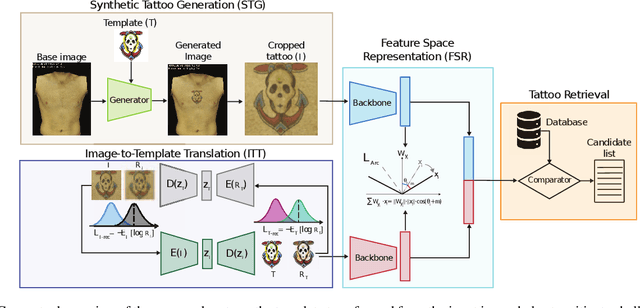

Tattoos have been used effectively as soft biometrics to assist law enforcement in the identification of offenders and victims, as they contain discriminative information, and are a useful indicator to locate members of a criminal gang or organisation. Due to various privacy issues in the acquisition of images containing tattoos, only a limited number of databases exists. This lack of databases has delayed the development of new methods to effectively retrieve a potential suspect's tattoo images from a candidate gallery. To mitigate this issue, in our work, we use an unsupervised generative approach to create a balanced database consisting of 28,550 semi-synthetic images with tattooed subjects from 571 tattoo categories. Further, we introduce a novel Tattoo Template Reconstruction Network (TattTRN), which learns to map the input tattoo sample to its respective tattoo template to enhance the distinguishing attributes of the final feature embedding. Experimental results with real data, i.e., WebTattoo and BIVTatt databases, demonstrate the soundness of the presented approach: an accuracy of up to 99% is achieved for checking at most the first 20 entries of the candidate list.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Synthetic Data for the Mitigation of Demographic Biases in Face Recognition
Feb 02, 2024This study investigates the possibility of mitigating the demographic biases that affect face recognition technologies through the use of synthetic data. Demographic biases have the potential to impact individuals from specific demographic groups, and can be identified by observing disparate performance of face recognition systems across demographic groups. They primarily arise from the unequal representations of demographic groups in the training data. In recent times, synthetic data have emerged as a solution to some problems that affect face recognition systems. In particular, during the generation process it is possible to specify the desired demographic and facial attributes of images, in order to control the demographic distribution of the synthesized dataset, and fairly represent the different demographic groups. We propose to fine-tune with synthetic data existing face recognition systems that present some demographic biases. We use synthetic datasets generated with GANDiffFace, a novel framework able to synthesize datasets for face recognition with controllable demographic distribution and realistic intra-class variations. We consider multiple datasets representing different demographic groups for training and evaluation. Also, we fine-tune different face recognition systems, and evaluate their demographic fairness with different metrics. Our results support the proposed approach and the use of synthetic data to mitigate demographic biases in face recognition.
* 8 pages, 3 figures
Double Trouble? Impact and Detection of Duplicates in Face Image Datasets
Jan 25, 2024Various face image datasets intended for facial biometrics research were created via web-scraping, i.e. the collection of images publicly available on the internet. This work presents an approach to detect both exactly and nearly identical face image duplicates, using file and image hashes. The approach is extended through the use of face image preprocessing. Additional steps based on face recognition and face image quality assessment models reduce false positives, and facilitate the deduplication of the face images both for intra- and inter-subject duplicate sets. The presented approach is applied to five datasets, namely LFW, TinyFace, Adience, CASIA-WebFace, and C-MS-Celeb (a cleaned MS-Celeb-1M variant). Duplicates are detected within every dataset, with hundreds to hundreds of thousands of duplicates for all except LFW. Face recognition and quality assessment experiments indicate a minor impact on the results through the duplicate removal. The final deduplication data is publicly available.
TetraLoss: Improving the Robustness of Face Recognition against Morphing Attacks
Jan 21, 2024



Face recognition systems are widely deployed in high-security applications such as for biometric verification at border controls. Despite their high accuracy on pristine data, it is well-known that digital manipulations, such as face morphing, pose a security threat to face recognition systems. Malicious actors can exploit the facilities offered by the identity document issuance process to obtain identity documents containing morphed images. Thus, subjects who contributed to the creation of the morphed image can with high probability use the identity document to bypass automated face recognition systems. In recent years, no-reference (i.e., single image) and differential morphing attack detectors have been proposed to tackle this risk. These systems are typically evaluated in isolation from the face recognition system that they have to operate jointly with and do not consider the face recognition process. Contrary to most existing works, we present a novel method for adapting deep learning-based face recognition systems to be more robust against face morphing attacks. To this end, we introduce TetraLoss, a novel loss function that learns to separate morphed face images from its contributing subjects in the embedding space while still preserving high biometric verification performance. In a comprehensive evaluation, we show that the proposed method can significantly enhance the original system while also significantly outperforming other tested baseline methods.