 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalScore: Local Density-Aware Similarity Scoring for Biometrics
Feb 01, 2026Open-set biometrics faces challenges with probe subjects who may not be enrolled in the gallery, as traditional biometric systems struggle to detect these non-mated probes. Despite the growing prevalence of multi-sample galleries in real-world deployments, most existing methods collapse intra-subject variability into a single global representation, leading to suboptimal decision boundaries and poor open-set robustness. To address this issue, we propose LocalScore, a simple yet effective scoring algorithm that explicitly incorporates the local density of the gallery feature distribution using the k-th nearest neighbors. LocalScore is architecture-agnostic, loss-independent, and incurs negligible computational overhead, making it a plug-and-play solution for existing biometric systems. Extensive experiments across multiple modalities demonstrate that LocalScore consistently achieves substantial gains in open-set retrieval (FNIR@FPIR reduced from 53% to 40%) and verification (TAR@FAR improved from 51% to 74%). We further provide theoretical analysis and empirical validation explaining when and why the method achieves the most significant gains based on dataset characteristics.
A Quality-Guided Mixture of Score-Fusion Experts Framework for Human Recognition
Jul 31, 2025Whole-body biometric recognition is a challenging multimodal task that integrates various biometric modalities, including face, gait, and body. This integration is essential for overcoming the limitations of unimodal systems. Traditionally, whole-body recognition involves deploying different models to process multiple modalities, achieving the final outcome by score-fusion (e.g., weighted averaging of similarity matrices from each model). However, these conventional methods may overlook the variations in score distributions of individual modalities, making it challenging to improve final performance. In this work, we present \textbf{Q}uality-guided \textbf{M}ixture of score-fusion \textbf{E}xperts (QME), a novel framework designed for improving whole-body biometric recognition performance through a learnable score-fusion strategy using a Mixture of Experts (MoE). We introduce a novel pseudo-quality loss for quality estimation with a modality-specific Quality Estimator (QE), and a score triplet loss to improve the metric performance. Extensive experiments on multiple whole-body biometric datasets demonstrate the effectiveness of our proposed approach, achieving state-of-the-art results across various metrics compared to baseline methods. Our method is effective for multimodal and multi-model, addressing key challenges such as model misalignment in the similarity score domain and variability in data quality.
50 Years of Automated Face Recognition
May 30, 2025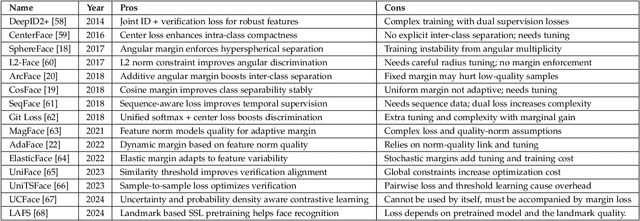

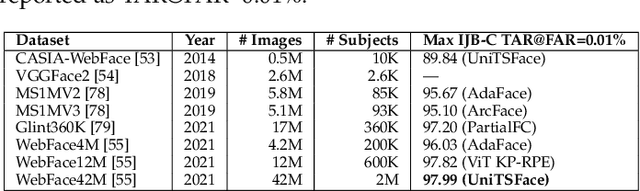

Over the past 50 years, automated face recognition has evolved from rudimentary, handcrafted systems into sophisticated deep learning models that rival and often surpass human performance. This paper chronicles the history and technological progression of FR, from early geometric and statistical methods to modern deep neural architectures leveraging massive real and AI-generated datasets. We examine key innovations that have shaped the field, including developments in dataset, loss function, neural network design and feature fusion. We also analyze how the scale and diversity of training data influence model generalization, drawing connections between dataset growth and benchmark improvements. Recent advances have achieved remarkable milestones: state-of-the-art face verification systems now report False Negative Identification Rates of 0.13% against a 12.4 million gallery in NIST FRVT evaluations for 1:N visa-to-border matching. While recent advances have enabled remarkable accuracy in high- and low-quality face scenarios, numerous challenges persist. While remarkable progress has been achieved, several open research problems remain. We outline critical challenges and promising directions for future face recognition research, including scalability, multi-modal fusion, synthetic identity generation, and explainable systems.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025



We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
SapiensID: Foundation for Human Recognition
Apr 07, 2025Existing human recognition systems often rely on separate, specialized models for face and body analysis, limiting their effectiveness in real-world scenarios where pose, visibility, and context vary widely. This paper introduces SapiensID, a unified model that bridges this gap, achieving robust performance across diverse settings. SapiensID introduces (i) Retina Patch (RP), a dynamic patch generation scheme that adapts to subject scale and ensures consistent tokenization of regions of interest, (ii) a masked recognition model (MRM) that learns from variable token length, and (iii) Semantic Attention Head (SAH), an module that learns pose-invariant representations by pooling features around key body parts. To facilitate training, we introduce WebBody4M, a large-scale dataset capturing diverse poses and scale variations. Extensive experiments demonstrate that SapiensID achieves state-of-the-art results on various body ReID benchmarks, outperforming specialized models in both short-term and long-term scenarios while remaining competitive with dedicated face recognition systems. Furthermore, SapiensID establishes a strong baseline for the newly introduced challenge of Cross Pose-Scale ReID, demonstrating its ability to generalize to complex, real-world conditions.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Open-Set Biometrics: Beyond Good Closed-Set Models
Jul 23, 2024Biometric recognition has primarily addressed closed-set identification, assuming all probe subjects are in the gallery. However, most practical applications involve open-set biometrics, where probe subjects may or may not be present in the gallery. This poses distinct challenges in effectively distinguishing individuals in the gallery while minimizing false detections. While it is commonly believed that powerful biometric models can excel in both closed- and open-set scenarios, existing loss functions are inconsistent with open-set evaluation. They treat genuine (mated) and imposter (non-mated) similarity scores symmetrically and neglect the relative magnitudes of imposter scores. To address these issues, we simulate open-set evaluation using minibatches during training and introduce novel loss functions: (1) the identification-detection loss optimized for open-set performance under selective thresholds and (2) relative threshold minimization to reduce the maximum negative score for each probe. Across diverse biometric tasks, including face recognition, gait recognition, and person re-identification, our experiments demonstrate the effectiveness of the proposed loss functions, significantly enhancing open-set performance while positively impacting closed-set performance. Our code and models are available at https://github.com/prevso1088/open-set-biometrics.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
KeyPoint Relative Position Encoding for Face Recognition
Mar 21, 2024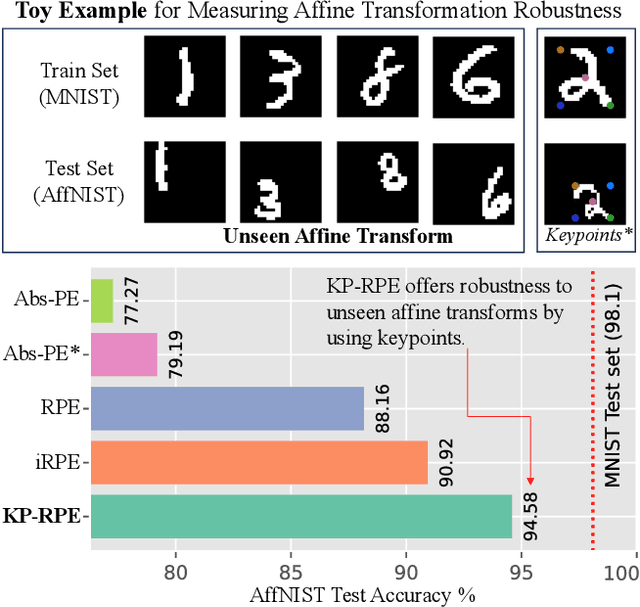

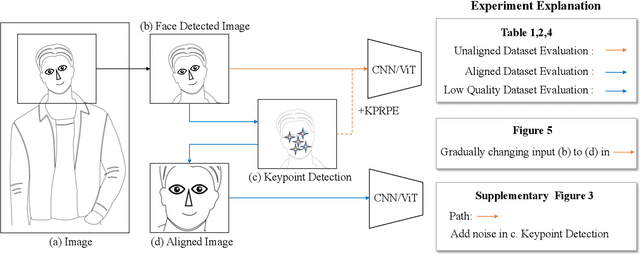
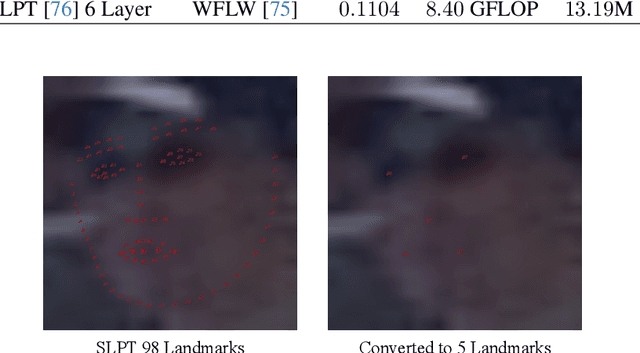
In this paper, we address the challenge of making ViT models more robust to unseen affine transformations. Such robustness becomes useful in various recognition tasks such as face recognition when image alignment failures occur. We propose a novel method called KP-RPE, which leverages key points (e.g.~facial landmarks) to make ViT more resilient to scale, translation, and pose variations. We begin with the observation that Relative Position Encoding (RPE) is a good way to bring affine transform generalization to ViTs. RPE, however, can only inject the model with prior knowledge that nearby pixels are more important than far pixels. Keypoint RPE (KP-RPE) is an extension of this principle, where the significance of pixels is not solely dictated by their proximity but also by their relative positions to specific keypoints within the image. By anchoring the significance of pixels around keypoints, the model can more effectively retain spatial relationships, even when those relationships are disrupted by affine transformations. We show the merit of KP-RPE in face and gait recognition. The experimental results demonstrate the effectiveness in improving face recognition performance from low-quality images, particularly where alignment is prone to failure. Code and pre-trained models are available.
Token Fusion: Bridging the Gap between Token Pruning and Token Merging
Dec 02, 2023



Vision Transformers (ViTs) have emerged as powerful backbones in computer vision, outperforming many traditional CNNs. However, their computational overhead, largely attributed to the self-attention mechanism, makes deployment on resource-constrained edge devices challenging. Multiple solutions rely on token pruning or token merging. In this paper, we introduce "Token Fusion" (ToFu), a method that amalgamates the benefits of both token pruning and token merging. Token pruning proves advantageous when the model exhibits sensitivity to input interpolations, while token merging is effective when the model manifests close to linear responses to inputs. We combine this to propose a new scheme called Token Fusion. Moreover, we tackle the limitations of average merging, which doesn't preserve the intrinsic feature norm, resulting in distributional shifts. To mitigate this, we introduce MLERP merging, a variant of the SLERP technique, tailored to merge multiple tokens while maintaining the norm distribution. ToFu is versatile, applicable to ViTs with or without additional training. Our empirical evaluations indicate that ToFu establishes new benchmarks in both classification and image generation tasks concerning computational efficiency and model accuracy.