 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionAgent: A Multimodal Agent with Dynamic Model Selection for Human Recognition
Mar 27, 2026Model fusion is a key strategy for robust recognition in unconstrained scenarios, as different models provide complementary strengths. This is especially important for whole-body human recognition, where biometric cues such as face, gait, and body shape vary across samples and are typically integrated via score-fusion. However, existing score-fusion strategies are usually static, invoking all models for every test sample regardless of sample quality or modality reliability. To overcome these limitations, we propose \textbf{FusionAgent}, a novel agentic framework that leverages a Multimodal Large Language Model (MLLM) to perform dynamic, sample-specific model selection. Each expert model is treated as a tool, and through Reinforcement Fine-Tuning (RFT) with a metric-based reward, the agent learns to adaptively determine the optimal model combination for each test input. To address the model score misalignment and embedding heterogeneity, we introduce Anchor-based Confidence Top-k (ACT) score-fusion, which anchors on the most confident model and integrates complementary predictions in a confidence-aware manner. Extensive experiments on multiple whole-body biometric benchmarks demonstrate that FusionAgent significantly outperforms SoTA methods while achieving higher efficiency through fewer model invocations, underscoring the critical role of dynamic, explainable, and robust model fusion in real-world recognition systems. Project page: \href{https://fusionagent.github.io/}{FusionAgent}.
LocalScore: Local Density-Aware Similarity Scoring for Biometrics
Feb 01, 2026Open-set biometrics faces challenges with probe subjects who may not be enrolled in the gallery, as traditional biometric systems struggle to detect these non-mated probes. Despite the growing prevalence of multi-sample galleries in real-world deployments, most existing methods collapse intra-subject variability into a single global representation, leading to suboptimal decision boundaries and poor open-set robustness. To address this issue, we propose LocalScore, a simple yet effective scoring algorithm that explicitly incorporates the local density of the gallery feature distribution using the k-th nearest neighbors. LocalScore is architecture-agnostic, loss-independent, and incurs negligible computational overhead, making it a plug-and-play solution for existing biometric systems. Extensive experiments across multiple modalities demonstrate that LocalScore consistently achieves substantial gains in open-set retrieval (FNIR@FPIR reduced from 53% to 40%) and verification (TAR@FAR improved from 51% to 74%). We further provide theoretical analysis and empirical validation explaining when and why the method achieves the most significant gains based on dataset characteristics.
On the Holistic Approach for Detecting Human Image Forgery
Jan 08, 2026The rapid advancement of AI-generated content (AIGC) has escalated the threat of deepfakes, from facial manipulations to the synthesis of entire photorealistic human bodies. However, existing detection methods remain fragmented, specializing either in facial-region forgeries or full-body synthetic images, and consequently fail to generalize across the full spectrum of human image manipulations. We introduce HuForDet, a holistic framework for human image forgery detection, which features a dual-branch architecture comprising: (1) a face forgery detection branch that employs heterogeneous experts operating in both RGB and frequency domains, including an adaptive Laplacian-of-Gaussian (LoG) module designed to capture artifacts ranging from fine-grained blending boundaries to coarse-scale texture irregularities; and (2) a contextualized forgery detection branch that leverages a Multi-Modal Large Language Model (MLLM) to analyze full-body semantic consistency, enhanced with a confidence estimation mechanism that dynamically weights its contribution during feature fusion. We curate a human image forgery (HuFor) dataset that unifies existing face forgery data with a new corpus of full-body synthetic humans. Extensive experiments show that our HuForDet achieves state-of-the-art forgery detection performance and superior robustness across diverse human image forgeries.
A Quality-Guided Mixture of Score-Fusion Experts Framework for Human Recognition
Jul 31, 2025Whole-body biometric recognition is a challenging multimodal task that integrates various biometric modalities, including face, gait, and body. This integration is essential for overcoming the limitations of unimodal systems. Traditionally, whole-body recognition involves deploying different models to process multiple modalities, achieving the final outcome by score-fusion (e.g., weighted averaging of similarity matrices from each model). However, these conventional methods may overlook the variations in score distributions of individual modalities, making it challenging to improve final performance. In this work, we present \textbf{Q}uality-guided \textbf{M}ixture of score-fusion \textbf{E}xperts (QME), a novel framework designed for improving whole-body biometric recognition performance through a learnable score-fusion strategy using a Mixture of Experts (MoE). We introduce a novel pseudo-quality loss for quality estimation with a modality-specific Quality Estimator (QE), and a score triplet loss to improve the metric performance. Extensive experiments on multiple whole-body biometric datasets demonstrate the effectiveness of our proposed approach, achieving state-of-the-art results across various metrics compared to baseline methods. Our method is effective for multimodal and multi-model, addressing key challenges such as model misalignment in the similarity score domain and variability in data quality.
50 Years of Automated Face Recognition
May 30, 2025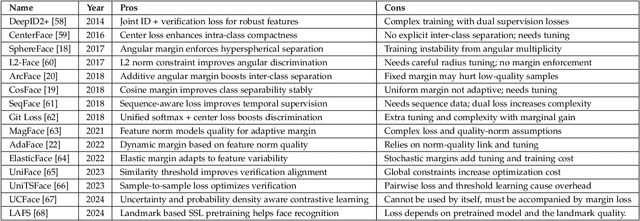

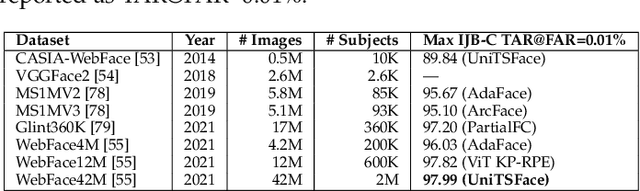

Over the past 50 years, automated face recognition has evolved from rudimentary, handcrafted systems into sophisticated deep learning models that rival and often surpass human performance. This paper chronicles the history and technological progression of FR, from early geometric and statistical methods to modern deep neural architectures leveraging massive real and AI-generated datasets. We examine key innovations that have shaped the field, including developments in dataset, loss function, neural network design and feature fusion. We also analyze how the scale and diversity of training data influence model generalization, drawing connections between dataset growth and benchmark improvements. Recent advances have achieved remarkable milestones: state-of-the-art face verification systems now report False Negative Identification Rates of 0.13% against a 12.4 million gallery in NIST FRVT evaluations for 1:N visa-to-border matching. While recent advances have enabled remarkable accuracy in high- and low-quality face scenarios, numerous challenges persist. While remarkable progress has been achieved, several open research problems remain. We outline critical challenges and promising directions for future face recognition research, including scalability, multi-modal fusion, synthetic identity generation, and explainable systems.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025



We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Adversarial Watermarking for Face Recognition
Sep 24, 2024Watermarking is an essential technique for embedding an identifier (i.e., watermark message) within digital images to assert ownership and monitor unauthorized alterations. In face recognition systems, watermarking plays a pivotal role in ensuring data integrity and security. However, an adversary could potentially interfere with the watermarking process, significantly impairing recognition performance. We explore the interaction between watermarking and adversarial attacks on face recognition models. Our findings reveal that while watermarking or input-level perturbation alone may have a negligible effect on recognition accuracy, the combined effect of watermarking and perturbation can result in an adversarial watermarking attack, significantly degrading recognition performance. Specifically, we introduce a novel threat model, the adversarial watermarking attack, which remains stealthy in the absence of watermarking, allowing images to be correctly recognized initially. However, once watermarking is applied, the attack is activated, causing recognition failures. Our study reveals a previously unrecognized vulnerability: adversarial perturbations can exploit the watermark message to evade face recognition systems. Evaluated on the CASIA-WebFace dataset, our proposed adversarial watermarking attack reduces face matching accuracy by 67.2% with an $\ell_\infty$ norm-measured perturbation strength of ${2}/{255}$ and by 95.9% with a strength of ${4}/{255}$.
Data Pruning via Separability, Integrity, and Model Uncertainty-Aware Importance Sampling
Sep 20, 2024



This paper improves upon existing data pruning methods for image classification by introducing a novel pruning metric and pruning procedure based on importance sampling. The proposed pruning metric explicitly accounts for data separability, data integrity, and model uncertainty, while the sampling procedure is adaptive to the pruning ratio and considers both intra-class and inter-class separation to further enhance the effectiveness of pruning. Furthermore, the sampling method can readily be applied to other pruning metrics to improve their performance. Overall, the proposed approach scales well to high pruning ratio and generalizes better across different classification models, as demonstrated by experiments on four benchmark datasets, including the fine-grained classification scenario.
On Missing Scores in Evolving Multibiometric Systems
Aug 21, 2024



The use of multiple modalities (e.g., face and fingerprint) or multiple algorithms (e.g., three face comparators) has shown to improve the recognition accuracy of an operational biometric system. Over time a biometric system may evolve to add new modalities, retire old modalities, or be merged with other biometric systems. This can lead to scenarios where there are missing scores corresponding to the input probe set. Previous work on this topic has focused on either the verification or identification tasks, but not both. Further, the proportion of missing data considered has been less than 50%. In this work, we study the impact of missing score data for both the verification and identification tasks. We show that the application of various score imputation methods along with simple sum fusion can improve recognition accuracy, even when the proportion of missing scores increases to 90%. Experiments show that fusion after score imputation outperforms fusion with no imputation. Specifically, iterative imputation with K nearest neighbors consistently surpasses other imputation methods in both the verification and identification tasks, regardless of the amount of scores missing, and provides imputed values that are consistent with the ground truth complete dataset.
Open-Set Biometrics: Beyond Good Closed-Set Models
Jul 23, 2024Biometric recognition has primarily addressed closed-set identification, assuming all probe subjects are in the gallery. However, most practical applications involve open-set biometrics, where probe subjects may or may not be present in the gallery. This poses distinct challenges in effectively distinguishing individuals in the gallery while minimizing false detections. While it is commonly believed that powerful biometric models can excel in both closed- and open-set scenarios, existing loss functions are inconsistent with open-set evaluation. They treat genuine (mated) and imposter (non-mated) similarity scores symmetrically and neglect the relative magnitudes of imposter scores. To address these issues, we simulate open-set evaluation using minibatches during training and introduce novel loss functions: (1) the identification-detection loss optimized for open-set performance under selective thresholds and (2) relative threshold minimization to reduce the maximum negative score for each probe. Across diverse biometric tasks, including face recognition, gait recognition, and person re-identification, our experiments demonstrate the effectiveness of the proposed loss functions, significantly enhancing open-set performance while positively impacting closed-set performance. Our code and models are available at https://github.com/prevso1088/open-set-biometrics.