 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiHDR: Iterative HDR Imaging with Arbitrary Number of Exposures
May 29, 2025High dynamic range (HDR) imaging aims to obtain a high-quality HDR image by fusing information from multiple low dynamic range (LDR) images. Numerous learning-based HDR imaging methods have been proposed to achieve this for static and dynamic scenes. However, their architectures are mostly tailored for a fixed number (e.g., three) of inputs and, therefore, cannot apply directly to situations beyond the pre-defined limited scope. To address this issue, we propose a novel framework, iHDR, for iterative fusion, which comprises a ghost-free Dual-input HDR fusion network (DiHDR) and a physics-based domain mapping network (ToneNet). DiHDR leverages a pair of inputs to estimate an intermediate HDR image, while ToneNet maps it back to the nonlinear domain and serves as the reference input for the next pairwise fusion. This process is iteratively executed until all input frames are utilized. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method as compared to existing state-of-the-art HDR deghosting approaches given flexible numbers of input frames.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025



We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Learning Phase Distortion with Selective State Space Models for Video Turbulence Mitigation
Apr 03, 2025Atmospheric turbulence is a major source of image degradation in long-range imaging systems. Although numerous deep learning-based turbulence mitigation (TM) methods have been proposed, many are slow, memory-hungry, and do not generalize well. In the spatial domain, methods based on convolutional operators have a limited receptive field, so they cannot handle a large spatial dependency required by turbulence. In the temporal domain, methods relying on self-attention can, in theory, leverage the lucky effects of turbulence, but their quadratic complexity makes it difficult to scale to many frames. Traditional recurrent aggregation methods face parallelization challenges. In this paper, we present a new TM method based on two concepts: (1) A turbulence mitigation network based on the Selective State Space Model (MambaTM). MambaTM provides a global receptive field in each layer across spatial and temporal dimensions while maintaining linear computational complexity. (2) Learned Latent Phase Distortion (LPD). LPD guides the state space model. Unlike classical Zernike-based representations of phase distortion, the new LPD map uniquely captures the actual effects of turbulence, significantly improving the model's capability to estimate degradation by reducing the ill-posedness. Our proposed method exceeds current state-of-the-art networks on various synthetic and real-world TM benchmarks with significantly faster inference speed. The code is available at http://github.com/xg416/MambaTM.
Personalized Generative Low-light Image Denoising and Enhancement
Dec 18, 2024While smartphone cameras today can produce astonishingly good photos, their performance in low light is still not completely satisfactory because of the fundamental limits in photon shot noise and sensor read noise. Generative image restoration methods have demonstrated promising results compared to traditional methods, but they suffer from hallucinatory content generation when the signal-to-noise ratio (SNR) is low. Recognizing the availability of personalized photo galleries on users' smartphones, we propose Personalized Generative Denoising (PGD) by building a diffusion model customized for different users. Our core innovation is an identity-consistent physical buffer that extracts the physical attributes of the person from the gallery. This ID-consistent physical buffer provides a strong prior that can be integrated with the diffusion model to restore the degraded images, without the need of fine-tuning. Over a wide range of low-light testing scenarios, we show that PGD achieves superior image denoising and enhancement performance compared to existing diffusion-based denoising approaches.
Generative Photography: Scene-Consistent Camera Control for Realistic Text-to-Image Synthesis
Dec 03, 2024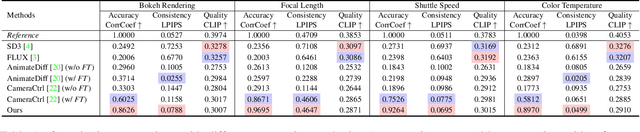



Image generation today can produce somewhat realistic images from text prompts. However, if one asks the generator to synthesize a particular camera setting such as creating different fields of view using a 24mm lens versus a 70mm lens, the generator will not be able to interpret and generate scene-consistent images. This limitation not only hinders the adoption of generative tools in photography applications but also exemplifies a broader issue of bridging the gap between the data-driven models and the physical world. In this paper, we introduce the concept of Generative Photography, a framework designed to control camera intrinsic settings during content generation. The core innovation of this work are the concepts of Dimensionality Lifting and Contrastive Camera Learning, which achieve continuous and consistent transitions for different camera settings. Experimental results show that our method produces significantly more scene-consistent photorealistic images than state-of-the-art models such as Stable Diffusion 3 and FLUX.
Source-free Domain Adaptation for Video Object Detection Under Adverse Image Conditions
Apr 23, 2024When deploying pre-trained video object detectors in real-world scenarios, the domain gap between training and testing data caused by adverse image conditions often leads to performance degradation. Addressing this issue becomes particularly challenging when only the pre-trained model and degraded videos are available. Although various source-free domain adaptation (SFDA) methods have been proposed for single-frame object detectors, SFDA for video object detection (VOD) remains unexplored. Moreover, most unsupervised domain adaptation works for object detection rely on two-stage detectors, while SFDA for one-stage detectors, which are more vulnerable to fine-tuning, is not well addressed in the literature. In this paper, we propose Spatial-Temporal Alternate Refinement with Mean Teacher (STAR-MT), a simple yet effective SFDA method for VOD. Specifically, we aim to improve the performance of the one-stage VOD method, YOLOV, under adverse image conditions, including noise, air turbulence, and haze. Extensive experiments on the ImageNetVOD dataset and its degraded versions demonstrate that our method consistently improves video object detection performance in challenging imaging conditions, showcasing its potential for real-world applications.
Spatio-Temporal Turbulence Mitigation: A Translational Perspective
Jan 08, 2024Recovering images distorted by atmospheric turbulence is a challenging inverse problem due to the stochastic nature of turbulence. Although numerous turbulence mitigation (TM) algorithms have been proposed, their efficiency and generalization to real-world dynamic scenarios remain severely limited. Building upon the intuitions of classical TM algorithms, we present the Deep Atmospheric TUrbulence Mitigation network (DATUM). DATUM aims to overcome major challenges when transitioning from classical to deep learning approaches. By carefully integrating the merits of classical multi-frame TM methods into a deep network structure, we demonstrate that DATUM can efficiently perform long-range temporal aggregation using a recurrent fashion, while deformable attention and temporal-channel attention seamlessly facilitate pixel registration and lucky imaging. With additional supervision, tilt and blur degradation can be jointly mitigated. These inductive biases empower DATUM to significantly outperform existing methods while delivering a tenfold increase in processing speed. A large-scale training dataset, ATSyn, is presented as a co-invention to enable generalization in real turbulence. Our code and datasets will be available at \href{https://xg416.github.io/DATUM}{\textcolor{pink}{https://xg416.github.io/DATUM}}
Physics-Driven Turbulence Image Restoration with Stochastic Refinement
Jul 20, 2023



Image distortion by atmospheric turbulence is a stochastic degradation, which is a critical problem in long-range optical imaging systems. A number of research has been conducted during the past decades, including model-based and emerging deep-learning solutions with the help of synthetic data. Although fast and physics-grounded simulation tools have been introduced to help the deep-learning models adapt to real-world turbulence conditions recently, the training of such models only relies on the synthetic data and ground truth pairs. This paper proposes the Physics-integrated Restoration Network (PiRN) to bring the physics-based simulator directly into the training process to help the network to disentangle the stochasticity from the degradation and the underlying image. Furthermore, to overcome the ``average effect" introduced by deterministic models and the domain gap between the synthetic and real-world degradation, we further introduce PiRN with Stochastic Refinement (PiRN-SR) to boost its perceptual quality. Overall, our PiRN and PiRN-SR improve the generalization to real-world unknown turbulence conditions and provide a state-of-the-art restoration in both pixel-wise accuracy and perceptual quality. Our codes are available at \url{https://github.com/VITA-Group/PiRN}.
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023



Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
HDR Imaging with Spatially Varying Signal-to-Noise Ratios
Apr 16, 2023



While today's high dynamic range (HDR) image fusion algorithms are capable of blending multiple exposures, the acquisition is often controlled so that the dynamic range within one exposure is narrow. For HDR imaging in photon-limited situations, the dynamic range can be enormous and the noise within one exposure is spatially varying. Existing image denoising algorithms and HDR fusion algorithms both fail to handle this situation, leading to severe limitations in low-light HDR imaging. This paper presents two contributions. Firstly, we identify the source of the problem. We find that the issue is associated with the co-existence of (1) spatially varying signal-to-noise ratio, especially the excessive noise due to very dark regions, and (2) a wide luminance range within each exposure. We show that while the issue can be handled by a bank of denoisers, the complexity is high. Secondly, we propose a new method called the spatially varying high dynamic range (SV-HDR) fusion network to simultaneously denoise and fuse images. We introduce a new exposure-shared block within our custom-designed multi-scale transformer framework. In a variety of testing conditions, the performance of the proposed SV-HDR is better than the existing methods.